Capítulo 18 Secuencias de Datos
18.1 Introducción
En geología es común recolectar datos en función del tiempo o espacio (proxy para el tiempo), donde los datos pueden presentarse de forma continua (equidistantes, mediciones a intervalos definidos) o simplemente cuando se observa cierto fenómeno o evento. Estos datos, en cualquiera de las dos formas, se consideran como secuencias de datos, donde una variable es la posición (tiempo o espacio) y la otra variable (interés) es la observación en dicha posición. Ejemplos de estos datos sería: registro de una perforación, secuencia estratigráfica, temperatura, etc.
Dentro de las preguntas que se pueden responder por medio del análisis de secuencias están (en función del tipo de secuencia):
- Los datos son aleatorios o presentan una tendencia o patrón?
- Si hay una tendencia, qué forma tiene?
- Hay periodicidad o ciclos en los datos? Se puede medir?
- Se pueden hacer estimaciones o predicciones a partir de los datos?
Los métodos y técnicas de análisis que se van a presentar y explicar en este capítulo se basan en capítulos de Davis (2002), Swan & Sandilands (1995), Borradaile (2003), y McKillup & Darby Dyar (2010).
18.2 Eventos
Una serie de eventos no es más que una secuencia de intervalos entre ocurrencias, o una longitud acumulada de tiempo (espacio) sobre el cual ocurren los eventos, se registra cuando/donde ocurre el evento. Se pueden considerar como observaciones discretas a lo largo de una secuencia. Estos eventos son distinguibles por cuándo ocurren en el tiempo, se consideran instantáneos, y son tan infrecuentes que dos eventos no ocurren en el mismo intervalo de tiempo.
18.2.1 Prueba de tendencia de intervalos
Esta prueba se usa cuando se desea cuantificar si los intervalos entre eventos (ocurrencia de los eventos) cambian a lo largo de la secuencia.
Para esta prueba se usa la correlación de Spearman (16.5.4), y las hipótesis serían las siguientes:
- \(H_0: \rho_s = 0 \to\) No hay tendencia en la longitud de los intervalos
- \(H_1: \rho_s \neq 0 \to\) Hay una tendencia en la longitud de los intervalos de acortarse o alargarse.
La ecuación para la correlación de Spearman se modifica conforme la Ecuación (18.1), donde \(i\) es el número de intervalo, \(h_i\) es la longitud del intervalo, y \(N\) es el total de intervalos o total de eventos menos 1.
\[\begin{equation} r_{s} = 1 - \frac{6\sum_i^N[i-R(h_i)]^2}{N(N^2-1)} \tag{18.1} \end{equation}\]
Esta prueba se demuestra con un ejemplo de Swan & Sandilands (1995), donde se tiene una secuencia de 45 m de carbonatos en la cual se observaron horizontes de toba a las siguientes distancias de la base: 0.5, 2.3, 3.2, 4.2, 4.9, 7, 11.4, 12.7, 14.6, 16, 21.5, 22.5, 25.8, 30.3, 31.9, 36.2, 42.8. Presenta la secuencia una tendencia? Los datos se muestran en la Tabla 18.1.
toba = c(0.5, 2.3, 3.2, 4.2, 4.9, 7, 11.4, 12.7, 14.6,
16, 21.5, 22.5, 25.8, 30.3, 31.9, 36.2, 42.8)
Toba = tibble(i = 1:(length(toba)-1),
h = diff(toba)) %>%
mutate(Rh = rank(h),
Dif = (i-Rh)^2)| Número (i) | Intervalo (h) | \(R(h_{i})\) | \((i-R(h_{i}))^2\) |
|---|---|---|---|
| 1 | 1.8 | 8.0 | 49.00 |
| 2 | 0.9 | 2.0 | 0.00 |
| 3 | 1.0 | 3.5 | 0.25 |
| 4 | 0.7 | 1.0 | 9.00 |
| 5 | 2.1 | 10.0 | 25.00 |
| 6 | 4.4 | 13.0 | 49.00 |
| 7 | 1.3 | 5.0 | 4.00 |
| 8 | 1.9 | 9.0 | 1.00 |
| 9 | 1.4 | 6.0 | 9.00 |
| 10 | 5.5 | 15.0 | 25.00 |
| 11 | 1.0 | 3.5 | 56.25 |
| 12 | 3.3 | 11.0 | 1.00 |
| 13 | 4.5 | 14.0 | 1.00 |
| 14 | 1.6 | 7.0 | 49.00 |
| 15 | 4.3 | 12.0 | 9.00 |
| 16 | 6.6 | 16.0 | 0.00 |
La suma de las diferencias al cuadrado resulta en:
Toba %>%
summarise(Suma = sum(Dif))## # A tibble: 1 x 1
## Suma
## <dbl>
## 1 288.\[\begin{equation} r_{s} = 1 - \frac{6\sum_i^N[i-R(h_i)]^2}{N(N^2-1)}\\ r_{s} = 1 - \frac{6 \cdot 287.5}{16(16^2-1)} = .577 \end{equation}\]
En R se tiene la función cor.test, donde para obtener más información (prueba \(t\), intervalos de confianza) se puede realizar la correlación de Pearson sobre los datos ranqueados. Otra función que brinda el coeficiente de correlación y su intervalo de confianza es SpearmanRho del paquete DescTools (Signorell, 2020).
a = .05
tend.spearman = cor.test(~i+Rh,Toba,method='pearson',conf.level=1-a)
tend.spearman##
## Pearson's product-moment correlation
##
## data: i and Rh
## t = 2.6426, df = 14, p-value = 0.01931
## alternative hypothesis: true correlation is not equal to 0
## 95 percent confidence interval:
## 0.1137061 0.8340788
## sample estimates:
## cor
## 0.5768949with(Toba,SpearmanRho(i,Rh,conf.level = 1-a))## rho lwr.ci upr.ci
## 0.5768949 0.1137061 0.8340788La relación se puede visualizar por medio de un gráfico de dispersión, que para el caso del ejemplo se muestra en la Figura 18.1.
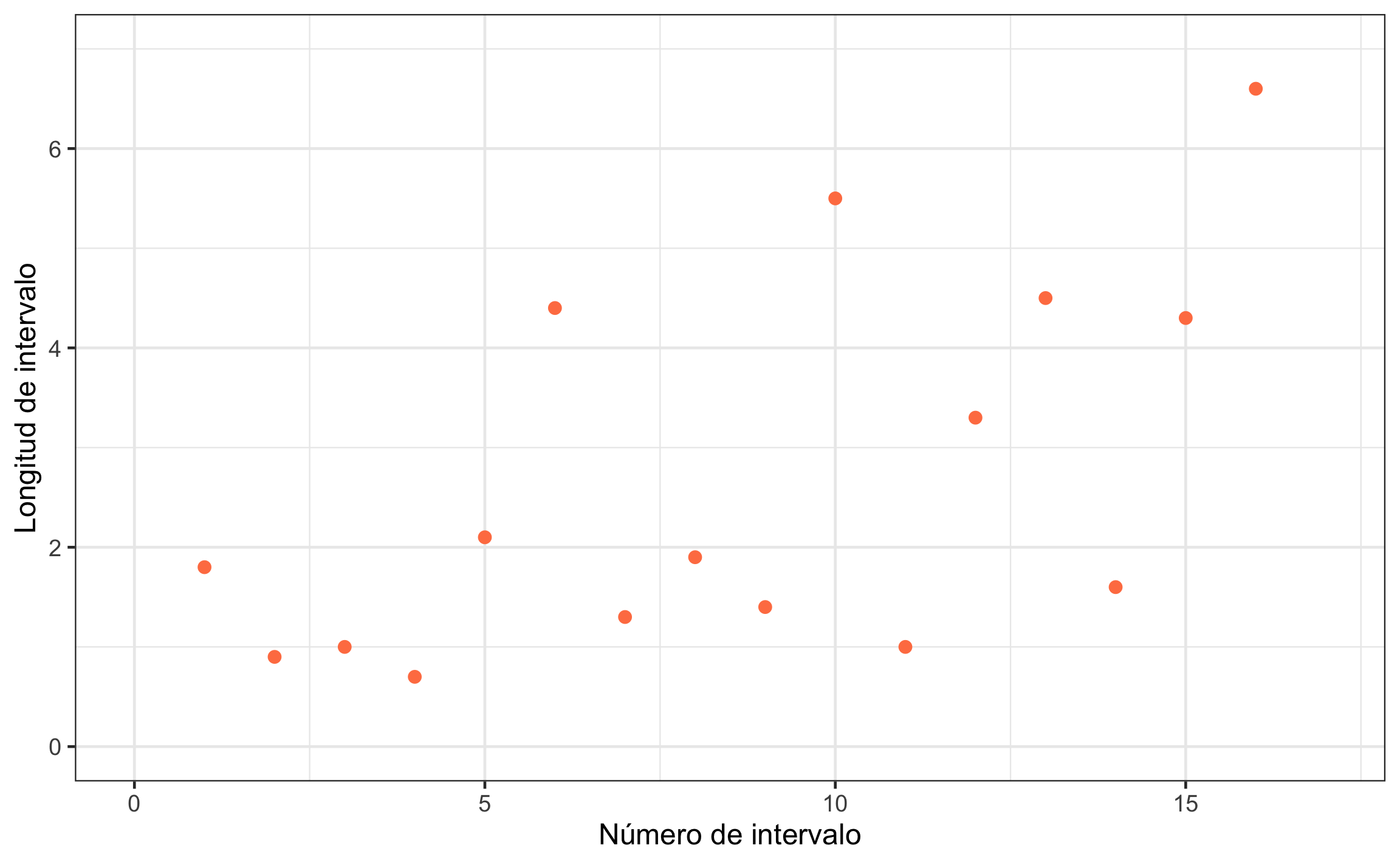
Figura 18.1: Gráfico de dispersión mostrando la relación entre el número de intervalo y la longitud del mismo.
Conclusión: Hay una relación entre la longitud del intervalo y el tiempo (distancia) donde los intervalos tienden a incrementar con el tiempo, \(r_s = .577\), 95% IC \([.11, .83]\), \(p = .019\). El tamaño del efecto es grande con un rango amplio de pequeño hasta muy grande.
18.2.2 Prueba de corridas (rachas)
Esta prueba se usa cuando se quiere determinar la presencia o no de patrones en una secuencia. Para esta prueba se requiere que la secuencia consista en dos estados (categorías, niveles) mutuamente excluyentes (secuencia dicotómica). La secuencia puede haberse registrado en esta forma o se puede transformar de diferentes maneras.
Para demostrar cómo se determinan las corridas o rachas se puede usar el ejemplo de lanzar una moneda 20 veces y se registra si cae ‘Escudo (E)’ o ‘Corona (C)’, donde se obtienen los siguientes resultados: CCCECECCCECECEECCEEE.
Las corridas consisten en grupos de observaciones consecutivas del mismo estado o categoría. Para el caso del ejemplo se tendría: CCC E C E CCC E C E C EE CC EEE, dando como resultado 12 corridas, lo que se denomina como \(U\). La cantidad de observaciones de la primer y segunda categorías se denominan \(n_1\) y \(n_2\) respectivamente.
La idea de la prueba es comparar lo observado (\(U, \ n_1, \ n_2\)) con una secuencia aleatoria que no tiene patrón, donde el número promedio de corridas esperado está dado por la Ecuación (18.2), la varianza esperada está dada por la Ecuación (18.3), y la significancia se puede evaluar por medio de una aproximación a la distribución normal estándar conforme la Ecuación (18.4). Resultados significativos se obtendrían cuando se tiene ya sea una gran cantidad de corridas (cambios más frecuentes) o un número de corridas muy bajo.
Las hipótesis para esta prueba serían las siguientes:
- \(H_0: U = \bar{U} \to\) La secuencia es aleatoria
- \(H_1: U \neq \bar{U} \to\) La secuencia no es aleatoria, hay un patrón
\[\begin{equation} \bar{U} = \frac{2n_1n_2}{n_1+n_2}+1 \tag{18.2} \end{equation}\]
\[\begin{equation} \sigma^2_{\bar{U}} = \frac{2n_1n_2(2n_1n_2-n_1-n_2)}{(n_1+n_2)^2(n_1+n_2-1)} \tag{18.3} \end{equation}\]
\[\begin{equation} Z = \frac{U-\bar{U}}{\sigma_{\bar{U}}} \tag{18.4} \end{equation}\]
Aplicando la prueba de corridas al ejemplo del lanzamiento de la moneda se tiene \(U=12\), \(n_1=11\) y \(n_1=9\).
\[\begin{equation} \bar{U} = \frac{2n_1n_2}{n_1+n_2}+1\\ \bar{U} = \frac{2 \cdot 11 \cdot 9}{11+9}+1 = 10.9 \end{equation}\]
\[\begin{equation} \sigma^2_{\bar{U}} = \frac{2n_1n_2(2n_1n_2-n_1-n_2)}{(n_1+n_2)^2(n_1+n_2-1)}\\ \sigma^2_{\bar{U}} = \frac{2 \cdot 11 \cdot 9(2 \cdot 11 \cdot 9-11-9)}{(11+9)^2(11+9-1)}=4.6 \end{equation}\]
\[\begin{equation} Z = \frac{U-\bar{U}}{\sigma_{\bar{U}}}\\ Z = \frac{12-10.9}{2.1} = 0.52 \end{equation}\]
El estadístico encontrado es menor al valor crítico de \(z_{\alpha/2}\) que para un \(\alpha=.05\) es de \(\pm 1.96\), por lo que no se rechaza \(H_0\) y se concluye que la secuencia podría ser aleatoria.
En el caso de que se tuviera una secuencia de datos no dicotómicos, ya sea datos continuos u observaciones con más de dos categorías, es necesario dicomotizar la secuencia.
Para el caso de datos continuos se pueden emplear dos estrategias:
- Corridas arriba-abajo: En ésta lo que se hace es determinar cómo cambia una observación con respecto a la anterior (mayor o menor).
- Corridas con respecto a la mediana: Aquí lo que se hace es comparar todas las observaciones con respecto a la mediana, si son mayores o menores.
En ambos casos cuando se presenta hay dos valores consecutivos iguales, la diferencia es 0, se asigna el 0 a la tendencia que traen las corridas. Por ejemplo, si se tiene \(+ + - 0 - + - - 0 +\), el primer cero se asigna como \(-\) para mantener la corrida, mientras que el segundo cero no afecta si se asigna como \(-\) o como \(+\), el número total de corridas quedaría \(U=5\), \(n_{1+}=4\) y \(n_{2-}=6\).
Como ejemplo de corridas arriba-abajo se tienen los datos de espesores de capas consecutivas de caliza en una secuencia del Jurásica Inferior (Swan & Sandilands, 1995): 17, 14, 13, 17, 9, 15, 36, 13, 26, 10, 25, 13, 25, 8, 28, 15, 19, 34, 22.
Se puede hacer el ejercicio de las corridas y contar el número de observaciones en las dos categorías a mano, pero se demuestra en R con la función dichotomy del paquete GMisc (Garnier-Villarreal, 2020), donde se brinda el vector de observaciones y se escoge el criterio de dicotomización. La función básica table hace el conteo de cada categoría.
calizas = c(17, 14, 13, 17, 9, 15, 36, 13, 26,
10, 25, 13, 25, 8, 28, 15, 19, 34, 22)
(calizas.di = dichotomy(calizas, criteria = 'up-down'))## [1] - - + - + + - + - + - + - + - + + -
## Levels: - +table(calizas.di)## calizas.di
## - +
## 9 9Con estos datos se tiene \(U=15\), \(n_1=9\), y \(n_2=9\).
\[\begin{equation} \bar{U} = \frac{2n_1n_2}{n_1+n_2}+1\\ \bar{U} = \frac{2 \cdot 9 \cdot 9}{9+9}+1 = 10 \end{equation}\]
\[\begin{equation} \sigma^2_{\bar{U}} = \frac{2n_1n_2(2n_1n_2-n_1-n_2)}{(n_1+n_2)^2(n_1+n_2-1)}\\ \sigma^2_{\bar{U}} = \frac{2 \cdot 9 \cdot 9(2 \cdot 9 \cdot 9-9-9)}{(9+9)^2(9+9-1)}=4.23 \end{equation}\]
\[\begin{equation} Z = \frac{U-\bar{U}}{\sigma_{\bar{U}}}\\ Z = \frac{15-10}{2.06} = 2.43 \end{equation}\]
La función RunsTest de DescTools realiza la prueba sobre el vector de datos dicotómicos. Los argumentos correct=F y exact=F son necesarios para que los resultados coincidan con los cálculos manuales.
calizas.runs = RunsTest(calizas.di,correct = F,exact = F)
calizas.runs##
## Runs Test for Randomness
##
## data: calizas.di
## z = 2.4296, runs = 15, m = 9, n = 9, p-value = 0.01512
## alternative hypothesis: true number of runs is not equal the expected numberLos resultados se pueden graficar para visualizar el patrón (en caso de existir) con mayor facilidad.
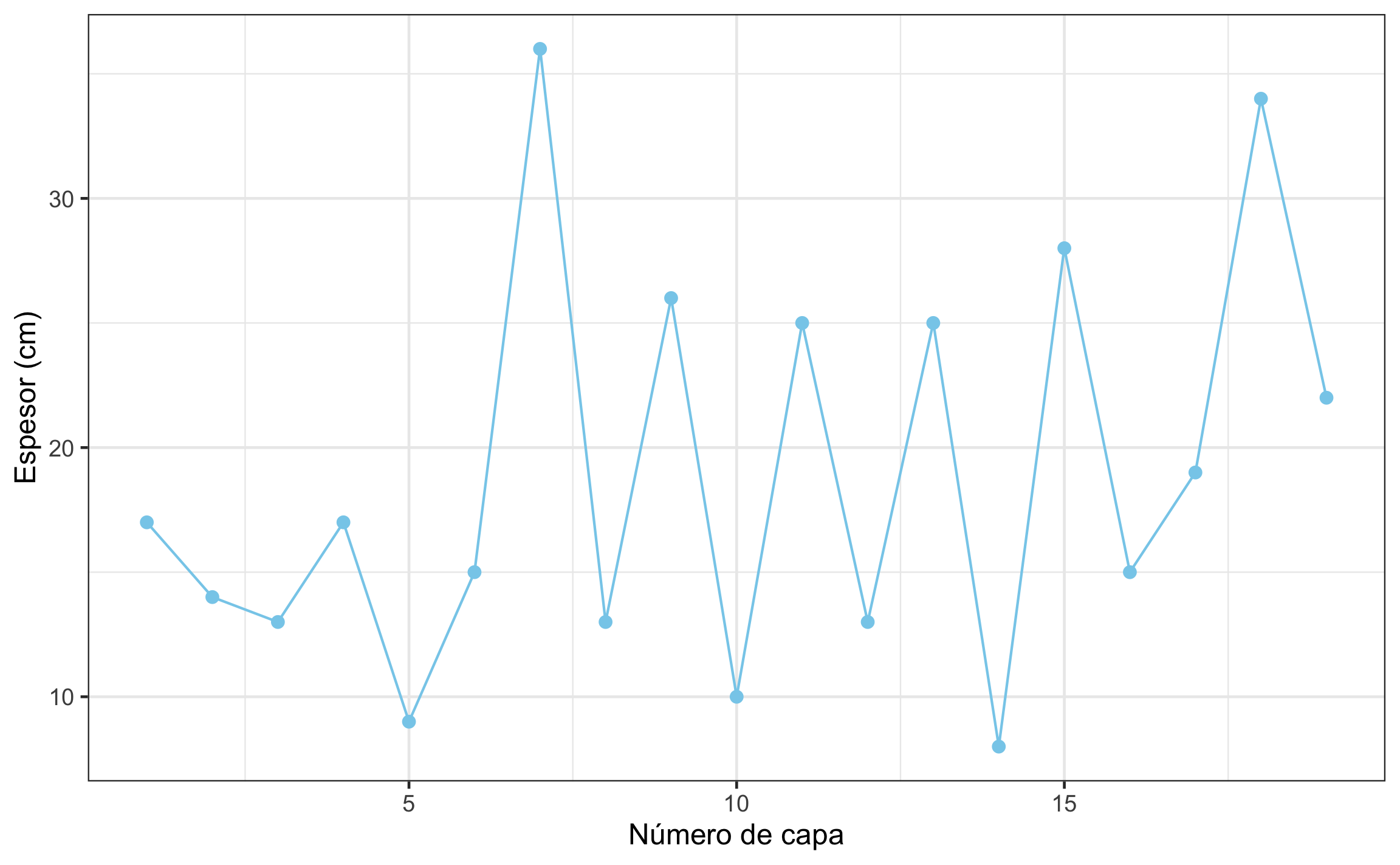
Figura 18.2: Espesor de capas consecutivas de caliza.
Conclusión: El espesor de las calizas no es aleatorio, la gran cantidad de corridas indica una alternancia de capas gruesas y delgadas, \(U = 15, n_1 = 9, n_2 = 9\), \(Z = 2.43\), \(p = .015\).
18.3 Series
Secuencias de series temporales/espaciales son diferentes a las secuencias de eventos, ya que las series se caracterizan por tener \(N\) observaciones espaciadas a un intervalo constante (\(\Delta\)), y la longitud total de la secuencia (\(T\)) se determina como \(T = \Delta(N-1)\).
Estas series pueden analizarse para determinar si dentro de una serie hay ciclos, patrones o tendencias (auto-correlación, 18.3.2), o si dos series presentan similitudes (correlación cruzada, 18.3.3). Dependiendo de la calidad de las observaciones y/o presencia de tendencias, será necesario realizar tratamientos o preparación de los datos antes de los análisis.
18.3.1 Tratamiento de datos
18.3.1.1 Interpolación
En caso de que la serie no cuente con observaciones equidistantes se pueden remover o interpolar valores, haciendo la aclaración y justificación respectiva. De manera general se recomienda realizar interpolaciones entre observaciones cercanas, donde se puede asumir un comportamiento lineal entre ellas, minimizando cualquier artefacto de la interpolación.
18.3.1.2 Filtros
Este es probablemente uno de los pasos de pre-procesamiento más importantes y utilizados. La mayoría de los datos recolectados están compuestos por los datos crudos (“señal”) generados por el proceso geológico de interés, y “ruido” causado por interferencia. El filtrado intenta separar estos dos, resaltando la “señal” sobre el “ruido”. El “ruido” por lo general ocurre a frecuencias altas por lo que tiene efectos inconsistentes en observaciones adyacentes, y se puede reducir si se promedian unas pocas observaciones.
El proceso de filtrado, de manera general, sería el siguiente:
- Se promedia en el punto su valor y valores adyacentes (ventana),
- Si se desea se pueden ponderar (dar pesos) los valores, con los más distantes teniendo menos influencia, a como se muestra de manera general en la Ecuación (18.5),
- Se recomienda usar un número de observaciones impar, para ser simétrico alrededor del punto central (a valorar), donde la cantidad de observaciones a usar va a depender principalmente de la frecuencia de medición.
\[\begin{equation} y_i' = \frac{w_1y_{i-2}+w_2y_{i-1}+w_3y_{i}+w_2y_{i+1}+w_1y_{i+2}}{W} \tag{18.5} \end{equation}\]
donde \(w_i\) corresponden con los diferentes pesos para las observaciones cercanas a la observación central, y \(W\) es la suma de todos los pesos.
Las funciones moving_avg_filter y moving_wt_filter de GMisc permiten filtrar una secuencia de datos usando un promedio aritmético o ponderado, respectivamente. Para graficar los resultados de estas funciones están las funciones moving_filter_plot_f y moving_filter_plot_r, del mismo paquete, que grafican los datos filtrados y los residuales, respectivamente; ambas funciones arrojan un gráfico estático (ggplot2, (Wickham et al., 2020)) y uno dinámico (plotly, (Sievert et al., 2020)).
Para demostrar el filtrado se van a usar datos de Swan & Sandilands (1995) que corresponden con la línea de crecimiento de un nautiloide. Las funciones de filtrado ocupan los vectores de posición (x) y los datos (y), así como la ventana de datos a usar en el promedio. Para el ejemplo se usan ventanas de 3, 5, y 9 datos, y se muestran los datos filtrados (Figuras 18.3 y 18.5) y los residuales (Figuras 18.4 y 18.6) en forma estática ($GGPLOT), para obtener el gráfico dinámico se acceder por medio de $PLOTLY
k = c(3, 5, 9)
filt = moving_avg_filter(nautilus$x, nautilus$y, k)
filt2 = moving_wt_filter(nautilus$x, nautilus$y, k)moving_filter_plot_f(filt)$GGPLOT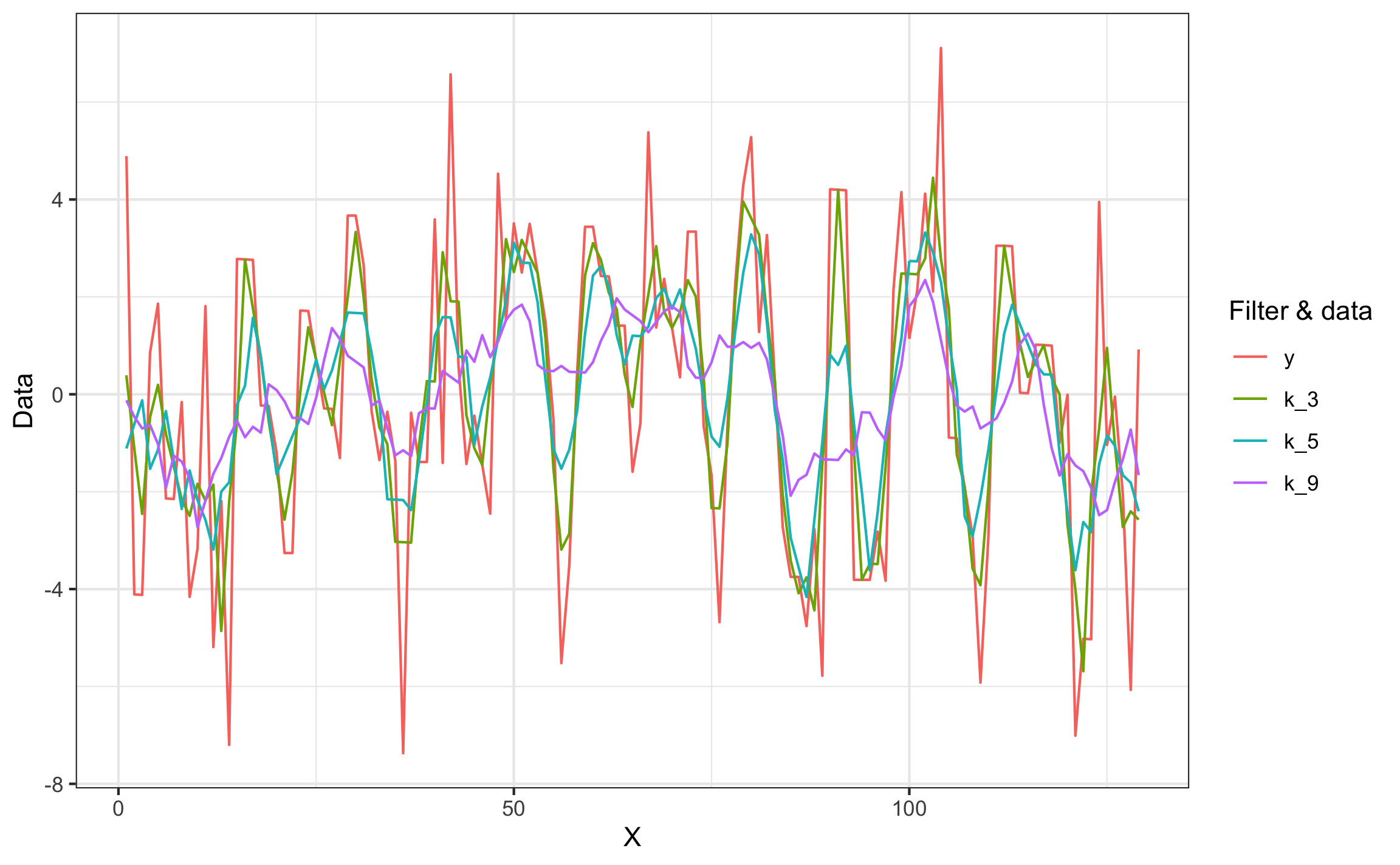
Figura 18.3: Ejemplo de datos crudos y filtrados (sin pesos)
moving_filter_plot_r(filt)$GGPLOT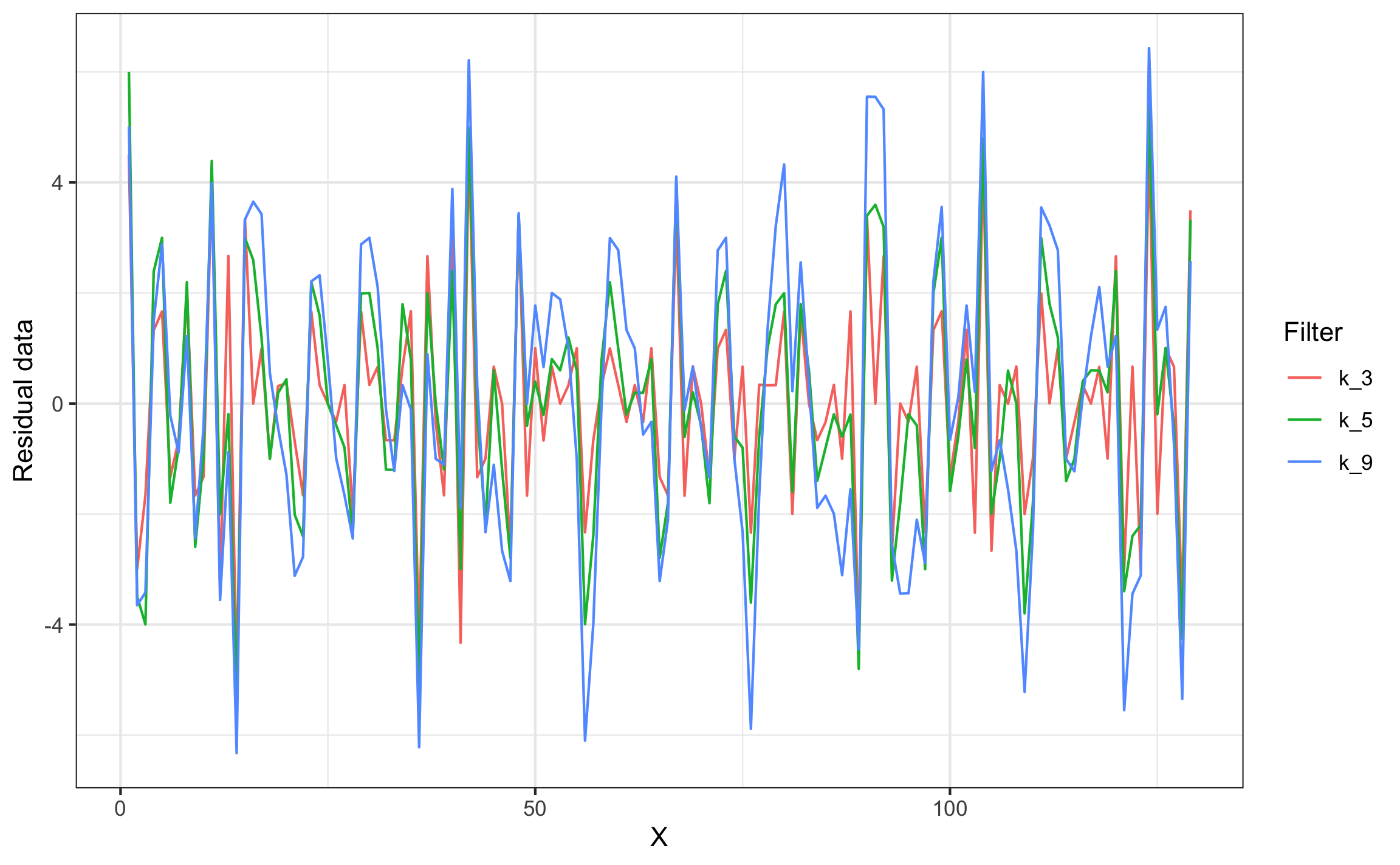
Figura 18.4: Ejemplo de residuales de datos filtrados (sin pesos)
moving_filter_plot_f(filt2)$GGPLOT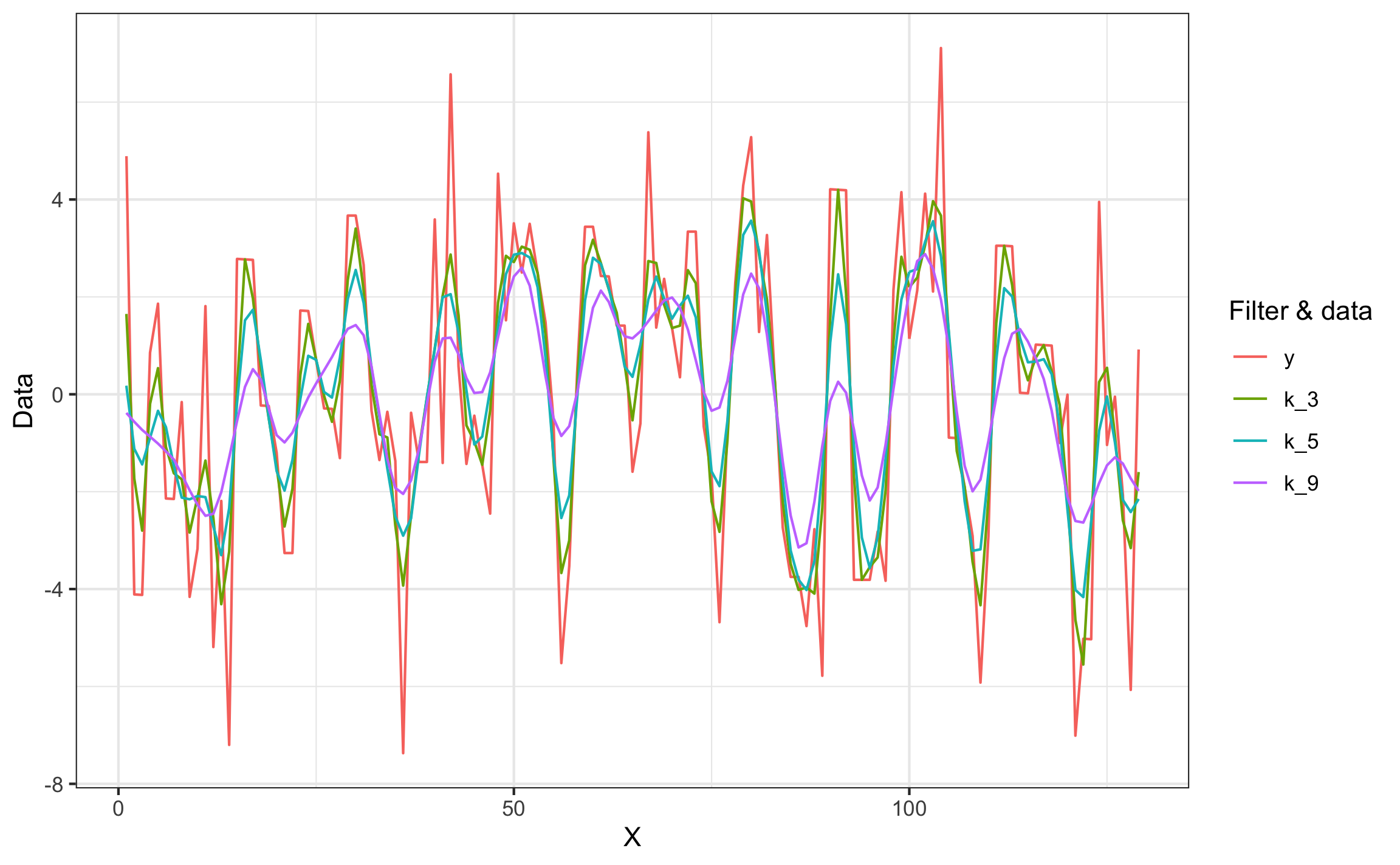
Figura 18.5: Ejemplo de datos crudos y filtrados (con pesos)
moving_filter_plot_r(filt2)$GGPLOT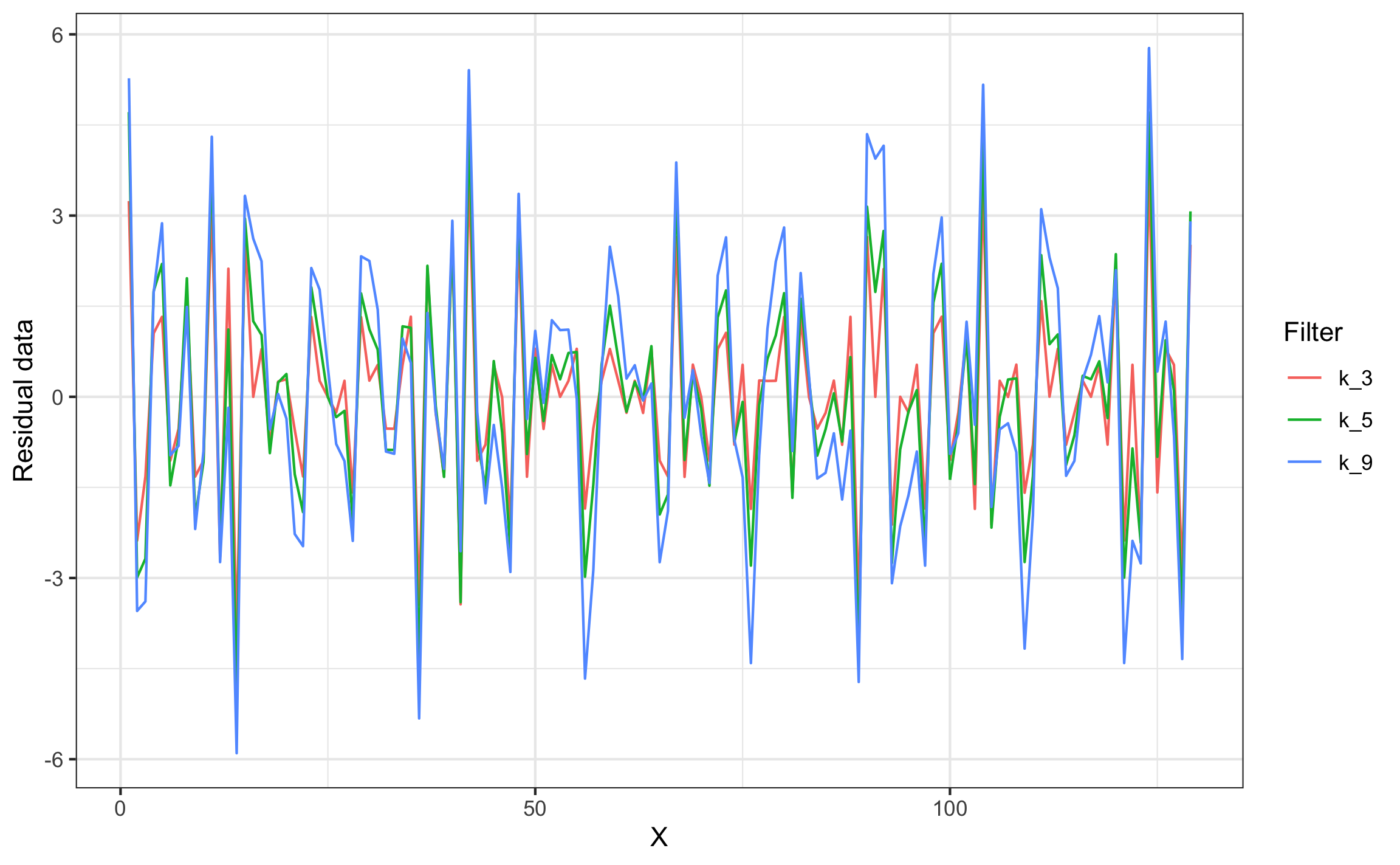
Figura 18.6: Ejemplo de residuales de datos filtrados (con pesos)
18.3.1.3 Tendencias
Para las técnicas que se van a exponer en los siguientes apartados, la presencia de una tendencia en los datos puede ser perjudicial en la medida que puede oscurecer los ciclos o patrones presentes en los datos, por lo que es recomendado remover la tendencia y realizar el análisis sobre los datos sin tendencia.
La tendencia más sencilla es la lineal y la forma de determinar si existe una tendencia o relación significativa entre la posición (o tiempo) y los datos es por medio de una regresión lineal simple (10.4) o correlación de Pearson (10.3, 15.9).
Para ejemplificar este concepto se van a usar los datos del nivel del agua en el lago Hurón, presentes en los juegos datos por defecto en R como LakeHuron. Éste es un objeto de tipo serie temporal (ts, 18.3.4) por lo que tiene una estructura especial, pero en el fondo es simplemente una secuencia con posición (en este caso tiempo) y observaciones (nivel del agua). Para visualizarlo con ggplot se puede usar la función autoplot de ggfortify (Horikoshi & Tang, 2020), a como se muestra en la Figura 18.7.
autoplot(LakeHuron) +
labs(x='Año', y='Nivel del lago')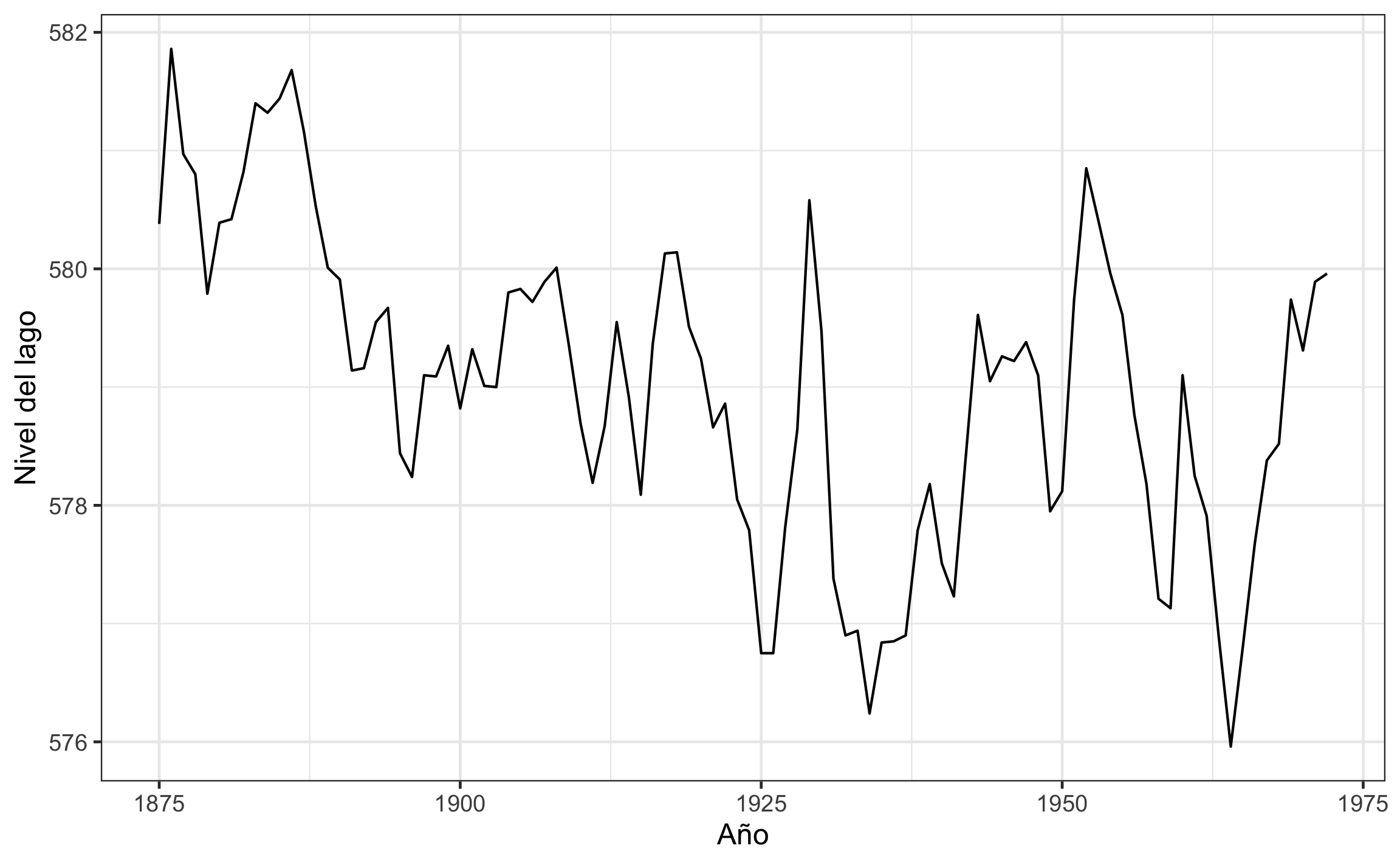
Figura 18.7: Visualización de la serie temporal del nivel del agua del lago Hurón.
Para pasar un objeto ts a un formato tabla, más universal, se puede usar la función tidy de broom (Robinson & Hayes, 2020), del metapaquete tidymodels (Kuhn & Wickham, 2020).
LakeHuron## Time Series:
## Start = 1875
## End = 1972
## Frequency = 1
## [1] 580.38 581.86 580.97 580.80 579.79 580.39 580.42 580.82 581.40 581.32
## [11] 581.44 581.68 581.17 580.53 580.01 579.91 579.14 579.16 579.55 579.67
## [21] 578.44 578.24 579.10 579.09 579.35 578.82 579.32 579.01 579.00 579.80
## [31] 579.83 579.72 579.89 580.01 579.37 578.69 578.19 578.67 579.55 578.92
## [41] 578.09 579.37 580.13 580.14 579.51 579.24 578.66 578.86 578.05 577.79
## [51] 576.75 576.75 577.82 578.64 580.58 579.48 577.38 576.90 576.94 576.24
## [61] 576.84 576.85 576.90 577.79 578.18 577.51 577.23 578.42 579.61 579.05
## [71] 579.26 579.22 579.38 579.10 577.95 578.12 579.75 580.85 580.41 579.96
## [81] 579.61 578.76 578.18 577.21 577.13 579.10 578.25 577.91 576.89 575.96
## [91] 576.80 577.68 578.38 578.52 579.74 579.31 579.89 579.96Huron = LakeHuron %>% tidy()
Huron## # A tibble: 98 x 2
## index value
## <dbl> <dbl>
## 1 1875 580.
## 2 1876 582.
## 3 1877 581.
## 4 1878 581.
## 5 1879 580.
## 6 1880 580.
## 7 1881 580.
## 8 1882 581.
## 9 1883 581.
## 10 1884 581.
## # … with 88 more rowsCon los datos en formato tabla se puede realizar la regresión o correlación. Tal vez la forma más sencilla y directa de cuantificar la relación (tendencia) y ver si es significativa o no es por medio de la correlación de Pearson, como se expuso en la sección 15.9, ya que como hay una relación entre correlación y regresión lineal simple, si una es significativa la otra lo va a ser también.
a = .05
huron.cor = Huron %>%
cor.test(~index+value,
data = .,
conf.level=1-a,
method = 'pearson')
huron.cor##
## Pearson's product-moment correlation
##
## data: index and value
## t = -5.9962, df = 96, p-value = 3.545e-08
## alternative hypothesis: true correlation is not equal to 0
## 95 percent confidence interval:
## -0.6527975 -0.3609537
## sample estimates:
## cor
## -0.5219892En este caso la correlación (tendencia) es significativa y negativa (\(r = -.52\), 95% IC \([-.65\), \(-.36]\), \(t(96) = -6.00\), \(p < .001\)), por lo que para cualquier análisis posterior es necesario remover dicha tendencia.
Para demostrar que se obtiene la misma conclusión con la regresión lineal simple se muestra el procedimiento. Una regresión se realiza por medio de la función lm a como se había introducido en el capítulo Estadística Descriptiva Bivariable, sección 10.4. Ahora se va a hacer énfasis en mostrar cómo determinar si la regresión (pendiente) es significativa.
huron.reg = lm(value ~ index, data = Huron)
huron.reg %>%
tidy(conf.int=T,conf.level=1-a)## # A tibble: 2 x 7
## term estimate std.error statistic p.value conf.low conf.high
## <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 (Intercept) 626. 7.76 80.6 5.81e-90 610. 641.
## 2 index -0.0242 0.00404 -6.00 3.55e- 8 -0.0322 -0.0162La significancia de la pendiente se puede determinar por medio del valor-p o el intervalo de confianza en el resumen de la regresión. A como se ha venido trabajando, si el valor-p está por debajo de un \(\alpha\) escogido y si 0 cae fuera del intervalo de confianza, entonces el estadístico es significativo. Para el caso del ejemplo, la pendiente es significativa y negativa (\(b = -0.024\), 95% IC \([-0.032\), \(-0.016]\), \(t(96) = -6.00\), \(p < .001\)).
Tanto la correlación como la regresión muestran una tendencia negativa, o sea el nivel del lago Hurón ha ido en descenso a lo largo del tiempo en que se tomaron los datos, y ésto se puede observar si se grafica la secuencia, a como se presentó en la Figura 18.7.
Para series de datos una manera de remover la tendencia es por medio de diferenciación, donde una tendencia lineal se remueve con una diferenciación de orden 1, una tendencia cuadrática se remueve con una diferenciación de orden 2, y así sucesivamente. Para ésto existe la función diff, a la cual se le puede pasar un vector de datos o el objeto de la serie, y el argumento differences se refiere al orden de la diferenciación.
Huron.dif = diff(LakeHuron,differences = 1)
Huron.dif## Time Series:
## Start = 1876
## End = 1972
## Frequency = 1
## [1] 1.48 -0.89 -0.17 -1.01 0.60 0.03 0.40 0.58 -0.08 0.12 0.24 -0.51
## [13] -0.64 -0.52 -0.10 -0.77 0.02 0.39 0.12 -1.23 -0.20 0.86 -0.01 0.26
## [25] -0.53 0.50 -0.31 -0.01 0.80 0.03 -0.11 0.17 0.12 -0.64 -0.68 -0.50
## [37] 0.48 0.88 -0.63 -0.83 1.28 0.76 0.01 -0.63 -0.27 -0.58 0.20 -0.81
## [49] -0.26 -1.04 0.00 1.07 0.82 1.94 -1.10 -2.10 -0.48 0.04 -0.70 0.60
## [61] 0.01 0.05 0.89 0.39 -0.67 -0.28 1.19 1.19 -0.56 0.21 -0.04 0.16
## [73] -0.28 -1.15 0.17 1.63 1.10 -0.44 -0.45 -0.35 -0.85 -0.58 -0.97 -0.08
## [85] 1.97 -0.85 -0.34 -1.02 -0.93 0.84 0.88 0.70 0.14 1.22 -0.43 0.58
## [97] 0.07Otra forma de remover la tendencia es obteniendo los residuales a partir de la regresión. Lo anterior se puede obtener de forma sencilla aplicando la función augment de broom sobre el objeto de regresión. El objeto resultante va a tener los datos usados en la regresión así como otras columnas, incluida .resid que almacena los residuales.
Huron.aug = huron.reg %>% augment()
Huron.aug## # A tibble: 98 x 9
## value index .fitted .se.fit .resid .hat .sigma .cooksd .std.resid
## <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 580. 1875 580. 0.227 0.202 0.0402 1.14 0.000698 0.183
## 2 582. 1876 580. 0.223 1.71 0.0390 1.12 0.0481 1.54
## 3 581. 1877 580. 0.220 0.841 0.0378 1.13 0.0113 0.758
## 4 581. 1878 580. 0.216 0.695 0.0366 1.13 0.00745 0.626
## 5 580. 1879 580. 0.213 -0.291 0.0355 1.14 0.00126 -0.262
## 6 580. 1880 580. 0.209 0.333 0.0343 1.14 0.00160 0.300
## 7 580. 1881 580. 0.206 0.387 0.0332 1.14 0.00209 0.349
## 8 581. 1882 580. 0.203 0.812 0.0322 1.13 0.00885 0.730
## 9 581. 1883 580. 0.199 1.42 0.0311 1.13 0.0260 1.27
## 10 581. 1884 580. 0.196 1.36 0.0301 1.13 0.0232 1.22
## # … with 88 more rowsUna vez removida la tendencia se puede graficar de nuevo la serie, a como se muestra en la Figura 18.8 para el caso de la diferenciación, y en la Figura 18.9 para el caso de los residuales de la regresión.
Huron.dif %>%
autoplot() +
labs(x='Año', y='Cambio en el nivel del lago')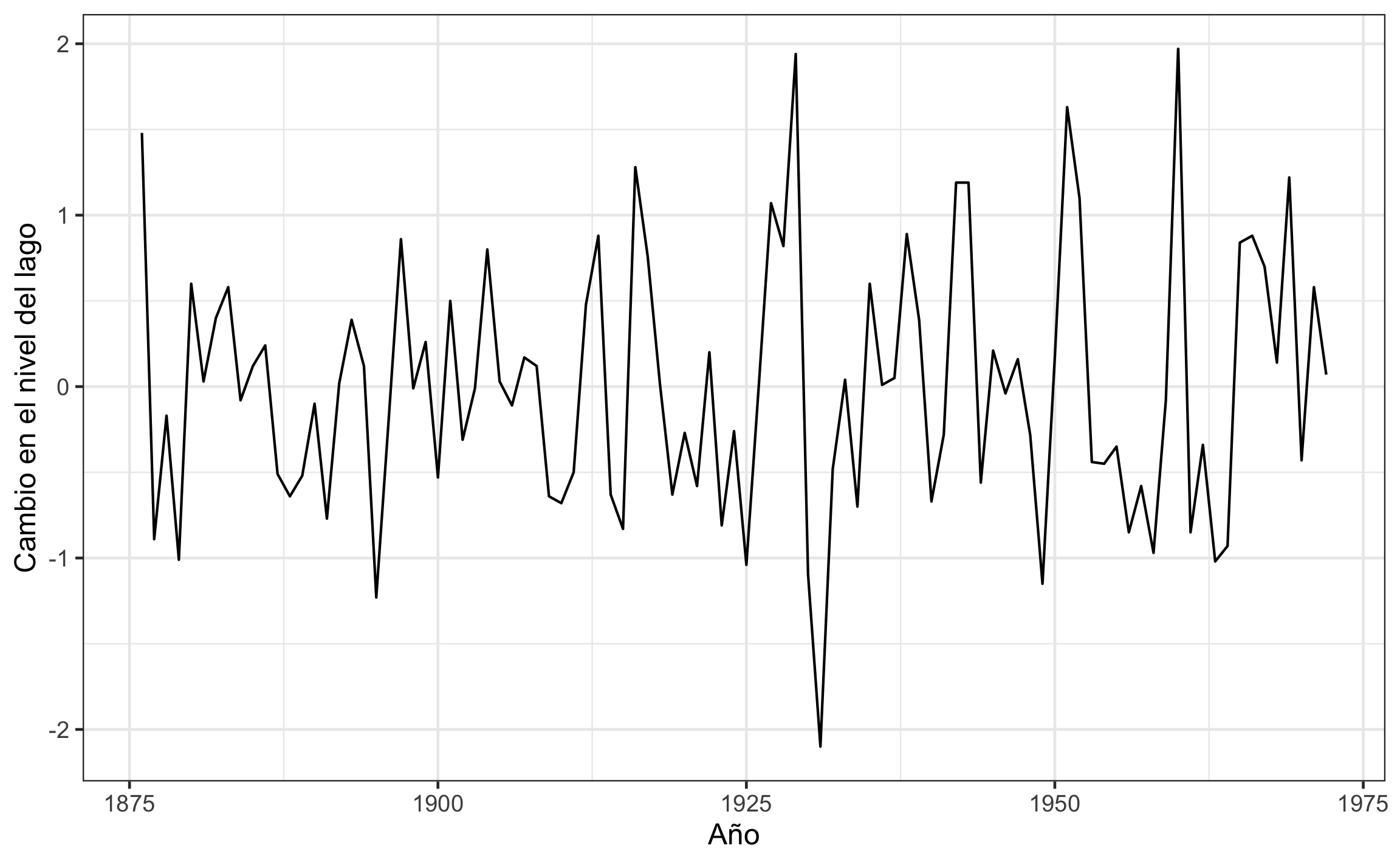
Figura 18.8: Serie de diferencias del cambio en el nivel del agua en el lago Hurón.
Huron.aug %>%
ggplot(aes(index,.resid)) +
geom_line() +
labs(x='Año', y='Residuales del nivel del lago')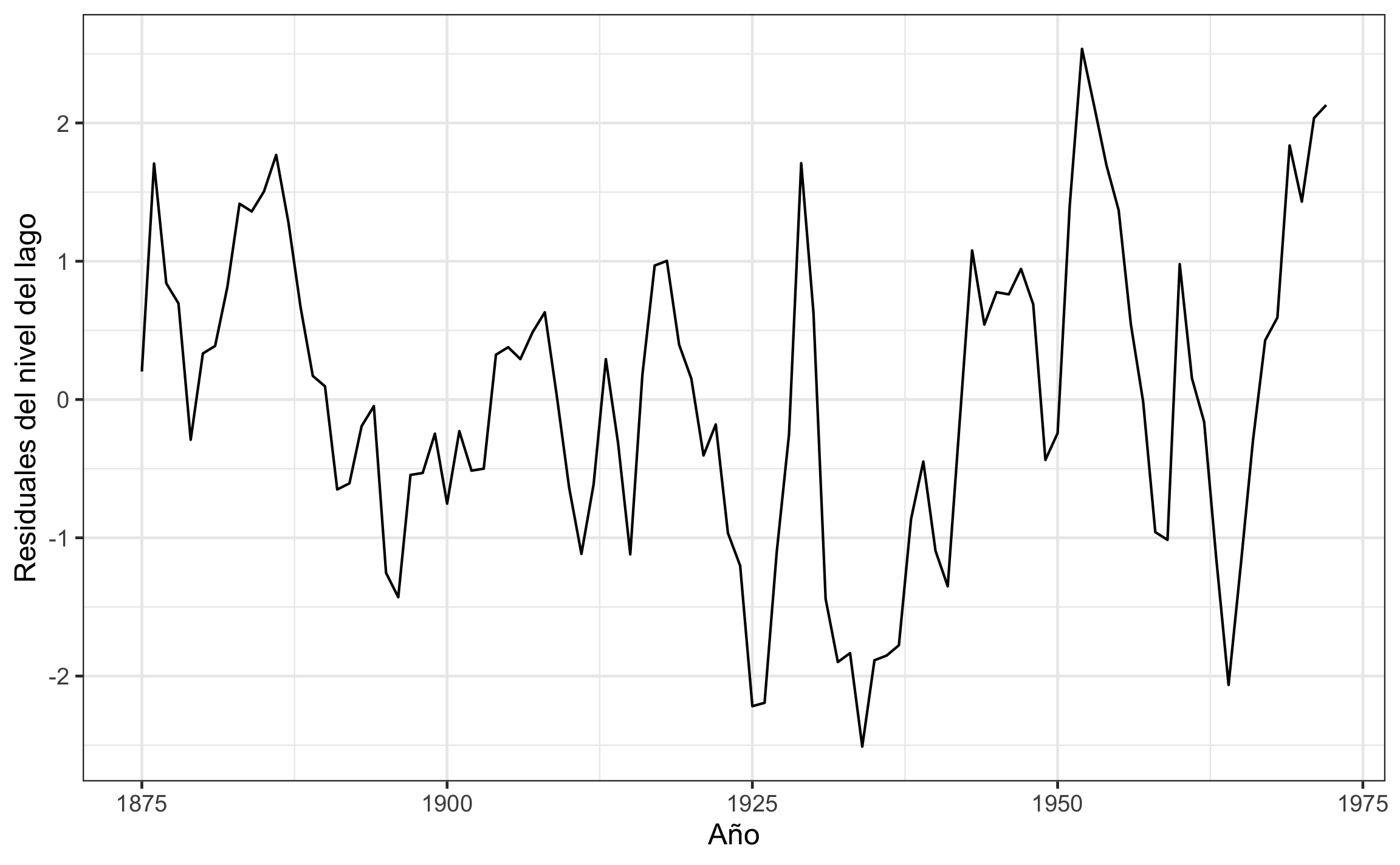
Figura 18.9: Serie de residuales del nivel del agua en el lago Hurón.
Estos datos sin tendencia serían los que se usan en análisis posteriores.
18.3.2 Auto-correlación
La auto-correlación es simplemente comparar una secuencia o serie con ella misma, a diferentes separaciones o lags (\(\tau\)). La comparación se realiza por medio del coeficiente de correlación a los diferentes lags, donde cada vez que se desplaza la secuencia se calcula el coeficiente, por medio de la Ecuación (18.6).
\[\begin{equation} r_{\tau} = \frac{\sum_{i=1}^{N-\tau} Z_{yi}Z_{y(i+\tau)}}{N-\tau} \tag{18.6} \end{equation}\]
A un lag de 0 la correlación siempre va a ser \(r_{\tau}=1\) y conforme se va desplazando va a tender a disminuir. El resultado de la auto-correlación se representa por medio del correlograma, el cual puede tomar diferentes formas dependiendo de los datos, y se muestran varios ejemplos en la Figura 18.10 (Davis, 2002). Si al incrementar el lag se vuelve a dar un alto coeficiente de correlación (\(r_{\tau}\)), ésto puede indicar presencia de ciclos o patrones en los datos. Se recomienda, para un resultado más confiable, realizar este análisis sobre series de datos que tengan \(N>50\) y calcular la auto-correlación a no más de \(N/4\), ya que conforme más se desplace la secuencia menos datos se usan en el cálculo y menos confiable (más variable) el resultado.
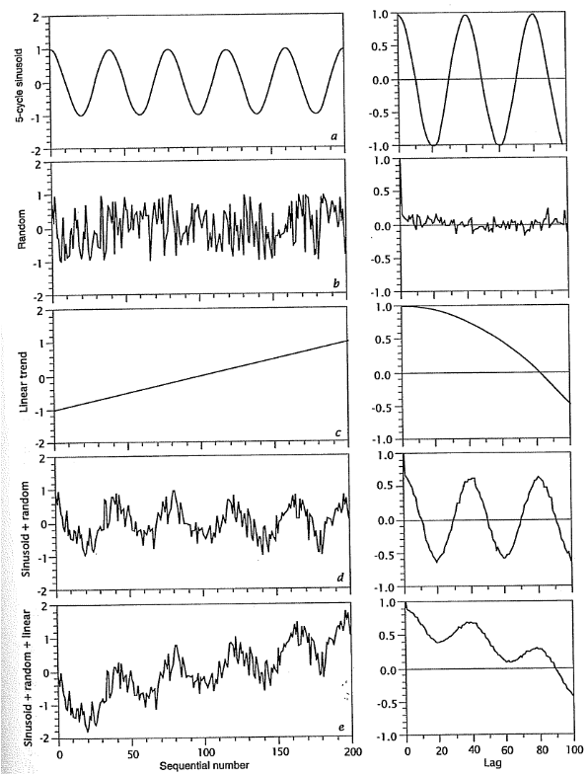
Figura 18.10: Ejemplos de series de datos con su respectivo correlograma, tomada de Davis (2002). a Serie sinusoidal. b Serie aleatoria. c Serie con tendencia lineal. d Serie sinusoidal con componente aleatorio. e Serie sinusoidal con componente aleatorio y una tendencia.
Para determinar si existe una auto-correlación significativa se puede realizar la prueba de significancia conforme la Ecuación (18.7), donde \(r_{\tau}\) es el valor de auto-correlación a un lag (\(\tau\)) específico (valor más alto después de un ciclo), y \(N\) es la longitud de la serie.
\[\begin{equation} z_{\tau} = r_{\tau}\sqrt{N-\tau+3} \tag{18.7} \end{equation}\]
- \(H_0: \rho_{\tau} = 0 \to\) No hay patrón en la serie (aleatoria)
- \(H_1: \rho_{\tau} \neq 0 \to\) Hay un patrón en la serie
En R se tiene la función acf que calcula la auto-correlación a diferentes lags, donde se ocupa un vector de datos o el objeto de serie, el resto de los argumentos son opcionales, lag.max es el lag hasta el cual calcular la auto-correlación, y plot=F es para suprimir que grafique el resultado, ya que se pasa el resultado a autoplot de ggfortify para poder visualizarlo con ggplot2 (Figura @ref(fig: huron-acf)). La visualización muestra una líneas punteadas que corresponden con el intervalo de confianza, por lo que si un pico de auto-correlación sobrepasa esta línea es indicativo de una auto-correlación significativa al lag del pico.
N = length(Huron.dif)
Huron.dif %>%
acf(lag.max = N/4, plot = F) %>%
autoplot(conf.int.value = 1-a)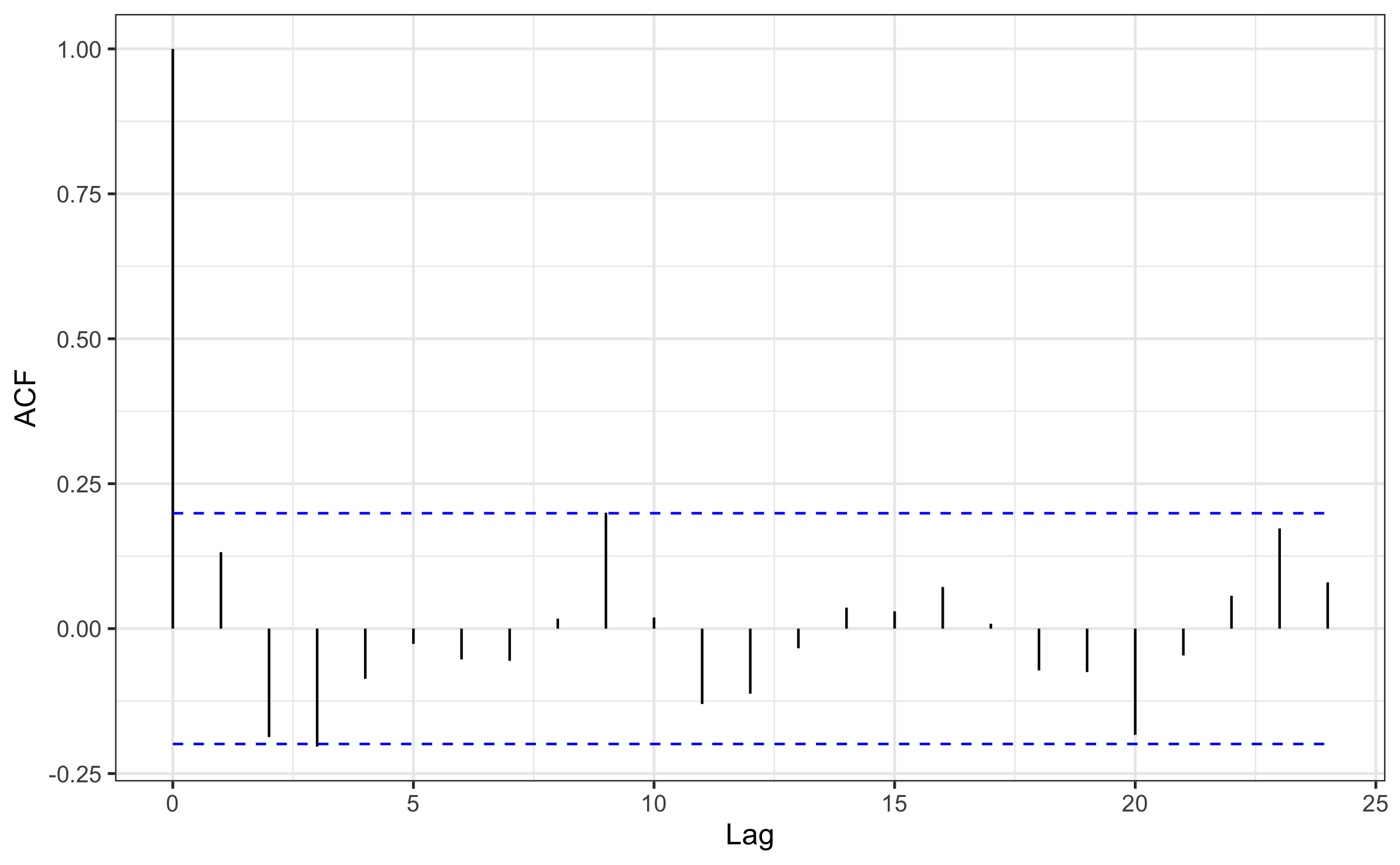
Figura 18.11: Correlograma para el cambio del nivel de agua en el lago Hurón.
No hay una forma directa de realizar la prueba de significancia de auto-correlación, por lo que desarrollé una serie de comandos para extraer la información necesaria (\(r_{\tau}, \tau\)) y calcular el estadístico de la prueba (no es a prueba de errores, se recomienda inspeccionar el resultado).
ac = acf(Huron.dif,plot = F)
ac = tidy(ac)
lagt = ac %>%
filter(acf < 0) %>%
slice(1) %>%
select(lag) %>%
pull()
(rtau = ac %>%
slice((which(ac$lag==lagt)[1]+1):n()) %>%
summarise(max(acf)) %>%
pull()) # valor maximo de autocorrelacion## [1] 0.1999353(tau = ac %>%
filter(acf == rtau) %>%
select(lag) %>%
pull())# lag donde ocurre el valor maximo de autocorrelacion## [1] 9(z = rtau * sqrt(N - tau + 3)) # prueba de significancia de autocorrelacion## [1] 1.907261De forma manual la significancia se estima de la siguiente manera:
\[\begin{equation} z_{\tau} = r_{\tau}\sqrt{N-\tau+3}\\ z_{\tau} = .2\sqrt{97-9+3} = 1.91 \end{equation}\]
Los resultados muestran que hay un pico importante a un lag de 9 (\(\tau=9\)), donde \(r_{\tau}=.2\), y con ésto se obtiene un estadístico \(z=1.91\), que al comparar con el valor crítico de \(z_{\alpha/2}=1.96\) (para \(\alpha=.05\)) se tiene que es menor por lo que la auto-correlación no es significativa, aunque por muy poco, por lo que hay evidencia marginal de una posible auto-correlación.
18.3.3 Correlación-cruzada
La correlación cruzada sirve para comparar dos series con el fin de determinar la magnitud de la relación y a qué lag se da la máxima relación. Difiere de la auto-correlación en el sentido de que no se posible establecer un cero lag, a menos que las dos series tengan un origen y escala común (por lo que el correlograma-cruzado tiene lags positivos y negativos), y las dos series pueden tener diferente longitud (número de observaciones).
Se pueden usar las siguientes dos reglas para la interpretación:
- Cuando se tiene una correlación importante en los lags negativos, quiere decir que x está por delante de y
- Cuando se tiene una correlación importante en los lags positivos, quiere decir que x está atrasada con respecto a y
Para determinar si existe una correlación-cruzada significativa se puede realizar la prueba de significancia conforme la Ecuación (18.8), donde \(r_{\tau}\) es el valor de auto-correlación (valor más alto) a un lag (\(\tau\)) específico, y \(N\) es la longitud de la serie. Esta prueba sigue una distribución \(t\) con \(v=N-\tau-2\) grados de libertad.
\[\begin{equation} t_{\tau} = r_{\tau}\sqrt{\frac{N-\tau-2}{1-r_{\tau}^2}} \tag{18.8} \end{equation}\]
- \(H_0: \rho_{\tau} = 0 \to\) No hay relación entre las series
- \(H_1: \rho_{\tau} \neq 0 \to\) Hay relación entre las series al lag \(\tau\)
Para demostrar este análisis se usa un ejemplo de Davis (2002), donde se tienen los datos de agua inyectada en un pozo y el número de sismos por mes, buscando si existe una relación entre el agua inyectada y los sismos, y si la hay con que frecuencia o desfase.
arsenal = import('data/ARSENAL.csv',setclass = 'tbl')
arsenal## # A tibble: 40 x 4
## Date WasteInjected Quakes SequentialMonth
## <chr> <dbl> <int> <int>
## 1 3/1/62 4.2 0 3
## 2 4/1/62 7.2 2 4
## 3 5/1/62 8.4 12 5
## 4 6/1/62 8 35 6
## 5 7/1/62 5.2 23 7
## 6 8/1/62 6 29 8
## 7 9/1/62 5 24 9
## 8 10/1/62 5.6 8 10
## 9 11/1/62 4 6 11
## 10 12/1/62 3.6 20 12
## # … with 30 more rowsR tiene la función ccf que ocupa los dos vectores de datos u objetos de series. Es importante pensar en qué va en x y qué va en y de acuerdo a la interpretación que se quiera obtener o hipótesis que se tenga.
with(arsenal,
ccf(x = Quakes, y = WasteInjected, plot = F)) %>%
autoplot(ylab='CCF', conf.int.value = 1-a)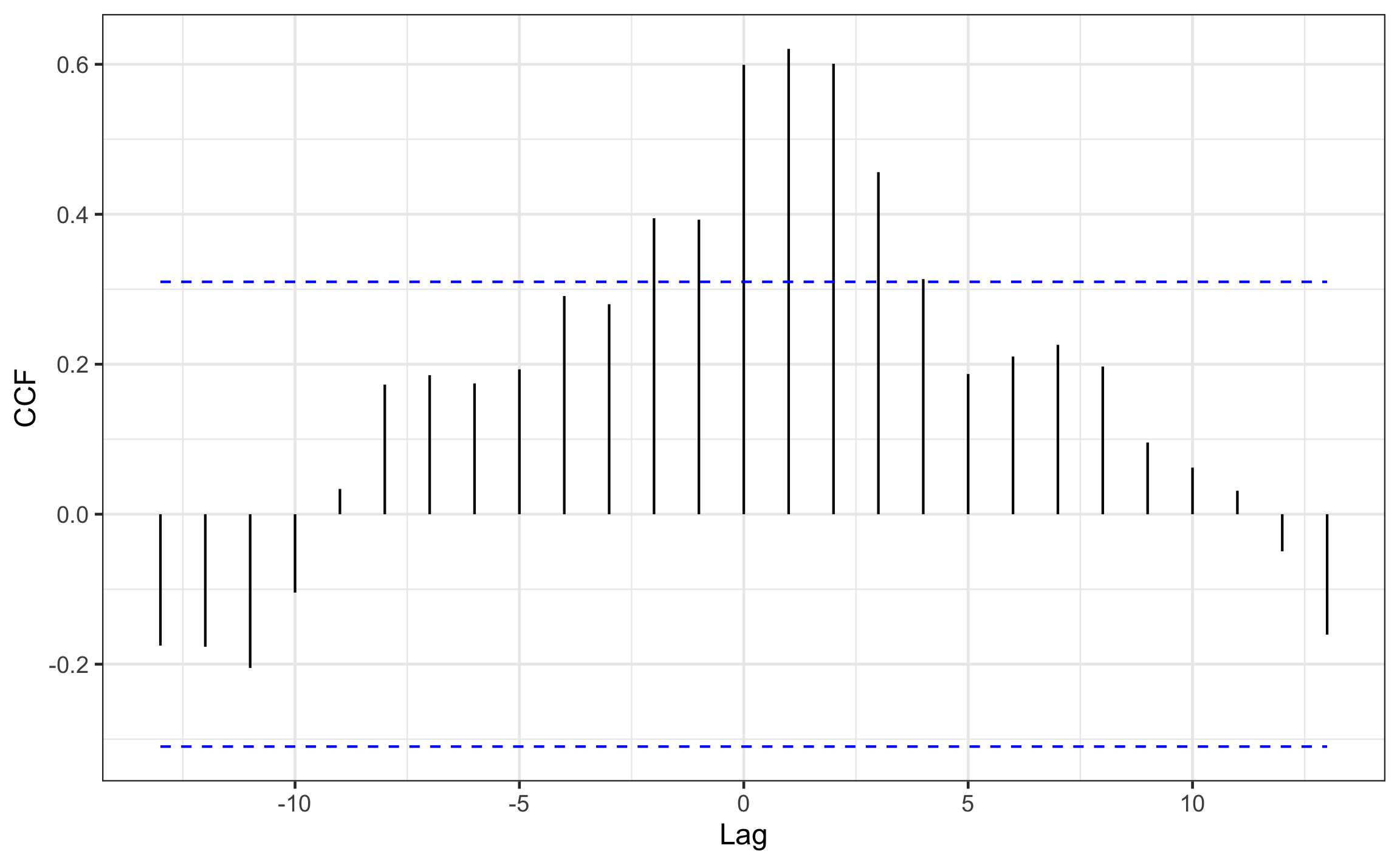
Figura 18.12: Correlograma-cruzado entre inyección de agua sobre la presencia de sismos. Datos de Davis (2002).
La significancia se estima de la siguiente manera:
\[\begin{equation} t_{\tau} = r_{\tau}\sqrt{\frac{N-\tau-2}{1-r_{\tau}^2}}\\ t_{\tau} = .62\sqrt{\frac{40-1-2}{1-.62^2}} = 4.81\\ t_{\alpha/2,v} = t_{.05/2,37} = 2.03 \end{equation}\]
El correlograma-cruzado muestra la mayor relación a un lag de \(+1\), donde \(r_{\tau}=.62\), y este valor está por encima del intervalo de confianza (\(t_{\tau} > t_{\alpha/2,v}\)), por lo que es significativo. Este resultado indica que hay una relación entre la inyección de agua y los sismos registrados, con un desfase de 1 mes. Usando las reglas de interpretación mencionadas anteriormente se tiene una correlación importante en los lags positivos, por lo que x está atrasada con respecto a y, y en este caso, los sismos están atrasados con respecto a la inyección de agua por 1 mes.
Hay que tener en cuenta que el correlograma y la prueba de significancia indican el lag al que ocurre la máxima correlación (auto, cruzada), pero para saber a qué unidades (tiempo o distancia) de la variable original corresponde es necesario conocer el intervalo de muestreo.
Si \(\Delta = 1\) entonces la distancia o tiempo al cual ocurre la correlación es igual a \(\tau\).
Si \(\Delta \neq 1\), por ejemplo \(\Delta = 0.5\), entonces la distancia o tiempo al cual ocurre la correlación es igual a \(\Delta \cdot \tau\).18.3.4 Objetos de serie
Esta sección hace una breve introducción a los objetos de serie temporal, principalmente cómo crearlos, y qué carácterísticas o atributos especiales tienen.
Los objetos de serie temporal/espacial tienen atributos que definen el inicio (start), final (end), intervalo de medición (deltat), y frecuencia (frequency) de la serie.
Para crear estos objetos se puede usar la función ts que trae R. Hay otros paquetes que se especializan en este tipo de objetos y su análisis, como zoo (Zeileis et al., 2020), que trae la función zoo para crear este tipo de objetos.
La función ts funciona especialmente para series temporales, ya que dentro de los argumentos que tiene para la creación del objeto están start, end, y frequency o deltat, donde todos éstos corresponden con unidades de tiempo.
Usando los datos del ejemplo de correlación-cruzada sería como se muestra a continuación, donde start se define como un vector de dos entradas (año, mes), y se requiere definir solo uno de los otros argumentos, en este caso frequency equivale a la cantidad de mediciones por unidad de tiempo.
arsenal.sismos.ts = ts(data = arsenal$Quakes,
start = c(1962,3),
frequency = 12)
arsenal.sismos.ts## Jan Feb Mar Apr May Jun Jul Aug Sep Oct Nov Dec
## 1962 0 2 12 35 23 29 24 8 6 20
## 1963 25 22 21 42 21 8 6 10 11 12 4 2
## 1964 5 2 9 9 2 4 4 5 2 14 2 7
## 1965 1 30 9 19 11 38arsenal.sismos.ts %>%
autoplot() +
labs(x='Año', y='Cantidad de sismos')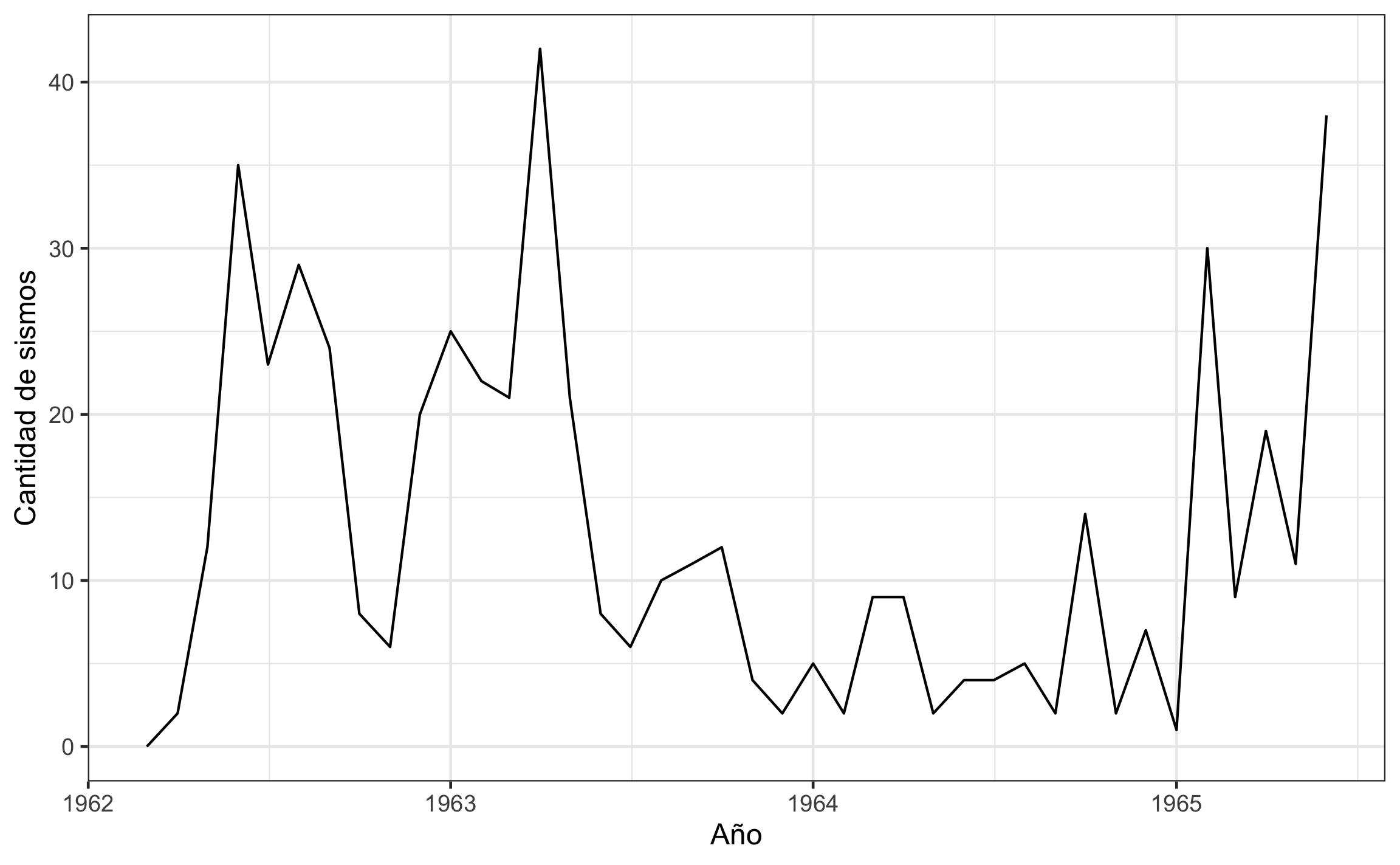
Figura 18.13: Serie temporal de sismos usando ts
La función zoo requiere el argumento order.by que puede tomar cualquier tipo de dato (tiempo, distancia) y tiene la ventaja de que puede crear series con intervalos de muestreo irregular.
Con los datos de arsenal es necesario modificar la columna de fechas a un formato de fecha. Posteriormente se usa esta columna para ordenar los datos.
arsenal2 = arsenal %>%
mutate(Date = str_replace(Date,'/6','/196') %>% lubridate::mdy())arsenal.sismos.zoo = zoo(arsenal2$Quakes, order.by = arsenal2$Date)
arsenal.sismos.zoo## 1962-03-01 1962-04-01 1962-05-01 1962-06-01 1962-07-01 1962-08-01 1962-09-01
## 0 2 12 35 23 29 24
## 1962-10-01 1962-11-01 1962-12-01 1963-01-01 1963-02-01 1963-03-01 1963-04-01
## 8 6 20 25 22 21 42
## 1963-05-01 1963-06-01 1963-07-01 1963-08-01 1963-09-01 1963-10-01 1963-11-01
## 21 8 6 10 11 12 4
## 1963-12-01 1964-01-01 1964-02-01 1964-03-01 1964-04-01 1964-05-01 1964-06-01
## 2 5 2 9 9 2 4
## 1964-07-01 1964-08-01 1964-09-01 1964-10-01 1964-11-01 1964-12-01 1965-01-01
## 4 5 2 14 2 7 1
## 1965-02-01 1965-03-01 1965-04-01 1965-05-01 1965-06-01
## 30 9 19 11 38arsenal.sismos.zoo %>%
autoplot() +
labs(x='Año', y='Cantidad de sismos')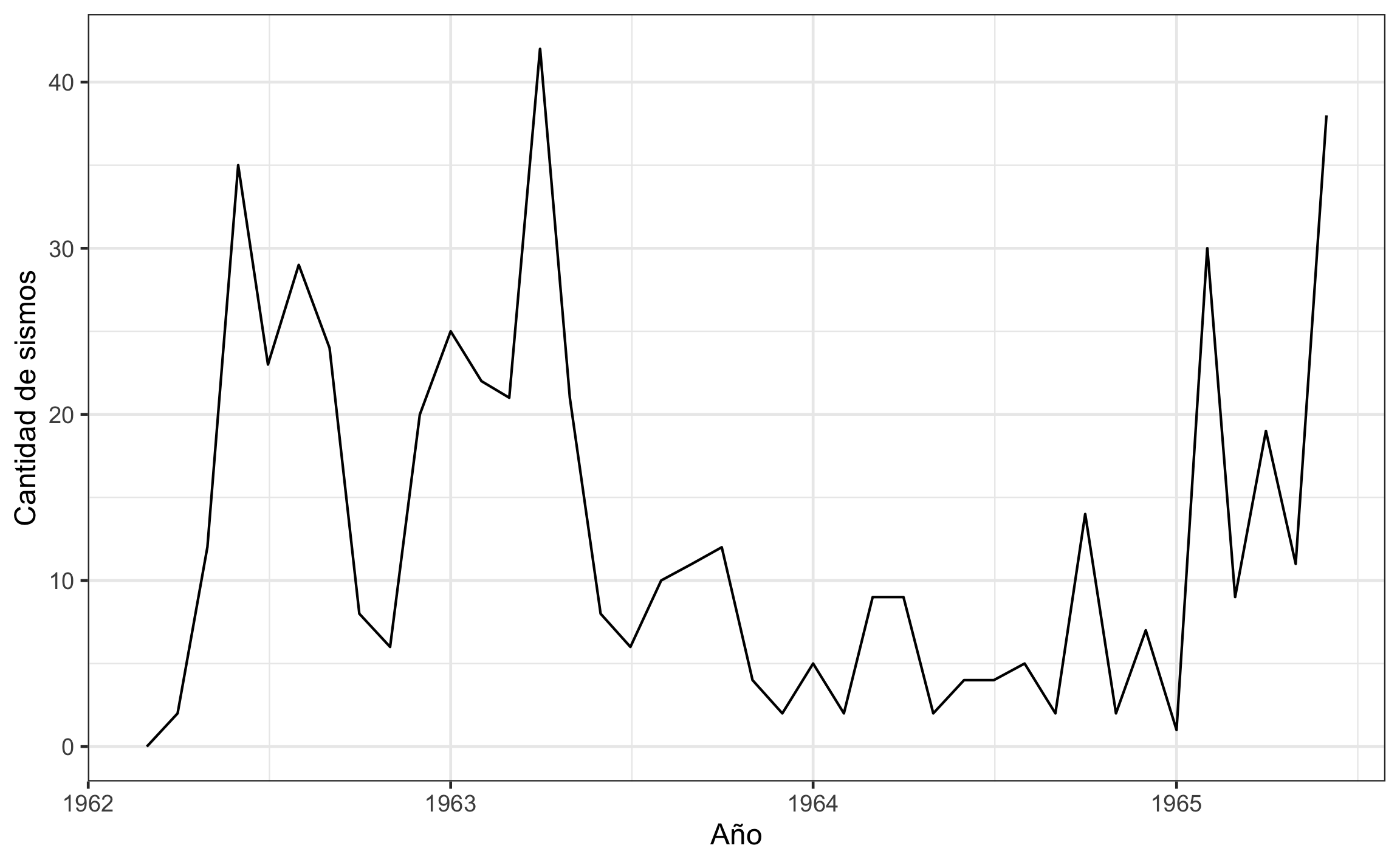
Figura 18.14: Serie temporal de sismos usando zoo
Para ejemplificar una serie espacial y con intervalo irregular se usan los datos de un sondeo magnético.
mag = import('data/magnetismo.xlsx',setclass = 'tbl')
mag## # A tibble: 132 x 2
## Position Anomaly
## <dbl> <dbl>
## 1 0 128.
## 2 0.667 130.
## 3 1.33 132.
## 4 2 134.
## 5 2.67 137.
## 6 3.33 140.
## 7 4.00 143.
## 8 4.67 145.
## 9 5.33 147.
## 10 6 149.
## # … with 122 more rowsmag.zoo = zoo(mag$Anomaly, order.by = mag$Position)
mag.zoo## 0 0.6667 1.3333 2 2.6667 3.3333 4 4.6667
## 127.9670 129.7269 131.7459 134.2928 137.1778 139.9677 142.5376 145.2026
## 5.3333 6 6.6667 7.3333 8 8.6667 9.3333 10
## 147.3325 149.3634 150.2964 151.2823 152.4763 153.1932 153.9201 154.6881
## 10.6667 11.3333 12 12.6667 13.3333 14 14.6667 15.3333
## 155.2840 155.0600 154.0229 152.2758 152.1948 153.4757 155.2887 163.1816
## 16 16.6667 17.3333 18 18.6667 19.3333 20 20.5882
## 167.5095 160.7085 157.7804 156.6403 155.1523 154.6102 154.6102 154.9571
## 21.1765 21.7647 22.3529 22.9412 23.5294 24.1176 24.7059 25.2941
## 155.7630 156.5350 156.5699 156.5889 157.3398 157.1807 156.4457 156.2956
## 25.8824 26.4706 27.0588 27.6471 28.2353 28.8235 29.4118 30
## 156.1926 155.8265 155.1464 154.7994 153.6693 152.7082 151.5122 150.6671
## 30.5882 31.1765 31.7647 32.3529 32.9412 33.5294 34.1176 34.7059
## 150.7911 151.1110 151.3379 150.8509 150.7348 150.4348 149.9967 149.2806
## 35.2941 35.8824 36.4706 37.0588 37.6471 38.2353 38.8235 39.4118
## 148.4066 147.7495 147.3705 147.3514 146.9793 146.7883 148.6342 152.6611
## 40 40.6061 41.2121 41.8182 42.4242 43.0303 43.6364 44.2424
## 155.4831 155.2910 154.2870 152.7459 151.5398 150.0868 149.5687 148.8137
## 44.8485 45.4545 46.0606 46.6667 47.2727 47.8788 48.4848 49.0909
## 147.4116 145.6475 144.4735 143.8444 143.2384 142.3933 141.3612 140.8662
## 49.697 50.303 50.9091 51.5152 52.1212 52.7273 53.3333 53.9394
## 139.1571 139.0240 139.0260 139.8949 140.3909 139.6298 139.5377 139.8267
## 54.5455 55.1515 55.7576 56.3636 56.9697 57.5758 58.1818 58.7879
## 139.9726 140.4866 141.8915 140.5654 138.0454 136.6463 135.7893 135.3002
## 59.3939 60 60.5882 61.1765 61.7647 62.3529 62.9412 63.5294
## 134.6781 134.2511 133.6890 133.5809 133.4179 132.5498 132.4578 132.1167
## 64.1176 64.7059 65.2941 65.8824 66.4706 67.0588 67.6471 68.2353
## 131.7946 130.4576 129.5175 129.3035 128.8224 128.4323 127.7803 127.7882
## 68.8235 69.4118 70 70.5882 71.1765 71.7647 72.3529 72.9412
## 126.8402 126.0071 126.3510 130.4600 141.9039 158.1178 164.8128 148.3687
## 73.5294 74.1176 74.7059 75.2941 75.8824 76.4706 77.0588 77.6471
## 134.2557 126.7166 123.1805 121.4425 120.1204 119.6494 118.6973 117.5382
## 78.2353 78.8235 79.4118 80
## 116.8952 116.4371 116.6631 116.3050mag.zoo %>%
autoplot() +
labs(x='Distancia (m)', y='Anomalía magnética (mgal)')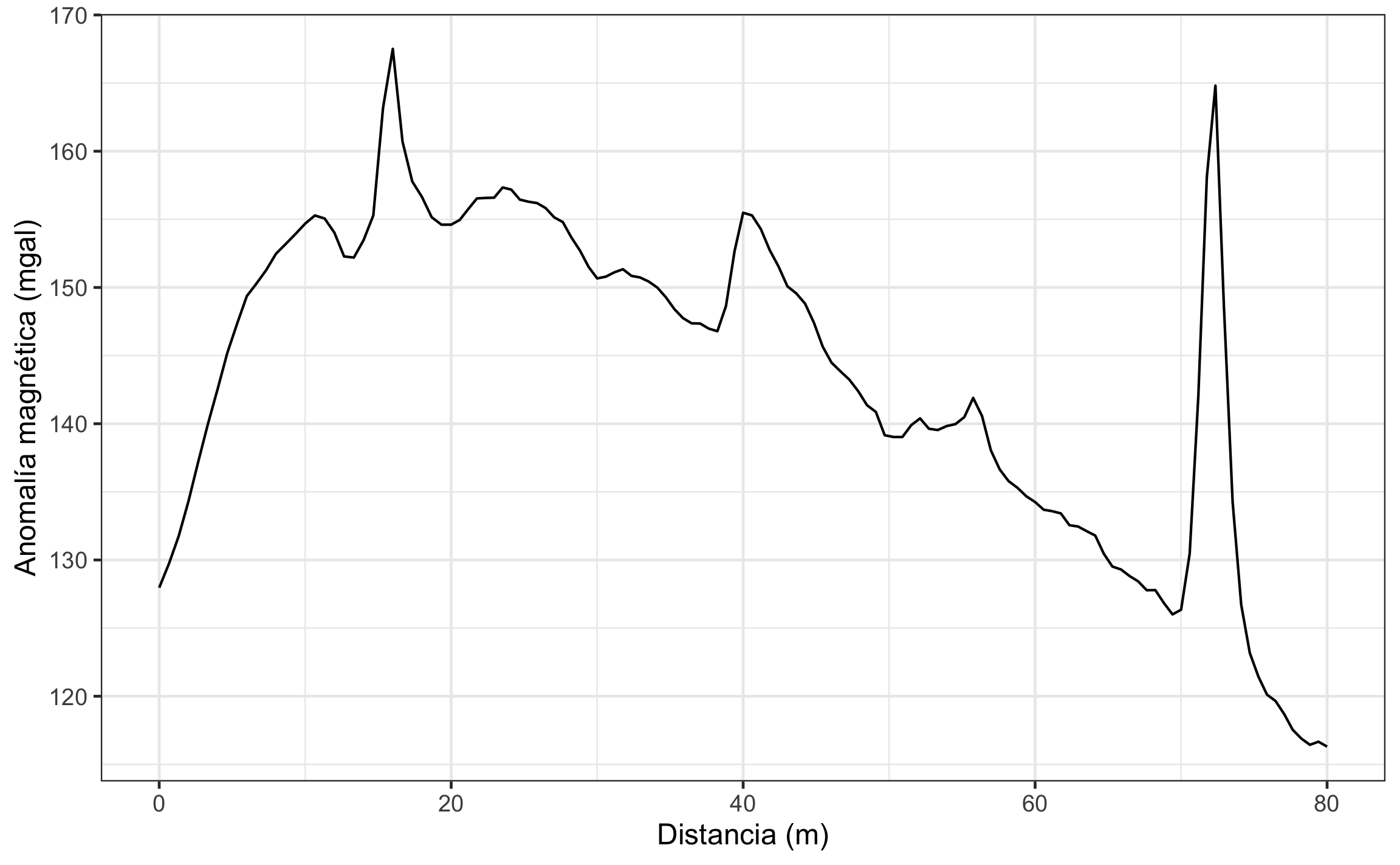
Figura 18.15: Serie espacial de sondeo mágnetico usando zoo
Dentro de los métodos o funciones que se pueden aplicar sobre este tipo de objetos están:
index: Extrae vector de valores de la variable de tiempo o espacio.coredata: Extrae vector de valores de la variable de interés.window: Extrae una ventana o parte de la serie a partir de un inicio (start) y final (end).diff: Crea vector u objeto de serie de las diferencias.tidy: Transforma objeto a tabla (tibble).autoplot: Visualiza la serie usando ggplot2.
Referencias
Borradaile, G. J. (2003). Statistics of Earth Science Data: Their Distribution in Time, Space and Orientation. Springer-Verlag Berlin Heidelberg.
Davis, J. C. (2002). Statistics and Data Analysis in Geology (3.ª ed.). John Wiley & Sons.
Garnier-Villarreal, M. (2020). GMisc: Miscellaneous Functions for Geology (and its areas). http://github.com/maxgav13/GMisc
Horikoshi, M., & Tang, Y. (2020). ggfortify: Data Visualization Tools for Statistical Analysis Results. https://CRAN.R-project.org/package=ggfortify
Kuhn, M., & Wickham, H. (2020). tidymodels: Easily Install and Load the ’Tidymodels’ Packages. https://CRAN.R-project.org/package=tidymodels
McKillup, S., & Darby Dyar, M. (2010). Geostatistics Explained: An Introductory Guide for Earth Scientists. Cambridge University Press. www.cambridge.org/9780521763226
Robinson, D., & Hayes, A. (2020). broom: Convert Statistical Analysis Objects into Tidy Tibbles. https://CRAN.R-project.org/package=broom
Sievert, C., Parmer, C., Hocking, T., Chamberlain, S., Ram, K., Corvellec, M., & Despouy, P. (2020). plotly: Create Interactive Web Graphics via ’plotly.js’. https://CRAN.R-project.org/package=plotly
Signorell, A. (2020). DescTools: Tools for Descriptive Statistics. https://CRAN.R-project.org/package=DescTools
Swan, A., & Sandilands, M. (1995). Introduction to Geological Data Analysis. Blackwell Science.
Wickham, H., Chang, W., Henry, L., Pedersen, T. L., Takahashi, K., Wilke, C., Woo, K., Yutani, H., & Dunnington, D. (2020). ggplot2: Create Elegant Data Visualisations Using the Grammar of Graphics. https://CRAN.R-project.org/package=ggplot2
Zeileis, A., Grothendieck, G., & Ryan, J. A. (2020). zoo: S3 Infrastructure for Regular and Irregular Time Series (Z’s Ordered Observations). https://CRAN.R-project.org/package=zoo