Capítulo 15 Pruebas Estadísticas
15.1 Introducción
En la sección 14.3 se introdujeron las bases teóricas de lo que son las pruebas de hipótesis, las partes o elementos que la componen, y cómo tomar una decisión una vez llevada a cabo la prueba. Este capítulo se centra en la parte práctica de cómo realizar una prueba estadística paramétrica (los pasos generales). Además se introduce el concepto de tamaño del efecto (effect size - ES - en inglés), y de cómo puede éste agregar información después de realizada la prueba, así como la importancia práctica que representa. Se recomienda revisar los apéndices para saber cómo reportar estadísticas y resultados de pruebas estadísticas, y para tener una guía de cuál prueba escoger.
15.2 Pruebas paramétricas
De manera general se van a cubrir las pruebas estadísticas homólogas con las estimaciones que se presentaron en el capítulo anterior en la sección Estimación (14.2), donde la práctica en general es usar un contraste bilateral a menos que sea muy justificado un contraste unilateral. Las pruebas se resumen a continuación y serán detalladas más adelante:
- Prueba \(z\) de 1 muestra (15.4)
- \(H_0: \mu = \mu_0\)
- Prueba \(t\) de 1 muestra (15.5)
- \(H_0: \mu = \mu_0\)
- Prueba \(t\) de 2 muestras independientes (15.6)
- \(H_0: \mu_1 = \mu_2\)
- Prueba \(t\) de 2 muestras dependientes (15.7)
- \(H_0: \mu_D = 0\)
- Prueba ANOVA 1-factor entre-sujetos (15.8)
- \(H_0: \mu_1 = \mu_2 = \mu_3 = \cdots = \mu_k\)
- Correlación de Pearson (15.9)
- \(H_0: \rho = 0\)
- Correlación de Pearson (15.10)
- \(H_0: \rho_{pb} = 0\)
- Prueba \(\chi^2\) para 1 varianza (15.11)
- \(H_0: \sigma^2 = \sigma^2_0\)
- Prueba \(F\) para 2 varianzas (15.12)
- \(H_0: \sigma^2_1 = \sigma^2_2 \to \frac{\sigma^2_1}{\sigma^2_2} = 1\)
15.2.1 Supuestos y Pasos
Las pruebas presentadas en este capítulo se conocen como pruebas paramétricas, que a diferencia de las pruebas no-parámetricas que se presentan en el próximo capítulo, hacen supuestos sobre los datos que se van a analizar, siendo el mayor supuesto de que los datos siguen una distribución aproximadamente normal (o se tiene una muestra grande, \(N > 30\)), y que las muestras son aleatorias independientes (excepto en el caso de datos apareados) (Nolan & Heinzen, 2014; Triola, 2004); en algunos casos pueden haber otros supuestos (parámetros conocidos, varianzas iguales, etc.) pero en general éstos son los más importantes.
Para evaluar la “normalidad” de los datos se pueden generar gráficos como el de caja, histogramas, y QQ (Figura 15.1). El gráfico de caja muestra la mediana y los cuartiles, mientras la mediana no se encuentre muy cerca de alguno de los extremos de la caja se puede considerar normalmente distribuida; en caso de haber valores atípicos (extremos) éstos aparecerían como puntos en los extremos. El gráfico QQ hace una comparación de los valores originales con los cuantiles teóricos, la idea es que si los puntos caen cerca de la línea se puede considerar normalmente distribuida; puede que en las colas haya cierta desviación pero eso es normal siempre y cuando no sea muy extrema. El histograma se puede comparar con una curva normal y ver asimetrías, similar al de caja, mientras las asimetría sea nula o mínima se puede considerar normalmente distribuida. Hay pruebas específicas para evaluar la normalidad (Shapiro-Wilk), pero éstas tienden a ser muy sensibles a desviaciones por lo que en general es más recomendado hacer una evaluación visual
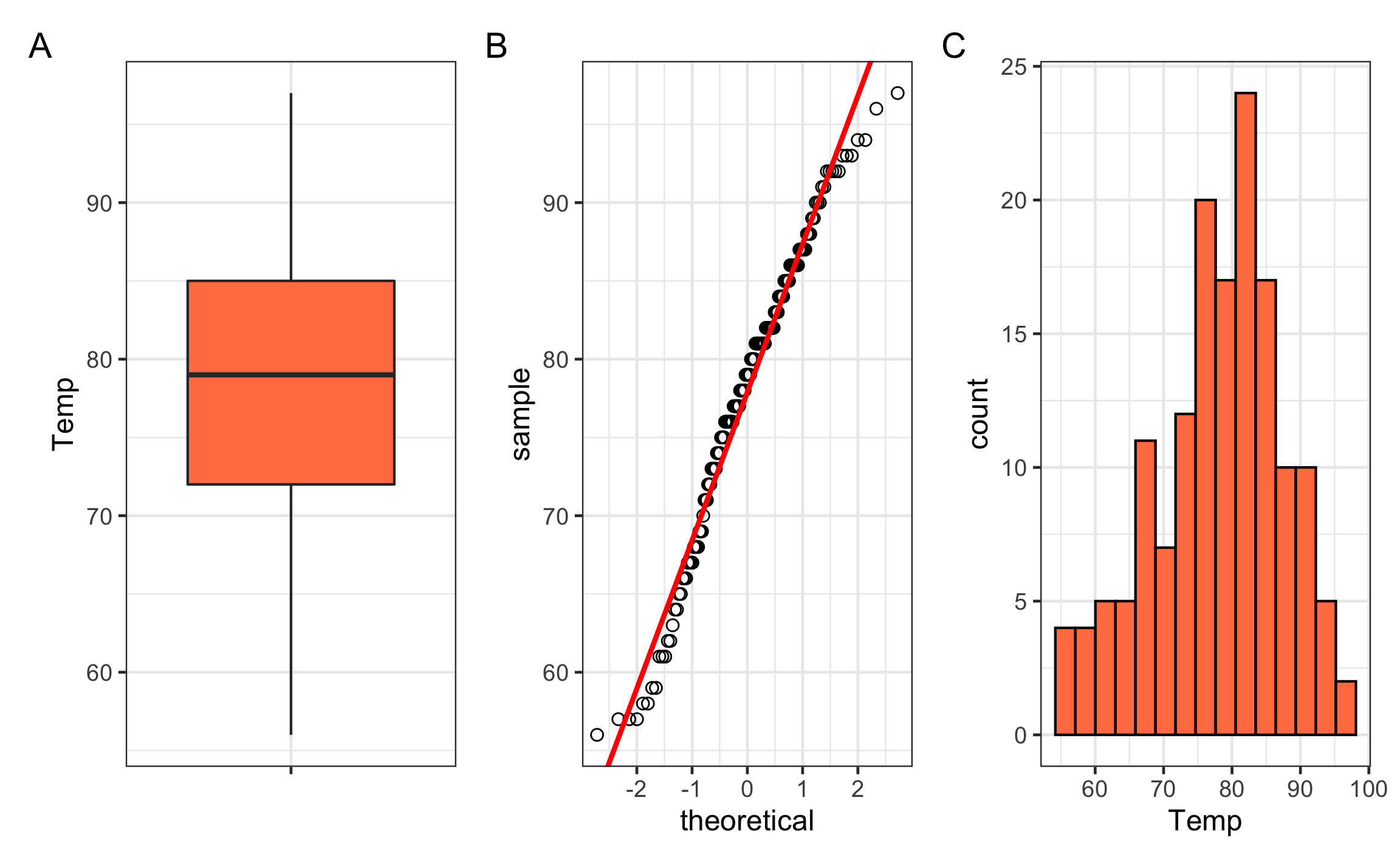
Figura 15.1: Gráficos que se pueden usar para evaluar si los datos siguen una distribución aproximandamente normal. A Gráfico de caja. B Gráfico QQ. C Histograma.
Nolan & Heinzen (2014) establecen una serie de pasos que se pueden aplicar de manera general a las pruebas estadísticas:
- Identificar la población, distribución, y la prueba apropiada:
- En función del parámetro de interés (\(\mu, \sigma^2\))
- Establecer las hipótesis nula y alterna:
- En función de la prueba escogida en el punto anterior (\(z,t,\chi^2,F\))
- Determinar parámetros de la distribución a comparar (\(H_0\)):
- En función del parámetro de interés y datos disponibles
- Determinar valores críticos
- En función de la distribución y el nivel de significancia (\(\alpha\))
- Calcular el estadístico de prueba
- En función de la prueba escogida y datos disponibles
- Aquí se puede agregar calcular los intervalos de confianza respectivos
- Tomar una decisión
- En función de valores críticos y estadístico de prueba, valor-p, o intervalos de confianza
Si se rechaza \(H_0\) se dice que hay un resultado estadísticamente significativo. Esta aseveración se refiere a que hay poca probabilidad de que los datos observados provengan de una población representada por \(H_0\). El hecho de que se rechace \(H_0\) y se obtenga un resultado estadísticamente significativo no quiere decir que éste sea importante desde el punto de vista práctico (Nolan & Heinzen, 2014). Esto último es lo que va a indicar el tamaño del efecto.
15.3 Tamaño del Efecto
Cuando una prueba da un resultado estadísticamente significativo, quiere decir que se determinó que hay una diferencia o relación. Como se mencionó en el capítulo anterior, este resultado se va a ver afectado directamente por el tamaño de la muestra, por lo que en el caso de muestras grandes casi siempre se va a encontrar un resultado estadísticamente significativo, aun cuando la diferencia o relación real sea pequeña. El tamaño del efecto (ES) es lo que indica la magnitud real de esa diferencia o relación, no se ve afectada por el tamaño de la muestra, e indica la importancia práctica de un efecto, y debe ser el objetivo a la hora de realizar análisis estadísticos (Cohen, 1988; Cumming, 2012; Cumming & Calin-Jageman, 2017; Nolan & Heinzen, 2014).
A parte de presentar los resultados de pruebas estadísticas, sea que se rechace o no la hipótesis nula, es necesario incluir el tamaño del efecto para brindar una mejor idea del resultado encontrado, así como para posibles usos en futuros estudios (meta-análisis, cálculos de tamaños de muestra, potencia, etc.), y generar una base de resultados reportados en un área específica del saber para determinar qué se puede considerar como un efecto pequeño, mediano o grande (American Psycological Association [APA] 2010; Cumming, 2012; Cumming & Calin-Jageman, 2017; Nakagawa & Cuthill, 2007; Thompson, 2007; Tomczak & Tomczak, 2014).
15.3.1 Familias de tamaño del efecto
El tamaño del efecto puede presentarse en las unidades originales o de forma estandarizada (más usadas) y se reconocen dos familias: diferencia entre medias (familia \(d\) y sus variantes), asociación/relación entre variables (familia \(r\) y similares como \(R^2, \eta^2, \omega^2, V\)), y dentro de lo posible es recomendable incluir intervalos de confianza (Cohen, 1988; Cumming, 2012; Cumming & Calin-Jageman, 2017; Lakens, 2013; Nakagawa & Cuthill, 2007). Para los tamaños de efecto es complicado calcular de forma manual los intervalos de confianza, en la mayoría de los casos se usa la distribución \(t\) no-central, por lo que se recomienda utilizar métodos computacionales (Cumming, 2012; Cumming & Calin-Jageman, 2017).
15.3.1.1 Familia \(d\)
La diferencia entre medias estandarizada se conoce como Cohen \(d\) (Cohen, 1988), de manera general se presenta en la Ecuación (15.1), y se puede visualizar en la Figura 15.2. Se interpreta de manera similar a \(Z\), donde la diferencia entre medias está dada en función de una desviación estándar. La desviación estándar (denominador) es la que va a cambiar dependiendo de la prueba y condiciones de la misma (Tabla 15.1).
\[\begin{equation} d = \frac{\bar{x}_1-\bar{x}_2}{\sigma} \tag{15.1} \end{equation}\]
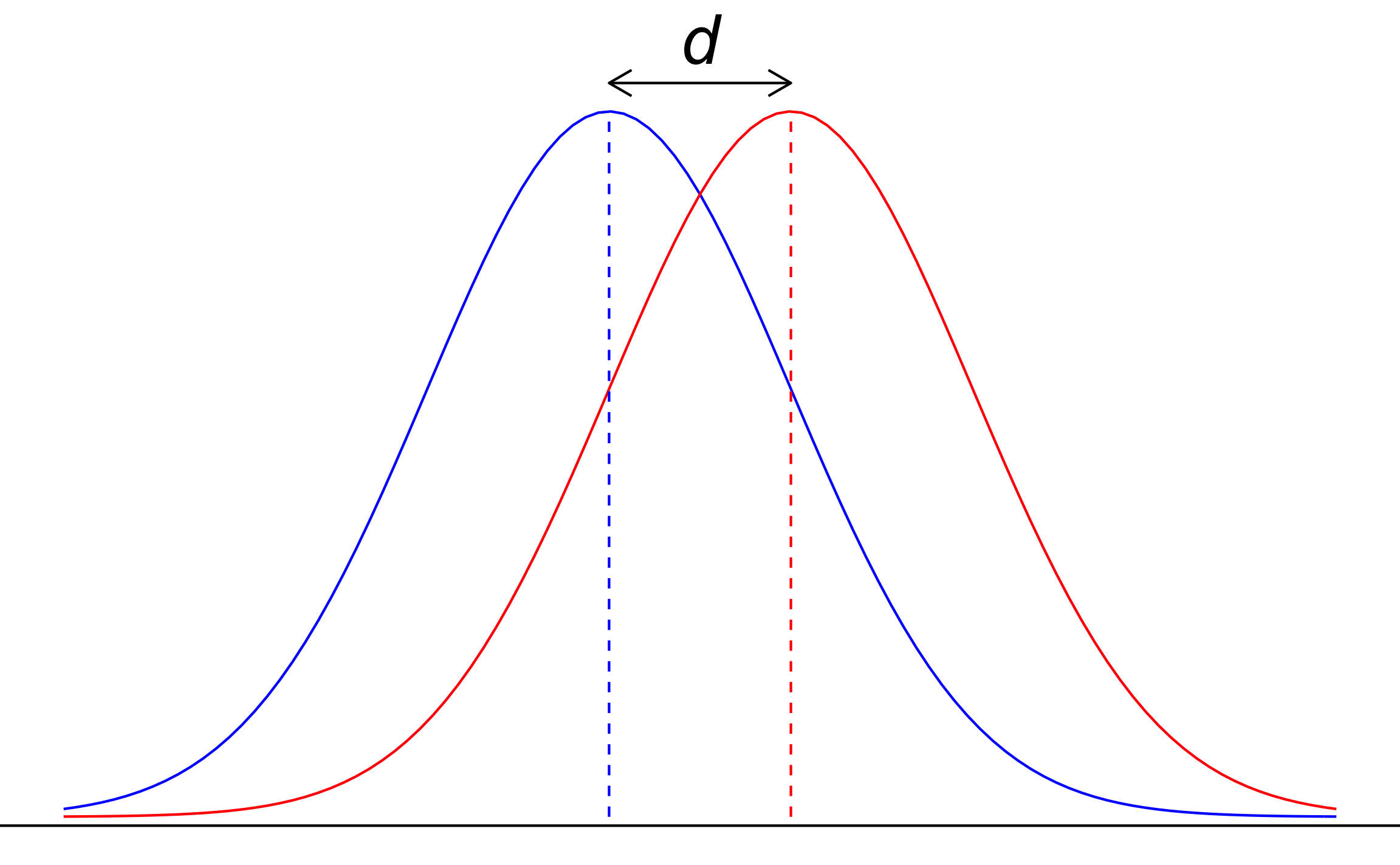
Figura 15.2: Representación del Cohen \(d\).
Hay dos factores que controlan el tamaño de \(d\), primero al incrementar la diferencia entre medias (manteniendo la dispersión constante) mayor será \(d\), segundo al disminuir la dispersión (manteniendo la diferencia de medias constante) mayor será \(d\). Estos dos factores van a influenciar el traslape entre las curvas, donde a mayor \(d\) menor el traslape y mayor la diferencia entre las curvas y las muestras. Al igual que \(Z\) puede tomar valores de \(-∞\) a \(∞\).
Dada la naturaleza estadística del Cohen \(d\) y la dificultad de su interpretación para personas con poco conocimiento estadístico, se han generado otras métricas comparables que pueden ser más fáciles de entender en términos generales. Grissom & Kim (2005), McGraw & Wong (1992), y Ruscio (2008) desarrollaron el concepto de probabilidad de superioridad (PS) o lenguaje común del tamaño del efecto (CL) el cuál se puede calcular de acuerdo a la Ecuación (15.2). Este concepto se interpreta como la probabilidad de que un elemento del grupo con media superior (elegido al azar) tenga un valor superior al de un elemento del grupo con media inferior, y al ser una probabilidad se encuentra entre 0 y 100%, conforme mayor sea \(d\) mayor será PS. Reiser & Faraggi (1999) modificaron de Cohen (1988) el traslape (OVL) entre las curvas (grupos), dado por la Ecuación (15.3), donde a mayor \(d\) menor el traslape y más diferenciados los grupos. Cohen (1988) definió el concepto de \(U_3\), denominado la medida de no-traslape, presentado en Ecuación (15.4), y se puede interpretar como el porcentaje del grupo con media superior que va a estar por encima de la media del grupo con media inferior. Para todos estos casos \(\Phi\) corresponde con la función de densidad acumulada de la distribución normal estándar \(Z\). Cabe resaltar que éstos conceptos y cálculos se basan en grupos de mismo tamaño y misma desviación estándar.Un muy buen recurso para visualizar todos estos conceptos lo brinda Magnusson (2020) en Interpreting Cohen’s d.
\[\begin{equation} PS = CL = \Phi \left( \frac{|d|}{\sqrt{2}} \right) \tag{15.2} \end{equation}\]
\[\begin{equation} OVL = 2 \Phi \left( \frac{-|d|}{2} \right) \tag{15.3} \end{equation}\]
\[\begin{equation} U_3 = \Phi \left( |d| \right) \tag{15.4} \end{equation}\]
Aquí se presenta cómo calcular estos conceptos en R, donde el único dato necesario es el \(d\).
d = 2
pnorm(abs(d)/sqrt(2))*100 # PS, CL## [1] 92.135042*pnorm(-abs(d)/2)*100 # traslape## [1] 31.73105pnorm(abs(d))*100 # U3## [1] 97.7249915.3.1.2 Familia \(r\)
Los tamaños de efecto \(r, \ r_{pb}\) y \(R^2\) se interpretan como se presentó en las secciones 10.3 y 10.4.4.2, respectivamente. \(\eta^2\) y \(\omega^2\) se interpretan igual a \(R^2\), como el porcentaje de variación en la variable respuesta explicado por la variable predictora (Cohen, 1988; Lakens, 2013; Tomczak & Tomczak, 2014).
15.3.2 Ecuaciones para tamaños de efecto
Muchos autores han trabajado en este tema, proponiendo mejoras a los tamaños de efecto inicialmente planteados y resumiendo los diferentes tamaños de efecto para las diferentes pruebas y condiciones (Cohen, 1988; Cumming, 2012; Cumming & Calin-Jageman, 2017; Ellis, 2010; Fritz et al., 2012; Grissom & Kim, 2005; Hedges & Olkin, 1985; Lakens, 2013; McGrath & Meyer, 2006; McGraw & Wong, 1992; Nakagawa & Cuthill, 2007; Sheskin, 2011; Thompson, 2007; Tomczak & Tomczak, 2014; Zou, 2007). Aquí se presenta un resumen de los diferentes tamaños de efecto (Tabla 15.1) y se remite al lector a revisar las referencias aquí mencionadas y las que se incluyen en las mismas, en el caso de querer ahondar en alguno de los casos presentados.
| Prueba | Tamaño de efecto |
|---|---|
| Z de 1 muestra | \[\begin{equation} d_{pop} = \frac{\bar{x}-\mu_0}{\sigma} \tag{15.5} \end{equation}\] |
| t de 1 muestra | \[\begin{equation} d_s = \frac{\bar{x}-\mu_0}{s} \tag{15.6} \end{equation}\] |
| t de 2 muestras independientes | \[\begin{equation} d_s = \frac{\bar{x}_1-\bar{x}_2}{\sqrt{\frac{(n_1-1)s_1^2 + (n_2-1)s_2^2}{n_1 + n_2 - 2}}} \tag{15.7} \end{equation}\] |
| t de 2 muestras dependientes usando la desviación de las diferencias | \[\begin{equation} d_z = \frac{\bar{d}}{s_d} \tag{15.8} \end{equation}\] |
| t de 2 muestras dependientes tomando en cuenta la correlación | \[\begin{equation} d_{rm} = \frac{\bar{d}}{\sqrt{s_1^2 + s_2^2 - 2 \cdot r \cdot s_1 \cdot s_2}}\sqrt{2(1-r)} \tag{15.9} \end{equation}\] |
| t de 2 muestras dependientes usando el promedio de las desviaciones | \[\begin{equation} d_{av} = \frac{\bar{d}}{\sqrt{\frac{s_1^2 + s_2^2}{2}}} \tag{15.10} \end{equation}\] |
| t con corrección de Hedges | \[\begin{equation} g = d \cdot \left( 1 - \frac{3}{4v-1} \right) = d \cdot \left( \frac{N-3}{N-2.25} \right) \tag{15.11} \end{equation}\] |
| Correlación punto biserial | \[\begin{equation} r_{pb} = \frac{\bar{y}_1-\bar{y}_0}{s_y}\sqrt{\frac{n_1 n_0}{N(N-1)}} \tag{15.12} \end{equation}\] |
| Correlación | \[\begin{equation} r = \frac{\sum Z_xZ_y}{N-1} \tag{15.13} \end{equation}\] |
| Regresión | \[\begin{equation} R^2 \tag{15.14} \end{equation}\] |
| ANOVA | \[\begin{equation} \eta^2 = \frac{SC_{efecto}}{SC_{total}} \tag{15.15} \end{equation}\] |
| \[\begin{equation} \eta_p^2 = \frac{SC_{efecto}}{SC_{efecto}+SC_{error}} \tag{15.16} \end{equation}\] | |
| \[\begin{equation} \omega^2 = \frac{v_{efecto}(CM_{efecto}-CM_{error})}{SC_{total}+CM_{error}} \tag{15.17} \end{equation}\] | |
| \[\begin{equation} \omega_p^2 = \frac{v_{efecto}(CM_{efecto}-CM_{error})}{v_{efecto}CM_{efecto} + (N - v_{efecto})CM_{error}} \tag{15.18} \end{equation}\] | |
| Notas: | |
| \(\mu_0\) = media poblacional | |
| \(\sigma\) = desviación estándar poblacional | |
| \(\bar{x}_1\) = media de muestra 1 | |
| \(\bar{x}_2\) = media de muestra 2 | |
| \(s_1\) = desviación estándar de muestra 1 | |
| \(s_2\) = desviación estándar de muestra 2 | |
| \(s_1^2\) = varianza de muestra 1 | |
| \(s_2^2\) = varianza de muestra 2 | |
| \(n_1\) = tamaño de muestra 1 | |
| \(n_2\) = tamaño de muestra 2 | |
| \(N\) = total de observaciones | |
| \(v\) = grados de libertad | |
| \(\bar{d}\) = media de la diferencia entre muestras | |
| \(s_d\) = desviación estándar de la diferencia entre muestras | |
| \(r\) = coeficiente de correlación de Pearson | |
| \(r_{pb}\) = coeficiente de correlación punto biserial | |
| \(Z_x\) = variable x estandarizada | |
| \(Z_y\) = variable y estandarizada | |
| \(\bar{y}_1\) = desviación estándar de la variable respuesta de grupo 1 | |
| \(\bar{y}_2\) = desviación estándar de la variable respuesta de grupo 2 | |
| \(s_y\) = desviación estándar de la variable respuesta | |
| \(SC\) = suma de cuadrados en ANOVA | |
| \(CM\) = cuadrados medios en ANOVA |
La corrección de Hedges (\(g\)) se usa ya que \(d\) se considera un estimador sesgado (biased) especialmente para muestras pequeñas, conforme mayor sea el tamaño de muestra más similares \(d\) y \(g\) (Cumming, 2012; Cumming & Calin-Jageman, 2017; Fritz et al., 2012; McGrath & Meyer, 2006). De manera similar \(\omega^2\) corresponde con un estimador insesgado o menos sesgado de \(\eta^2\) (Fritz et al., 2012; Lakens, 2013; Olejnik & Algina, 2000; Tomczak & Tomczak, 2014).
Así como se puede calcular el tamaño del efecto a partir de los datos, en algunos casos se puede calcular el tamaño del efecto a partir de los resultados de pruebas estadísticas u otros tamaños de efecto. Esta relación se muestra en la Tabla 15.2. En su mayoría estas relaciones son de utilidad cuando se revisan o quieren comparar estudios que reportan únicamente resultados de pruebas estadísticas pero no así el tamaño del efecto.
| Prueba | Tamaño de efecto |
|---|---|
| t de 1 muestra | \[\begin{equation} d_s = \frac{t}{\sqrt{N}} \tag{15.19} \end{equation}\] |
| t de 2 muestras independientes | \[\begin{equation} d_s = t\sqrt{\frac{1}{n_1} + \frac{1}{n_2}} \sim \frac{2t}{\sqrt{N}} \tag{15.20} \end{equation}\] |
| t de 2 muestras dependientes usando la desviación de las diferencias | \[\begin{equation} d_z = \frac{t}{\sqrt{N}} \tag{15.21} \end{equation}\] |
| t de 2 muestras dependientes tomando en cuenta la correlación | \[\begin{equation} d_{rm} = t\sqrt{\frac{2(1-r)}{N}} \tag{15.22} \end{equation}\] |
| Correlación punto biserial | \[\begin{equation} r_{pb} = \frac{d_s}{\sqrt{d_s^2 + \frac{N^2-2N}{n_1 n_2}}} \tag{15.23} \end{equation}\] |
| ANOVA 1-factor con 2 grupos | \[\begin{equation} \eta_p^2 = r_{pb}^2 = \frac{t^2}{t^2+v} \tag{15.24} \end{equation}\] |
| Notas: | |
| \(t\) = estadístico de la prueba respectiva | |
| \(n_1\) = tamaño de muestra 1 | |
| \(n_2\) = tamaño de muestra 2 | |
| \(N\) = total de observaciones | |
| \(r\) = coeficiente de correlación de Pearson | |
| \(r_{pb}\) = coeficiente de correlación punto biserial | |
| \(d_s\) = Cohen d para 2 muestras independientes | |
| \(v\) = grados de libertad |
15.3.3 Clasificación de tamaños de efecto
Una pregunta que puede surgir es qué magnitud de los diferentes tamaños de efecto se puede considerar pequeña, mediana, o grande. Cohen (1988) sugirió unos valores que se pueden usar como guías (Tabla 15.3), los cuales han surgido y fueron determinados como tales en las ciencias sociales. El mismo autor advierte sobre utilizar estos valores como definitivos y estrictos, y menciona que se debe aplicar criterio de experto en el área específica para determinar qué califica como pequeño, mediano, o grande.
| Prueba | Tamaño de efecto | Pequeño | Mediano | Grande |
|---|---|---|---|---|
| Comparación de medias | \(d\), \(g\) | 0.20 | 0.50 | 0.80 |
| Correlación | \(r\) | .10 | .30 | .50 |
| \(R^2\) | .01 | .09 | .25 | |
| \(r_{pb}\) | .10 | .24 | .37 | |
| Regresión | \(R^2\) | .02 | .13 | .26 |
| ANOVA | \(\eta^2\), \(\omega^2\) | .01 | .06 | .14 |
| Nota: Conforme Cohen (1988) |
15.3.4 Importancia del tamaño del efecto
La importancia de reporat y utilizar tamaños de efecto para comparar resultados en diferentes estudios se presenta con un ejemplo sencillo pero ilustrativo.
Se tienen dos estudios (A y B) que analizaron el mismo fenómeno, por medio de una prueba \(t\) de 2 muestras independientes. El estudio A reportó lo siguiente: \(t(79)=2.21, p<.05\), mientras que el estudio B reportó lo siguiente: \(t(18)=1.06, p>.3\).
A primera vista se podría concluir que los resultados de ambos estudios no coinciden y encontraron efectos diferentes. ¿Qué pasa con el tamaño del efecto? Si calculamos \(d\) a aprtir de la Ecuación (15.20) para ambos estudios tenemos lo siguiente:
\[\begin{equation} d_s = \frac{2t}{\sqrt{N}}\\ d_{sA} = \frac{2t_A}{\sqrt{N_A}} = \frac{2 \cdot 2.21}{\sqrt{80}} = 0.49\\ d_{sB} = \frac{2t_B}{\sqrt{N_B}} = \frac{2 \cdot 1.06}{\sqrt{20}} = 0.47\\ \end{equation}\]
Al ver estos resultados se puede concluir que ambos estudios encontraron el mismo efecto (significancia práctica), la diferencia está simplemente en que el estudio B no tenía la sufuciente potencia (tamaño de muestra) para encontrar una significancia estadística.
Lo anterior deja claro que no se puede fiar únicamente en resultados de pruebas estadísticas (especialmente el valor-p) para comparar estudios, se necesita toda la información disponible y el tamaño del efecto.
15.4 \(z\) de 1 muestra
El uso de la prueba \(z\) de 1 muestra se realiza con el ejemplo de la sección 14.2.1.1 (Walpole et al., 2012), donde se tenía una media muestral de \(2.6 \ g/ml\) para una muestra de tamaño 36 y se asumía una desviación poblacional de \(0.3 \ g/ml\). Es posible que esta muestra provenga de una población con media 2.8 (\(\mu_0=2.8\))? Asuma \(\alpha = .05\).
Usando los pasos mencionados anteriormente (15.2.1) se tiene:
- Identificar la población, distribución, y la prueba apropiada:
- Población: concentración de zinc en un río
- Distribución: de medias
- Prueba: \(Z\) de 1 muestra porque se tiene 1 muestra, se quiere comparar con un valor hipotético, y se tiene \(\sigma\)
- Establecer las hipótesis nula y alterna:
- \(H_0: \mu = \mu_0 \to\) La concentración de zinc en el río es igual a un valor hipotético o conocido (2.8)
- \(H_1: \mu \neq \mu_0 \to\) La concentración de zinc en el río es diferente a un valor hipotético o conocido (2.8)
- Determinar parámetros de la distribución a comparar (\(H_0\)):
- \(\mu_0 = 2.8\)
- \(\sigma_\bar{x} = \frac{\sigma}{\sqrt{n}} = \frac{0.3}{\sqrt{36}} = 0.05\)
- Determinar valores críticos
- \(\alpha = .05\)
- \(z_{\alpha/2} = z_{.05/2} = |1.96|\)
- Calcular el estadístico de prueba
- \(Z = \frac{\bar{x} - \mu}{\sigma_\bar{x}} = \frac{2.6 - 2.8}{0.05} = -4\)
- \(2.6 \pm 0.1 \to 95\% \ IC \ [2.50,2.70]\)
- Tomar una decisión
- El estadístico de prueba es mayor al crítico, \(z > z_{\alpha/2}\)
- El valor-p es menor a \(\alpha = .05\), \(p < .001\)
- El valor hipotético del parámetro cae fuera del intervalo de confianza, \(IC \ [2.50,2.70]\)
- Decisión: Se rechaza \(H_0\)
En R el paquete DescTools tiene la función ZTest para realizar esta prueba, pero necesita un vector de datos, por lo que se genera un vector aleatorio, y se demuestra a continuación.
x = 2.6
n = 36
sig = 0.3
mu0 = 2.8
a = 0.05
set.seed(123)
vec = rnorm(n = n, mean = x, sd = sig)
z1.res = ZTest(vec,
mu = mu0, # valor del parámetro a comparar
sd_pop = sig, # deviación poblacional
conf.level = 1-a) # nivel de confianza
z1.res##
## One Sample z-test
##
## data: vec
## z = -3.6664, Std. Dev. Population = 0.3, p-value = 0.000246
## alternative hypothesis: true mean is not equal to 2.8
## 95 percent confidence interval:
## 2.518683 2.714680
## sample estimates:
## mean of x
## 2.616681El tamaño del efecto se puede calcular de acuerdo a la Ecuación (15.5) de la siguiente manera:
\[\begin{equation} d_{pop} = \frac{\bar{x}-\mu_0}{\sigma}\\ d_{pop} = \frac{2.6-2.8}{0.3} = -0.67 \end{equation}\]
En R se puede calcular de forma básica y el intervalo de confianza con la función d.ci del paquete psych (Revelle, 2020), donde es necesario indicar \(d\) y \(n\).
dpop = (x - mu0) / sig
dpop.ci = d.ci(dpop,n1=n) %>% round(2)
dpop.ci## lower effect upper
## [1,] -1.02 -0.67 -0.3Usando las medidas PS, OVL, y \(U_3\) (Figura 15.3).
## # A tibble: 1 x 3
## PS OVL U3
## <dbl> <dbl> <dbl>
## 1 68.1 73.9 74.8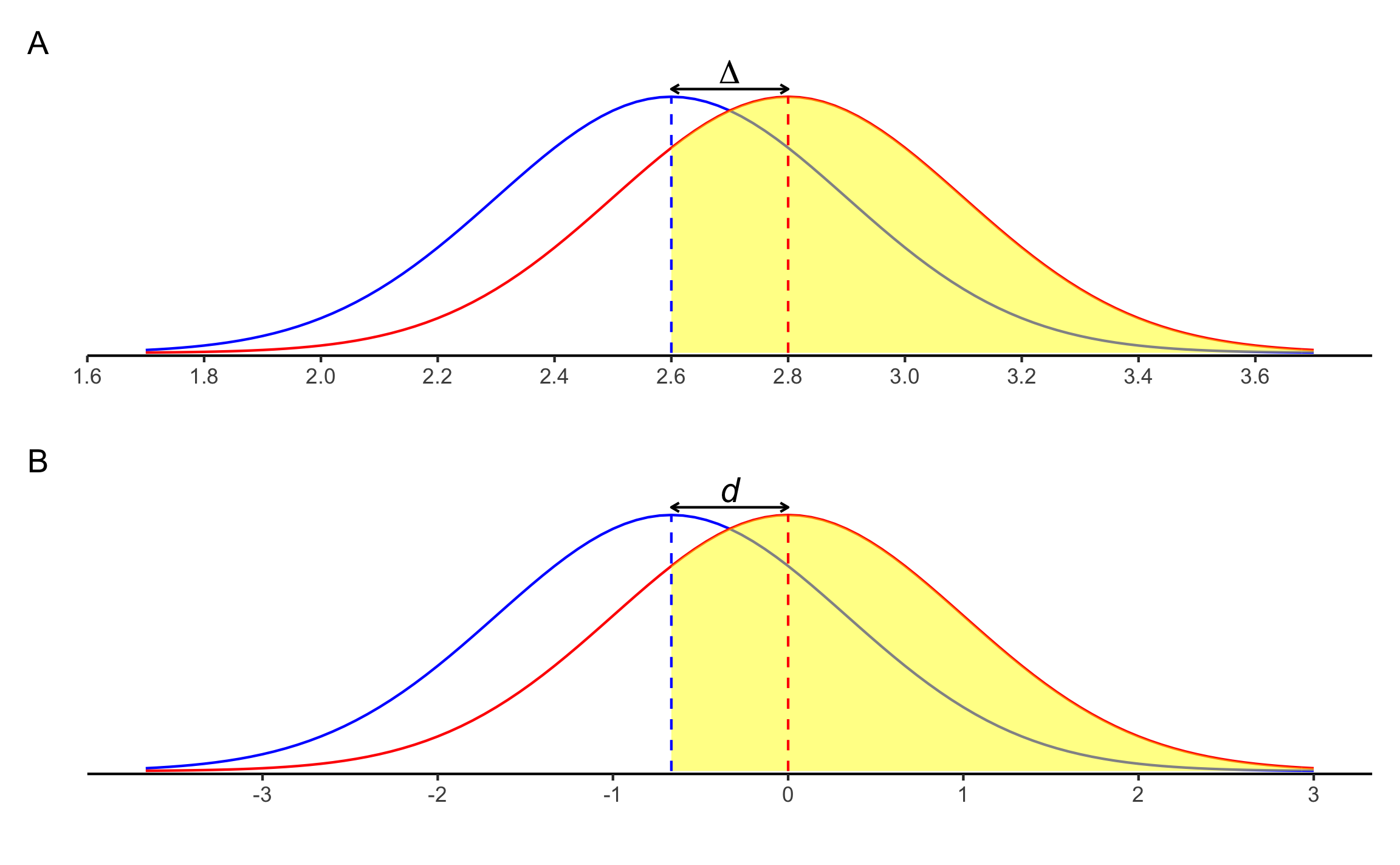
Figura 15.3: \(U_3\) para el ejemplo de la prueba \(z\) de 1 muestra. A Corresponde con los datos en escala original. B Corresponde con el tamaño del efecto \(d\).
Conclusión: La concentración de zinc (\(M = 2.62\), 95% IC \([2.52\), \(2.71]\)) es significativamente diferente a la media de 2.8 g/ml, \(z(36) = -3.67\), \(p < .001\), \(d = -0.67 \ [-1.02, -0.3]\). El efecto se puede considerar mediano, pero con un rango de pequeño hasta muy grande. Hay una probabilidad de 68.1% (PS) que un elemento de la población hipotética tenga una concentración mayor a un elemento de la muestra; las dos curvas se traslapan en un 73.9% (OVL); el 74.8% (\(U_3\)) de la población hipotética se encuentra por encima de la media de la muestra.
15.5 \(t\) de 1 muestra
El uso de la prueba \(t\) de 1 muestra se realiza con el ejemplo de la sección 14.2.1.2 (Swan & Sandilands, 1995), donde se tenía el contenido de cuarzo en secciones delgadas de una roca ígnea. Es posible que esta muestra provenga de una población con media 20% (\(\mu_0=20\))? Asuma \(\alpha = .05\).
- Identificar la población, distribución, y la prueba apropiada:
- Población: contenido de cuarzo en la roca ígnea
- Distribución: de medias
- Prueba: \(t\) de 1 muestra porque se tiene 1 muestra, se quiere comparar con un valor hipotético, y no se tiene \(\sigma\)
- Establecer las hipótesis nula y alterna:
- \(H_0: \mu = \mu_0 \to\) El contenido de cuarzo en la roca ígnea es igual a un valor hipotético o conocido (20)
- \(H_1: \mu \neq \mu_0 \to\) El contenido de cuarzo en la roca ígnea es diferente a un valor hipotético o conocido (20)
- Determinar parámetros de la distribución a comparar (\(H_0\)):
- \(\mu_0 = 20\)
- \(s_\bar{x} = \frac{s}{\sqrt{n}} = \frac{3.083}{\sqrt{8}} = 1.09\)
- Determinar valores críticos
- \(\alpha = .05\)
- \(t_{\alpha/2,v} = t_{.05/2,7} = |2.365|\)
- Calcular el estadístico de prueba
- \(t = \frac{\bar{x} - \mu}{s_\bar{x}} = \frac{21.5 - 20}{1.09} = 1.37\)
- \(21.512 \pm 2.578 \to 95\% \ IC \ [18.93, 24.09]\)
- Tomar una decisión
- El estadístico de prueba es menor al crítico, \(t < t_{\alpha/2,v}\)
- El valor-p es mayor a \(\alpha = .05\), \(p = .2079\)
- El valor hipotético del parámetro cae dentro del intervalo de confianza, \(IC \ [18.93, 24.09]\)
- Decisión: No se rechaza \(H_0\)
R trae la función t.test que puede realizar las diferentes pruebas \(t\). Para el caso de 1 muestra se brinda el vector de datos, la media poblacional con la cual comparar (mu), y el nivel de confianza.
mu0 = 20
a = 0.05
cuarzo = c(23.5, 16.6, 25.4, 19.1, 19.3, 22.4, 20.9, 24.9)
t1.res = t.test(cuarzo,
mu = mu0,
conf.level = 1-a)
t1.res##
## One Sample t-test
##
## data: cuarzo
## t = 1.3875, df = 7, p-value = 0.2079
## alternative hypothesis: true mean is not equal to 20
## 95 percent confidence interval:
## 18.93477 24.09023
## sample estimates:
## mean of x
## 21.5125El tamaño del efecto se puede calcular de acuerdo a la Ecuación (15.6) de la siguiente manera:
\[\begin{equation} d_s = \frac{\bar{x}-\mu_0}{s}\\ d_s = \frac{21.5-20}{3.083} = 0.49 \end{equation}\]
En R se puede calcular con la función d.single.t del paquete MOTE (Buchanan et al., 2019), donde es necesario indicar la media muestral, media poblacional a comparar, desviación estándar muestral, tamaño de la muestra, y nivel de significancia.
d.t1.res = d.single.t(m = mean(cuarzo),
u = mu0,
sd = sd(cuarzo),
n = length(cuarzo),
a = a)
d.t1.res[1:3] %>% unlist()## d dlow dhigh
## 0.4905400 -0.2619016 1.2128190Usando las medidas PS, OVL, y \(U_3\) (Figura 15.4).
## # A tibble: 1 x 3
## PS OVL U3
## <dbl> <dbl> <dbl>
## 1 63.6 80.6 68.8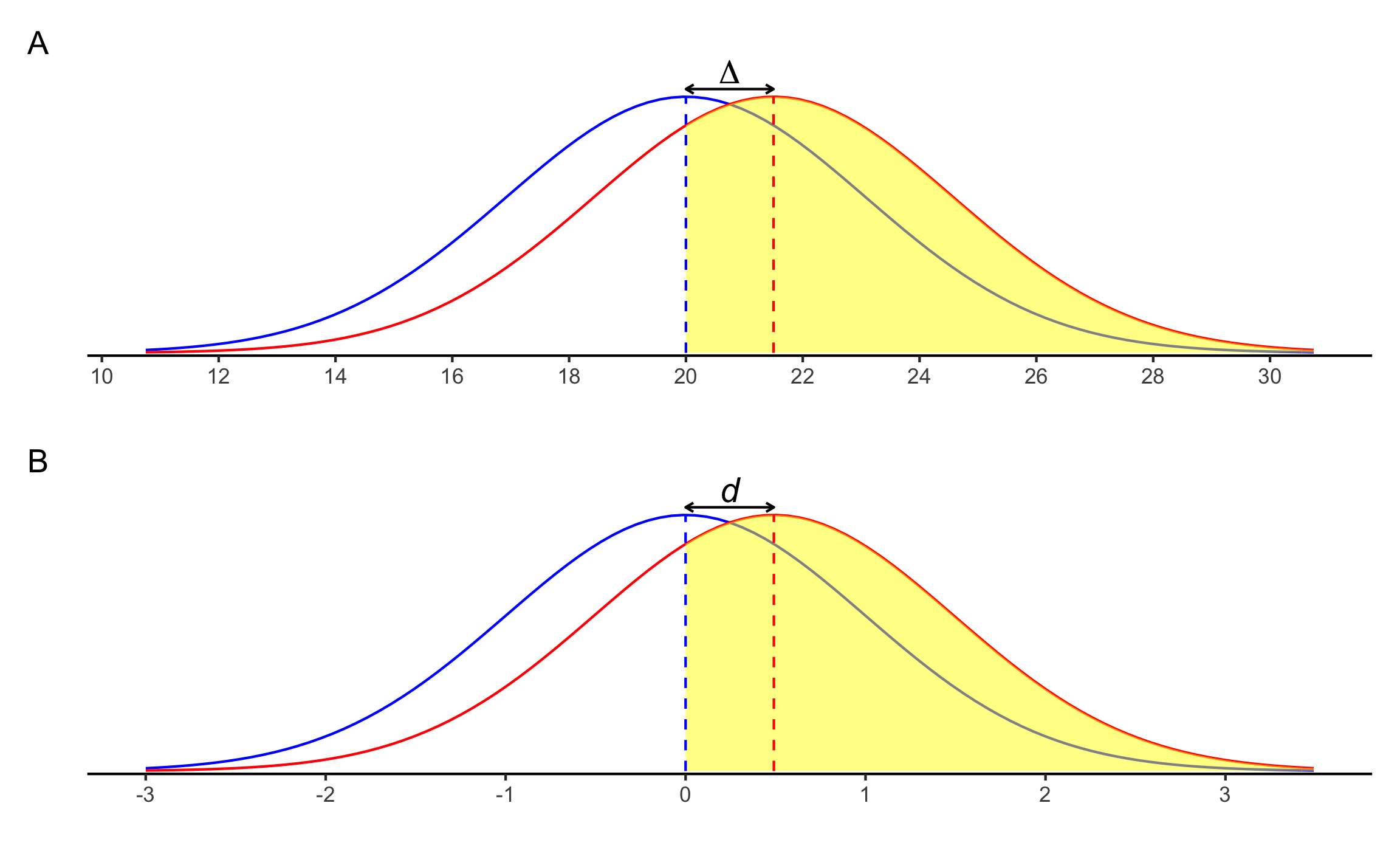
Figura 15.4: \(U_3\) para el ejemplo de la prueba \(t\) de 1 muestra. A Corresponde con los datos en escala original. B Corresponde con el tamaño del efecto \(d\).
Conclusión: El contenido de cuarzo de la roca ígnea (\(M = 21.51\), 95% IC \([18.93\), \(24.09]\)) no es significativamente diferente a la media de 20% , \(t(7) = 1.39\), \(p = .208\), \(d\) = 0.49 \([-0.26, 1.21]\). El efecto se puede considerar mediano, pero con un rango de pequeño, en dirección opuesta, hasta muy grande. Hay una probabilidad de 63.6% (PS) que un elemento de la muestra tenga un contenido de cuarzo mayor a un elemento de la población hipotética; las dos curvas se traslapan en un 80.6% (OVL); el 68.8% (\(U_3\)) de la muestra se encuentra por encima de la media de la población hipotética.
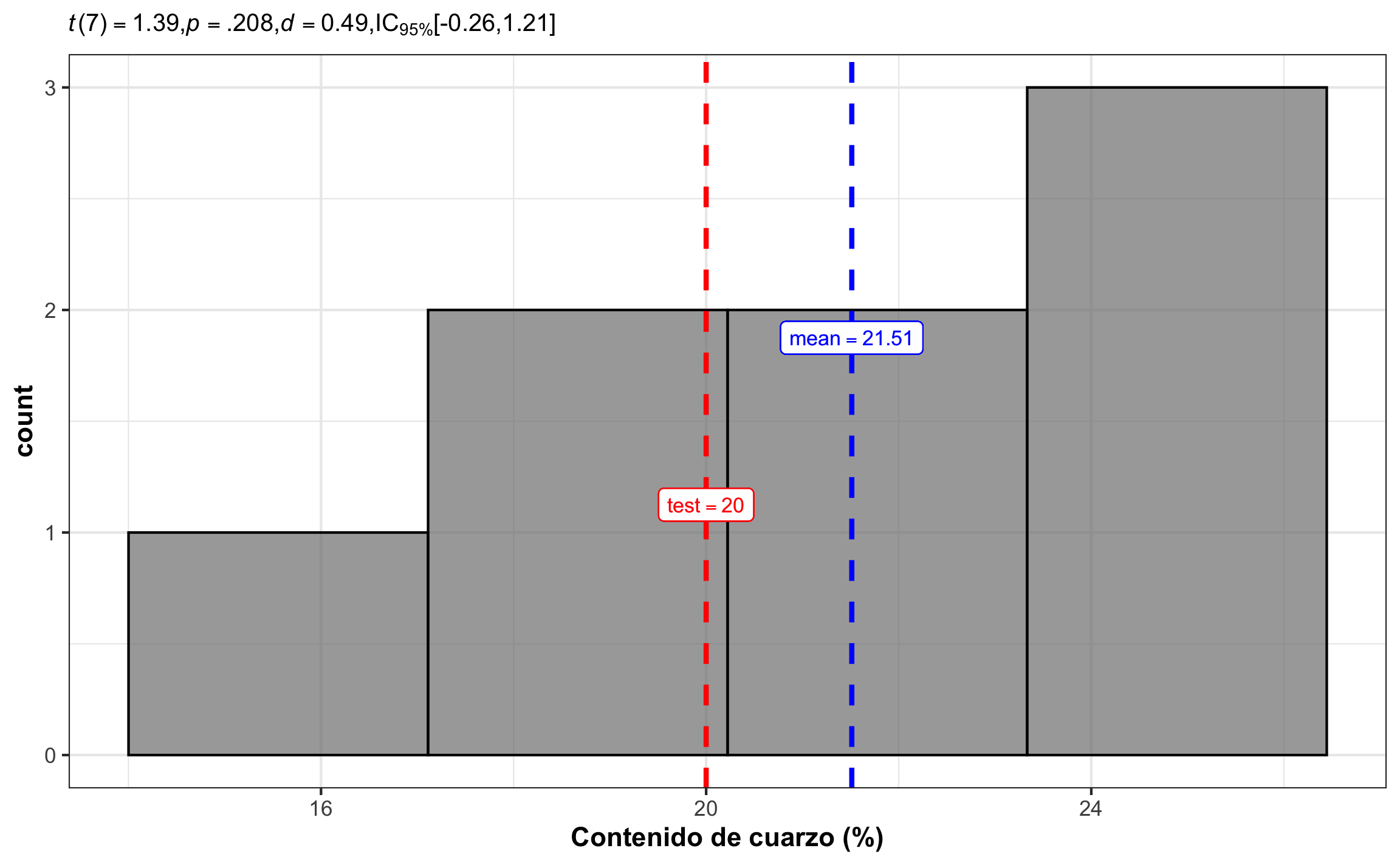
Figura 15.5: Histograma del contenido de cuarzo, mostrando la media muestral (azul) y el valor a comparar (rojo), así como el resumen estadístico respectivo.
15.6 \(t\) de 2 muestras independientes
Para este caso es cuando, en teoría, se debiera cumplir no solo la normalidad de las muestras, sino también la igualdad de varianzas. Si se quiere relajar el supuesto de igualdad de varianzas se usa el estadístico Welch o Welch-Satterthwaite (14.2.2.2.1 - varianzas diferentes). En general la diferencia entre asumir igualdad de varianzas o no va a ser pequeña, siempre y cuando éstas no sean muy diferentes y los tamaños de muestra no sean muy disparejos, y es recomendado indicar qué método se usó (Cumming & Calin-Jageman, 2017).
El uso de la prueba \(t\) de 2 muestras independientes se realiza con el ejemplo de la sección 14.2.2.2.1 (Swan & Sandilands, 1995), el de varianzas iguales, donde se tenían braquiópodos en dos capas (A, B) y se les midió la longitud (cm). Es posible que estas muestras provenga de una misma población (\(\mu_1=\mu_2\))? Asuma \(\alpha = .05\).
- Identificar la población, distribución, y la prueba apropiada:
- Población: braquiópodos en capas A y B
- Distribución: diferencia de medias
- Prueba: \(t\) de 2 muestras independientes porque se tienen 2 muestras, y las dos provienen de sitios diferentes (independientes uno del otro)
- Establecer las hipótesis nula y alterna:
- \(H_0: \mu_1 = \mu_2 \to\) La longitud e los braquiópodos en la capa A es igual a la longitud e los braquiópodos en la capa B
- \(H_1: \mu \neq \mu_0 \to\) La longitud e los braquiópodos en la capa A es diferente la longitud e los braquiópodos en la capa B
- Determinar parámetros de la distribución a comparar (\(H_0\)):
- \(\mu_1 - \mu_2 = 0\)
- \(s_p = \sqrt{\frac{(n_1-1)s_1^2 + (n_2-1)s_2^2}{n_1 + n_2 - 2}} = \sqrt{\frac{(8-1)0.042 + (10-1)0.029}{8 + 10 - 2}} = 0.1865\)
- \(s_{\bar{x}_1-\bar{x}_2} = s_p \sqrt{\frac{1}{n_1} + \frac{1}{n_2}} = 0.1865 \sqrt{\frac{1}{8} + \frac{1}{10}} = 0.0885\)
- Determinar valores críticos
- \(\alpha = .05\)
- \(t_{\alpha/2,v} = t_{.05/2,16} = |2.12|\)
- Calcular el estadístico de prueba
- \(t = \frac{(\bar{x}_1-\bar{x}_2) - (\mu_1-\mu_2)}{s_{\bar{x}_1-\bar{x}_2}} = \frac{(3.125-2.96) - 0}{0.0885} = 1.86\)
- \(0.165 \pm 0.1876 \to 95\% \ IC \ [-0.023,0.353]\)
- Tomar una decisión
- El estadístico de prueba es menor al crítico, \(t < t_{\alpha/2,v}\)
- El valor-p es mayor a \(\alpha = .05\), \(p = .081\)
- El valor de \(0\) cae dentro del intervalo de confianza, \(IC \ [-0.023,0.353]\)
- Decisión: No se rechaza \(H_0\)
R trae la función t.test que puede realizar las diferentes pruebas \(t\). Para el caso de 2 muestras independientes se brindan los vectores de datos, el indicador lógico de si las varianzas se deben considerar iguales, y el nivel de confianza.
a = 0.05
A = c(3.2, 3.1, 3.1, 3.3, 2.9, 2.9, 3.5, 3.0)
B = c(3.1, 3.1, 2.8, 3.1, 3.0, 2.6, 3.0, 3.0, 3.1, 2.8)
braq = stack(list(A=A,
B=B))
t2.ind.res = t.test(x = A,
y = B,
var.equal = T,
conf.level = 1-a)
t2.ind.res##
## Two Sample t-test
##
## data: A and B
## t = 1.861, df = 16, p-value = 0.08122
## alternative hypothesis: true difference in means is not equal to 0
## 95 percent confidence interval:
## -0.02295489 0.35295489
## sample estimates:
## mean of x mean of y
## 3.125 2.960Como se mencionó en la sección 14.2.2.2.1, las pruebas de hipótesis se pueden aproximar por medio de la estimación, más específicamente, los intervalos de confianza (Figura 15.6), siguiendo las guías de Cumming & Finch (2005), Cumming (2012), y Cumming & Calin-Jageman (2017). El intervalo de confianza para el parámetro de interés se puede comparar con \(H_0\), y se puede obtener la misma conclusión a realizar la prueba estadística.
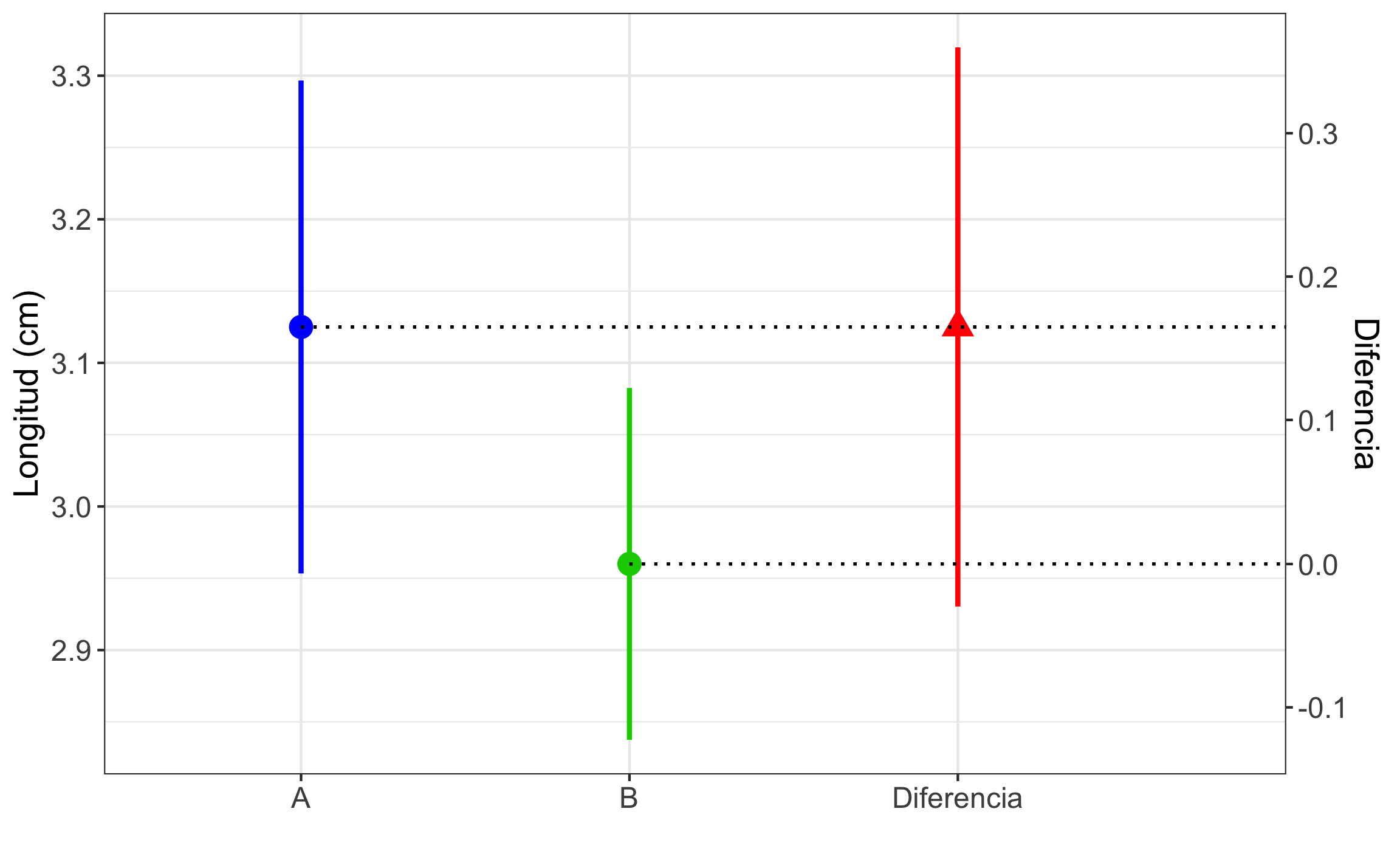
Figura 15.6: Intervalos de confianza para la prueba t de 2 muestras independientes. El valor de 0 cae dentro del intervalo de confianza para la diferencia, por lo que se pueden considerar iguales o que no hay diferencia entre las capas.
El tamaño del efecto se puede calcular de acuerdo a las Ecuaciones (15.7) y (15.11), donde de manera general se usa la desviación agrupada (pooled standard deviation ,\(s_p\)) como el estandarizador, sin importar si se asumen varianzas iguales o no para la prueba, pero es buena práctica reportar qué se uso como estandarizador (Cumming & Calin-Jageman, 2017).
\[\begin{equation} d_s = \frac{\bar{x}_1-\bar{x}_2}{\sqrt{\frac{(n_1-1)s_1^2 + (n_2-1)s_2^2}{n_1 + n_2 - 2}}}\\ d_s = \frac{3.125-2.96}{\sqrt{\frac{(8-1)0.042 + (10-1)0.029}{8 + 10 - 2}}} = 0.88 \end{equation}\]
\[\begin{equation} g_s = d_s \cdot \left( 1 - \frac{3}{4v-1} \right)\\ g_s = 0.88 \cdot \left( 1 - \frac{3}{4(16)-1} \right) = 0.84 \end{equation}\]
En R se puede calcular \(d_s\) con la función d.ind.t y \(g_s\) con la función g.ind.t del paquete MOTE, donde es necesario indicar la media muestral de ambas muestras, desviación estándar muestral de ambas muestras, tamaño ambas muestras, y nivel de significancia. Adicionalmente existen las funciones cohens_d y hedges_g de effectsize (Ben-Shachar et al., 2020), y cohen.d de effsize (Torchiano, 2018).
Usando MOTE
d.t2.ind.res = d.ind.t(m1 = mean(A), m2 = mean(B),
sd1 = sd(A), sd2 = sd(B),
n1 = length(A), n2 = length(B),
a = a)
d.t2.ind.res[1:3] %>% unlist()## d dlow dhigh
## 0.8827506 -0.1075693 1.8483100g.t2.ind.res = g.ind.t(m1 = mean(A), m2 = mean(B),
sd1 = sd(A), sd2 = sd(B),
n1 = length(A), n2 = length(B),
a = a)
g.t2.ind.res[1:3] %>% unlist()## d dlow dhigh
## 0.8407149 -0.1024469 1.7602953Usando effectsize
cohens_d(A,B,
ci = 1-a)## # A tibble: 1 x 4
## Cohens_d CI CI_low CI_high
## <dbl> <dbl> <dbl> <dbl>
## 1 0.883 0.95 -0.108 1.85hedges_g(A,B,
ci = 1-a)## # A tibble: 1 x 4
## Hedges_g CI CI_low CI_high
## <dbl> <dbl> <dbl> <dbl>
## 1 0.841 0.95 -0.102 1.76Usando effsize
cohen.d(A,B,
conf.level = 1-a,
noncentral=T)##
## Cohen's d
##
## d estimate: 0.8827506 (large)
## 95 percent confidence interval:
## lower upper
## -0.1075693 1.8483100cohen.d(A,B,
conf.level = 1-a,
hedges.correction = T,
noncentral=T)##
## Hedges's g
##
## g estimate: 0.8407149 (large)
## 95 percent confidence interval:
## lower upper
## -0.1075693 1.8483100Usando las medidas PS, OVL, y \(U_3\) (Figura 15.7).
## # A tibble: 1 x 3
## PS OVL U3
## <dbl> <dbl> <dbl>
## 1 73.4 65.9 81.1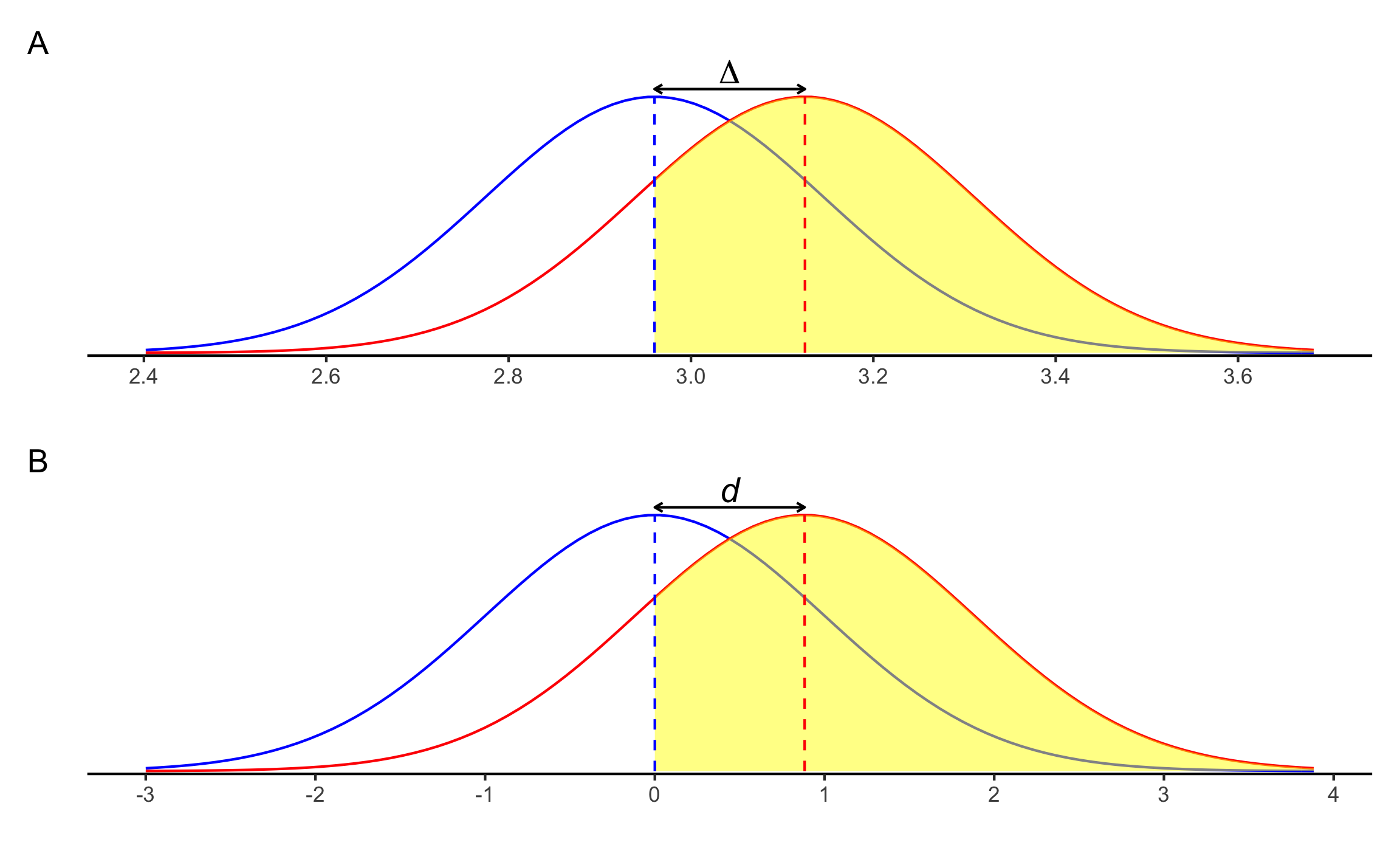
Figura 15.7: \(U_3\) para el ejemplo de la prueba \(t\) de 2 muestras independientes. A Corresponde con los datos en escala original. B Corresponde con el tamaño del efecto \(d\).
Conclusión: La longitud de los braquiópodos en la capa A no es significativamente diferente de la longitud de los braquiópodos en la capa B (\(\Delta M = 0.165\), 95% IC \([-0.023\), \(0.353]\)), \(t(16) = 1.86\), \(p = .081\), \(d_s\) = 0.88 \([-0.11, 1.85]\). El efecto se puede considerar grande, pero con un rango de muy pequeño, en dirección opuesta, hasta muy grande. Hay una probabilidad de 73.4% (PS) que un elemento de la muestra A tenga una longitud mayor que un elemento de la muestra B; las dos curvas se traslapan en un 65.9% (OVL); el 81.8% (\(U_3\)) de la muestra A se encuentra por encima de la media de la muestra B.
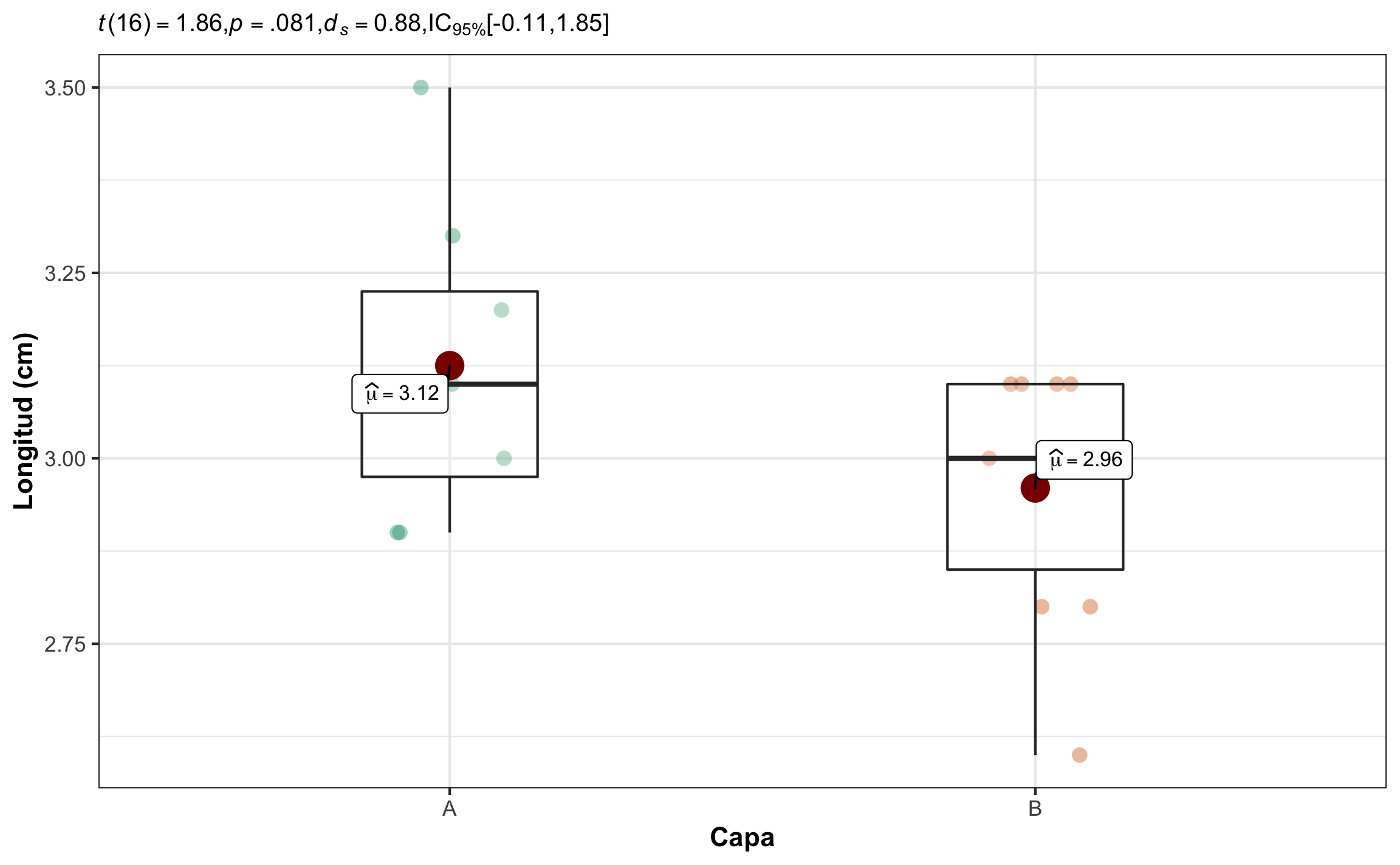
Figura 15.8: Gráfico de caja mostrando el efecto de la capa sobre la longitud de los braquiópodos, así como el resumen estadístico respectivo.
15.7 \(t\) de 2 muestras dependientes
Estas muestras que miden la misma observación (objeto, sujeto) más de una vez también se conocen como muestras pareadas o mediciones repetidas (repeated measures - en inglés).
El uso de la prueba \(t\) de 2 muestras dependientes se realiza con el ejemplo de la sección 14.2.2.2.2 (McKillup & Darby Dyar, 2010), donde se tenía el contenido de \(FeO\) en porcentaje de peso para 10 granitos que fueron preparados a diferentes tamaños de grano: \(< 25 \ \mu m\) y \(< 125 \ \mu m\). Hay un efecto en el tratamiento, en este caso, cambio del tamaño de grano (\(\mu_D=0\))? Asuma \(\alpha = .05\).
- Identificar la población, distribución, y la prueba apropiada:
- Población: contenido de \(FeO\) a diferentes tamaños de grano: \(< 25 \ \mu m\) y \(< 125 \ \mu m\)
- Distribución: media de las diferencia
- Prueba: \(t\) de 2 muestras dependientes porque se tienen los mismos elementos antes y después de un tratamiento (cambio de tamaño de grano)
- Establecer las hipótesis nula y alterna:
- \(H_0: \mu_D = 0 \to\) El contenido de \(FeO\) es igual a los diferentes tamaños de grano
- \(H_1: \mu_D \neq 0 \to\) El contenido de \(FeO\) es diferente a los diferentes tamaños de grano
- Determinar parámetros de la distribución a comparar (\(H_0\)):
- \(\mu_D = 0\)
- \(s_{\bar{d}} = \frac{s_d}{\sqrt{n}} = \frac{0.1247}{\sqrt{10}} = 0.0394\)
- Determinar valores críticos
- \(\alpha = .05\)
- \(t_{\alpha/2,v} = t_{.05/2,9} = |2.262|\)
- Calcular el estadístico de prueba
- \(t = \frac{\bar{d}}{s_{\bar{d}}} = \frac{0.1}{0.0394} = 2.538\)
- \(0.1 \pm 0.0981 \to 95\% \ IC \ [0.0108,0.189]\)
- Tomar una decisión
- El estadístico de prueba es mayor al crítico, \(t > t_{\alpha/2,v}\)
- El valor-p es menor a \(\alpha = .05\), \(p = .032\)
- El valor de \(0\) no cae dentro del intervalo de confianza, \(IC \ [0.0108,0.189]\)
- Decisión: Se rechaza \(H_0\)
R trae la función t.test que puede realizar las diferentes pruebas \(t\). Para el caso de 2 muestras dependientes se brindan los vectores de datos, el indicador lógico de si es una prueba dependiente (paired), y el nivel de confianza.
a = 0.05
m1 = c(13.5,14.6,12.7,15.5,11.1,16.4,13.2,19.3,16.7,18.4)
m2 = c(13.6,14.6,12.6,15.7,11.1,16.6,13.2,19.5,16.8,18.7)
n = length(m2)
r = cor(m1,m2)
t2.dep.res = t.test(x = m2,
y = m1,
paired = T,
conf.level = 1-a)
t2.dep.res##
## Paired t-test
##
## data: m2 and m1
## t = 2.5355, df = 9, p-value = 0.03195
## alternative hypothesis: true difference in means is not equal to 0
## 95 percent confidence interval:
## 0.01077932 0.18922068
## sample estimates:
## mean of the differences
## 0.1Como se mencionó en la sección 14.2.2.2.2, y a diferencia de muestras independientes, las pruebas de hipótesis para muestras dependientes no se pueden aproximar por medio de los intervalos de confianza (Figura 15.9), siguiendo las guías de Cumming & Finch (2005), Cumming (2012), y Cumming & Calin-Jageman (2017). En este caso solo se puede utilizar el intervalo de confianza para la diferencia, que va a estar en función de los márgenes de error de las muestras y la correlación entre las mismas (\(MoE_d^2 = MoE_1^2 + MoE_2^2 - 2rMoE_1MoE_2\)), donde a mayor correlación menor el margen de error para la diferencia y mayor precisión (Cumming & Finch, 2005).
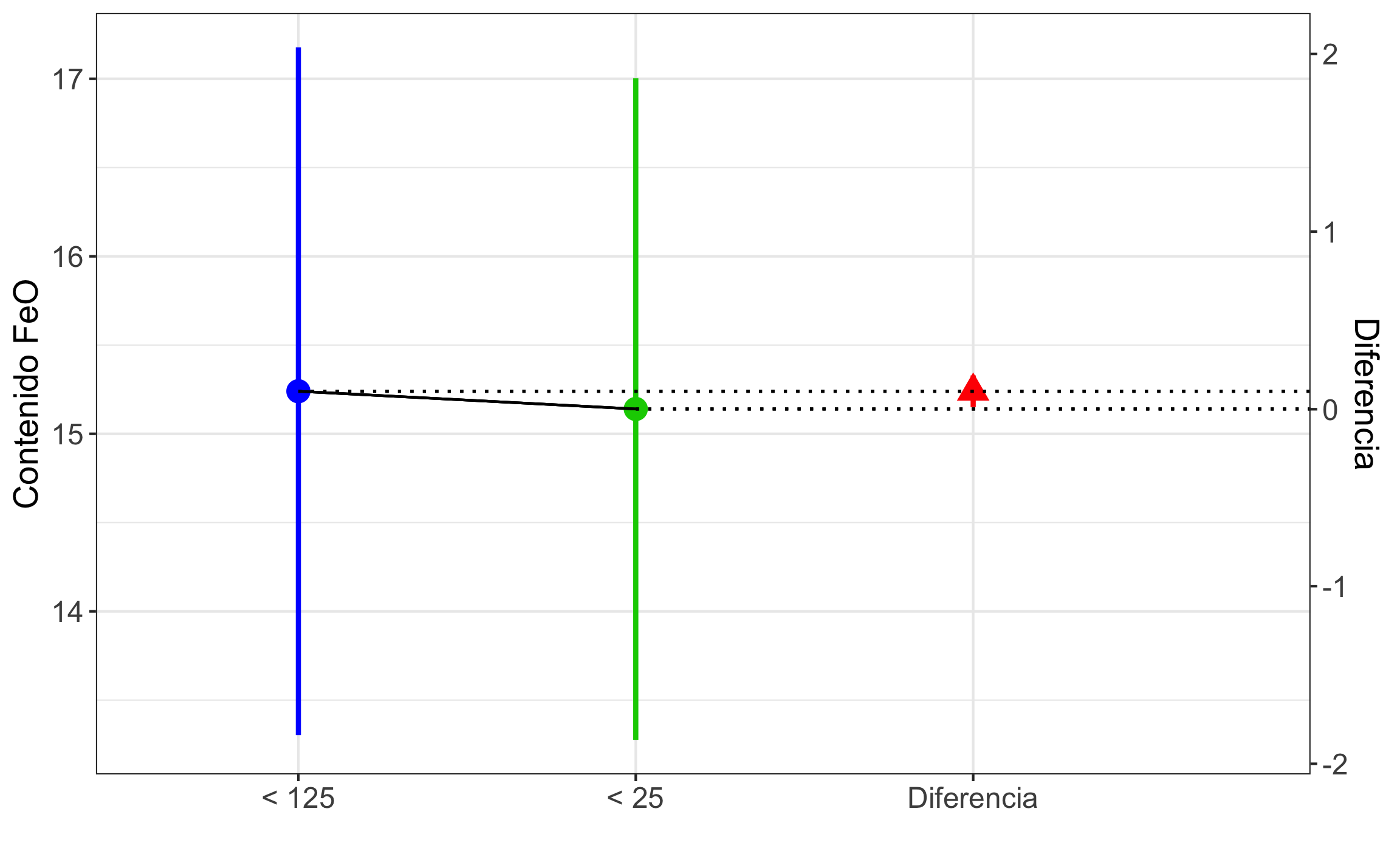
Figura 15.9: Intervalos de confianza para la prueba t de 2 muestras independientes. El valor de 0 cae fuera del intervalo de confianza para la diferencia, por lo que no se pueden considerar iguales o que hay diferencia entre la concentración de \(FeO\) para los tamaños.
El tamaño del efecto se puede calcular de acuerdo a las Ecuaciones (15.8), (15.9) y (15.10), donde la diferencia es qué se usa como estandarizador. De nuevo es buena práctica reportar qué se usó como estandarizador para claridad en lo que se reporta (Cumming & Calin-Jageman, 2017). Si la correlación entre las muestras es \(r \sim |.5|\) no hay mucha diferencia entre los tamaños de efecto, pero conforme la correlación se acerque a \(0\) o \(1\) mayor será la diferencia entre \(d_z\) con respecto a \(d_{rm}\) y \(d_{av}\) (Lakens, 2013). Debido al punto anterior, y la típica relación entre muestras, Cumming (2012), Cumming & Calin-Jageman (2017), y Lakens (2013) sugieren utilizar \(d_{av}\) como el tamaño del efecto.
\[\begin{equation} d_z = \frac{\bar{d}}{s_d}\\ d_z = \frac{0.1}{0.1247} = 0.80 \end{equation}\]
\[\begin{equation} d_{rm} = \frac{\bar{d}}{\sqrt{s_1^2 + s_2^2 - 2 \cdot r \cdot s_1 \cdot s_2}}\sqrt{2(1-r)}\\ d_{rm} = \frac{0.1}{\sqrt{7.33 + 6.79 - 2 \cdot .9996 \cdot 2.7 \cdot 2.6}}\sqrt{2(1-.9996)} = 0.001\\ \text{usando todos los decimales da } d_{rm} = 0.022) \end{equation}\]
\[\begin{equation} d_{av} = \frac{\bar{d}}{\sqrt{\frac{s_1^2 + s_2^2}{2}}}\\ d_{av} = \frac{0.1}{\sqrt{\frac{7.33 + 6.79}{2}}} = 0.038 \end{equation}\]
En R se puede calcular \(d_z\) con la función d.dep.t.diff, \(d_{rm}\) con la función d.dep.t.rm, y \(d_{av}\) con la función d.dep.t.avg, todas del paquete MOTE. Adicionalmente existen las funciones cohens_d de effectsize, y cohen.d de effsize, donde de nuevo se tiene que definir el argumento paired, pero en los dos casos el efecto que calculan es \(d_z\), el cual es el menos recomendado. Además, la función cohensd_rm del paquete itns (Erceg-Hurn et al., 2017) calcula \(d_{av}\).
Usando MOTE
a = 0.05
d.t2.dep.res1 = d.dep.t.diff(mdiff = mean(m2-m1),
sddiff = sd(m2-m1),
n = n,
a = a)
d.t2.dep.res1[1:3] %>% unlist()## d dlow dhigh
## 0.80178373 0.06638463 1.50482386d.t2.dep.res2 = d.dep.t.rm(m1 = mean(m2),
m2 = mean(m1),
sd1 = sd(m2),
sd2 = sd(m1),
r = r,
n = n,
a = a)
d.t2.dep.res2[1:3] %>% unlist()## d dlow dhigh
## 0.02164429 -0.59882065 0.64092600d.t2.dep.res3 = d.dep.t.avg(m1 = mean(m2),
m2 = mean(m1),
sd1 = sd(m2),
sd2 = sd(m1),
n = n,
a = a)
d.t2.dep.res3[1:3] %>% unlist()## d dlow dhigh
## 0.03764125 -0.58341889 0.65664471La Tabla 15.4 muestra la comparación entre los diferentes tamaños de efecto para el ejemplo de muestras dependientes. Los resultados muestran como \(d_z\) sobrestima (y por mucho) a \(d_{rm}\) y \(d_{av}\), donde \(d_{rm}\) es el más conservador de todos. (Lakens, 2013). El hecho de que \(d_z\) sobrestima el tamaño del efecto es debido a la alta correlación entre las muestras \(r = .9996\).
| ES | \(d\) | \(IC_{inf}\) | \(IC_{sup}\) |
|---|---|---|---|
| \(d_z\) | 0.802 | 0.066 | 1.505 |
| \(d_{rm}\) | 0.022 | -0.599 | 0.641 |
| \(d_{av}\) | 0.038 | -0.583 | 0.657 |
Un panorama general del efecto de \(r\) en el tamaño del efecto para muestras dependientes se muestra en la Tabla 15.5, donde se generaron tres juegos de datos, provenientes de poblaciones con \(r=.1\), \(r=.5\), y \(r=.9\), respectivamente. Se observa como a bajos valores de \(r\) \(d_z\) subestima el tamaño del efecto (con respecto a \(d_{rm}\) y \(d_{av}\)), a valores intermedios todos son muy similares, y a altos valores de \(r\) \(d_z\) sobrestima el tamaño del efecto (con respecto a \(d_{rm}\) y \(d_{av}\)), lo que muestra la sensibilidad y el efecto de \(r\) en el uso de \(d_z\), y por lo que se recomienda usar \(d_{rm}\) o \(d_{av}\).
| \(\rho\) | \(r\) | \(d_z\) | \(d_{rm}\) | \(d_{av}\) |
|---|---|---|---|---|
| .1 | .254 | 0.511 | 0.624 | 0.625 |
| .5 | .492 | 0.637 | 0.642 | 0.646 |
| .9 | .932 | 2.107 | 0.778 | 0.804 |
Usando itns
d.t2.dep.res4 = cohensd_rm(m2,m1,
ci = 1-a)
d.t2.dep.res4## est ll ul
## 0.03763431 0.03630516 0.03671538Usando effectsize
cohens_d(m2,m1,
paired = T,
ci = 1-a)## # A tibble: 1 x 4
## Cohens_d CI CI_low CI_high
## <dbl> <dbl> <dbl> <dbl>
## 1 0.802 0.95 0.0700 1.59Usando effsize
cohen.d(m2,m1,
conf.level = 1-a,
paired = T,
noncentral=T)##
## Cohen's d
##
## d estimate: 0.8017837 (large)
## 95 percent confidence interval:
## lower upper
## 0.06996669 1.58622949Usando las medidas PS, OVL, y \(U_3\) (Figura 15.10).
## # A tibble: 1 x 3
## PS OVL U3
## <dbl> <dbl> <dbl>
## 1 51.1 98.5 51.5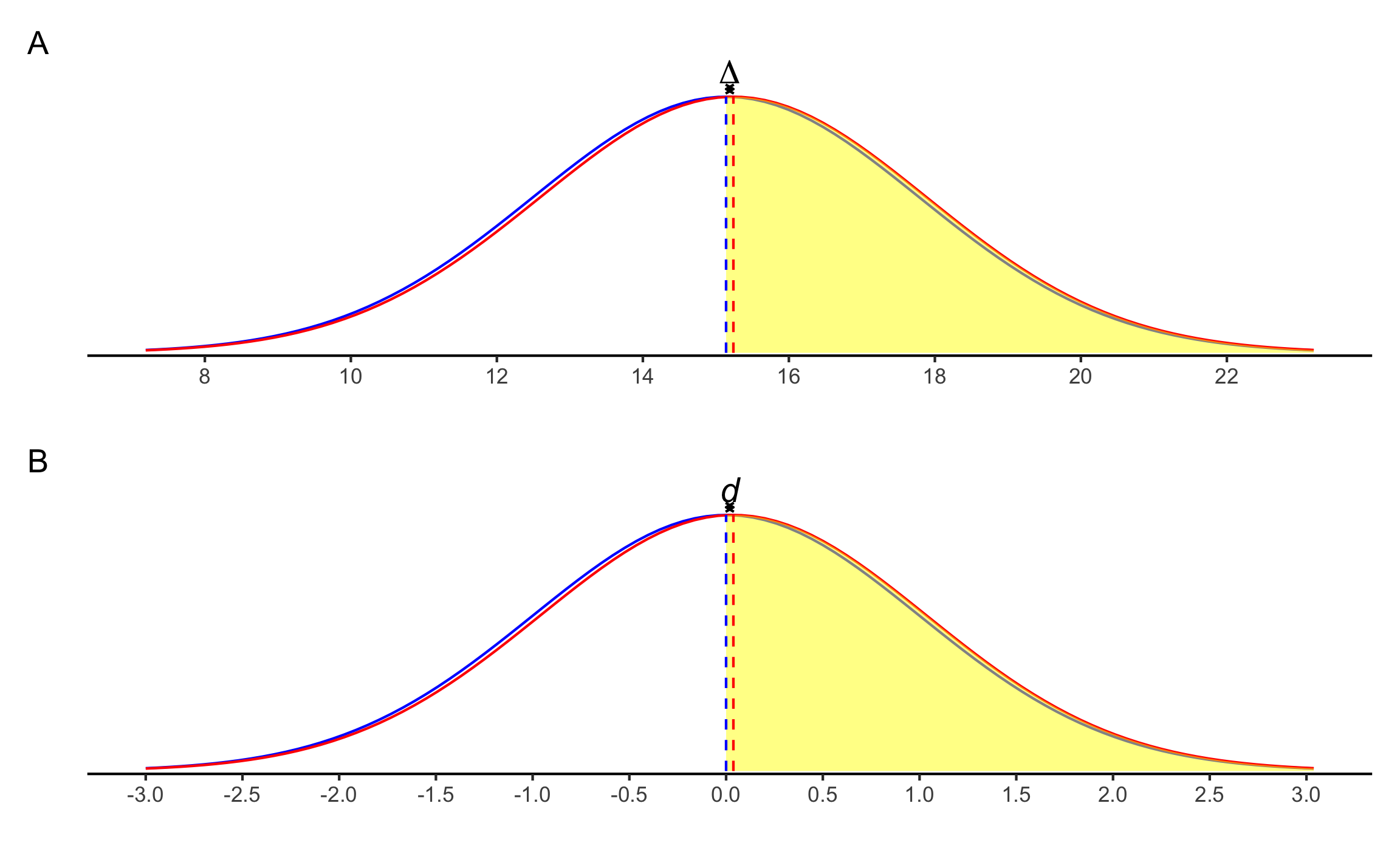
Figura 15.10: \(U_3\) para el ejemplo de la prueba \(t\) de 2 muestras dependientes. A Corresponde con los datos en escala original. B Corresponde con el tamaño del efecto \(d\).
Conclusión: La concentración de \(FeO\) es significativamente diferente para los diferentes tamaños (\(M_d = 0.100\), 95% IC \([0.011\), \(0.189]\)), \(t(9) = 2.54\), \(p = .032\), \(N = 10\), \(r = .9996\), \(d_{av}\) = 0.04 \([-0.58, 0.66]\). El efecto se puede considerar muy pequeño, con un rango de mediano, en dirección opuesta, hasta mediano en la dirección del efecto. Hay una probabilidad de 51.1% (PS) que un elemento de la muestra de \(< 125 \ \mu m\) tenga una concentración mayor que un elemento de la muestra de \(< 25 \ \mu m\); las dos curvas se traslapan en un 98.5% (OVL); el 51.5% (\(U_3\)) de la muestra de \(< 125 \ \mu m\) se encuentra por encima de la media de la muestra de \(< 25 \ \mu m\).

Figura 15.11: Gráfico de caja mostrando el efecto del tamaño de partícula sobre el contenido de FeO, así como el resumen estadístico respectivo.
15.8 ANOVA de 1-factor entre-sujetos
Hasta el momento solo se han analizado casos donde se tenían 1 o 2 muestras y se desean hacer inferencias sobre la media, pero en muchos casos se pueden llegar a tener 3 o más muestras.
Se podría pensar en realizar diferentes pruebas \(t\) de dos muestras, pero esto genera dos problemas: primero, dependiendo de la cantidad de grupos el número de comparaciones sería muy grande, y segundo y más importante al realizar diferentes pruebas \(t\) se va a inflar el error tipo-I (\(\alpha\)), pudiendo incurrir en conclusiones equivocadas (Nolan & Heinzen, 2014).
La prueba del análisis de varianza (ANOVA - Analysis of Variance, en inglés), es una prueba que permite dilucidar la similitud entre muestras sin incurrir en los problemas antes mencionados, y la cual hace uso de la distribución y prueba \(F\) para el análisis. La base teórica y procedimental que se va a exponer aquí se puede encontrar en (Borradaile, 2003; Davis, 2002; McKillup & Darby Dyar, 2010; Nolan & Heinzen, 2014; Swan & Sandilands, 1995; Walpole et al., 2012)
Una suposición de ANOVA es que las varianzas son iguales; esta prueba es relativamente robusta a esta suposición siempre y cuando la razón entre las desviaciones estándar mayor y menor no sea superior a 2. De querer realizar pruebas para determinar esta similitud, se pueden usar las pruebas de Levene (\(F\), media), Brown-Forsythe (\(F\), mediana), o Bartlett (\(\chi^2\), media). ANOVA es una técnica que permite diferentes diseños, pero en esta sección se presenta el caso más sencillo, el cual se conoce como ANOVA de 1 factor entre-sujetos (between-subjects ANOVA). Este diseño quiere decir que la variable de interés (numérica continua) está en función de una variable categórica (factor o tratamiento) con \(2+\) grupos o clases. De hecho, la prueba \(t\) de 2 muestras independientes es un caso especial de ANOVA con 2 grupos, y se puede comprobar que \(F=t^2\).
De manera general las hipótesis nula y alterna serían:
- \(H_0: \mu_1 = \mu_2 = \mu_3 = \cdots = \mu_k\)
- \(H_1: \text{Al menos 1 de las media es diferente}\)
Para poder determinar el efecto de los diferentes grupos (muestras) en la variación de la media de la variable de interés, se puede pensar en que hay dos fuentes de variación: entre las muestras (Figura 15.12) y dentro de las muestras (Figura 15.13).
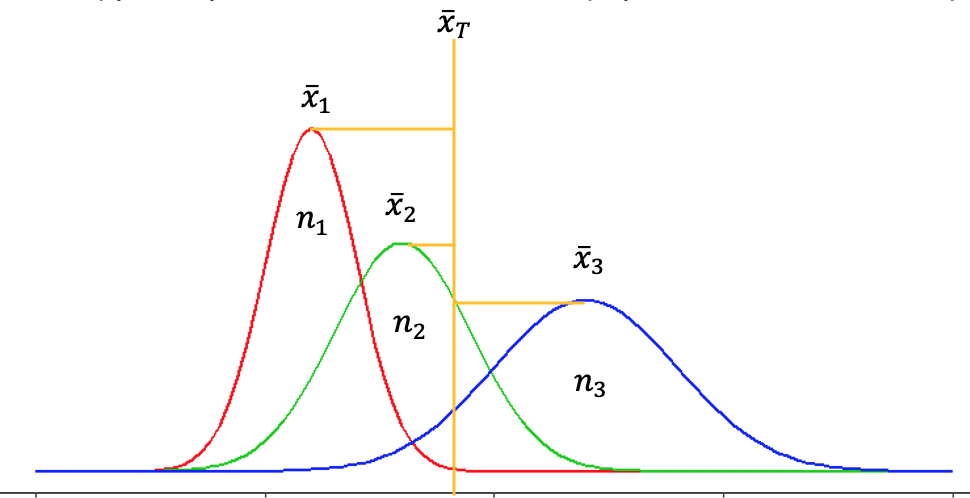
Figura 15.12: Representación de la variación entre grupos. Conforme más separados estén y más distancia con respecto a la media general, mayor la variación.
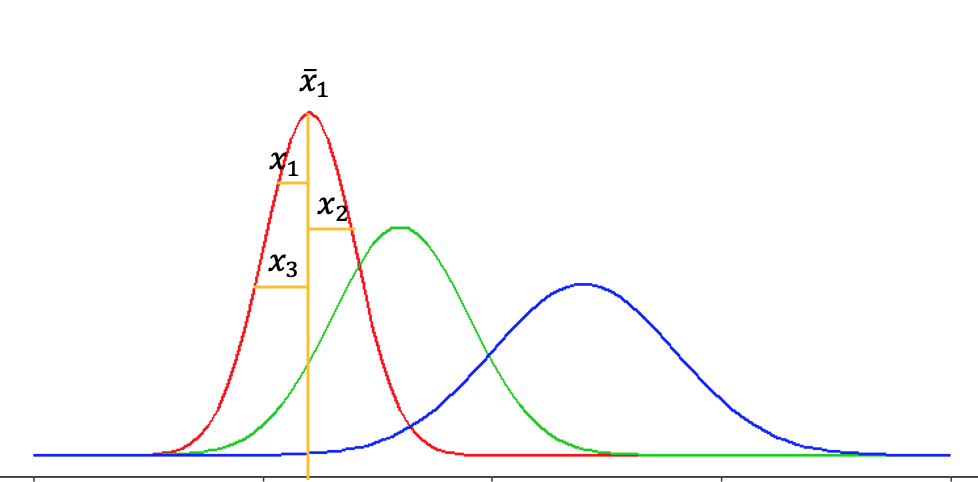
Figura 15.13: Representación de la variación dentro de grupos. Conforme más dispersión haya en las muestras mayor la vriación dentro de lo grupos.
La variación entre grupos va a cuantificar la diferencia real entre las medias más el error (variación dentro de los grupos), por lo que de manera general se puede estimar este efecto por medio del estadístico \(F\) a como se muestra en la Ecuación (15.25). Conforme mayor sea la diferencia entre los grupos mayor será el valor de \(F\), mientras que conforme más similares sean los grupos \(F \sim 1\). Para este caso la prueba \(F\) va a ser siempre de una cola, donde hay un único valor crítico y la región de rechazo se encuentra a la derecha.
\[\begin{equation} F = \frac{\text{variación entre grupos (diferencia + error)}}{\text{variación dentro de grupos (error)}} \tag{15.25} \end{equation}\]
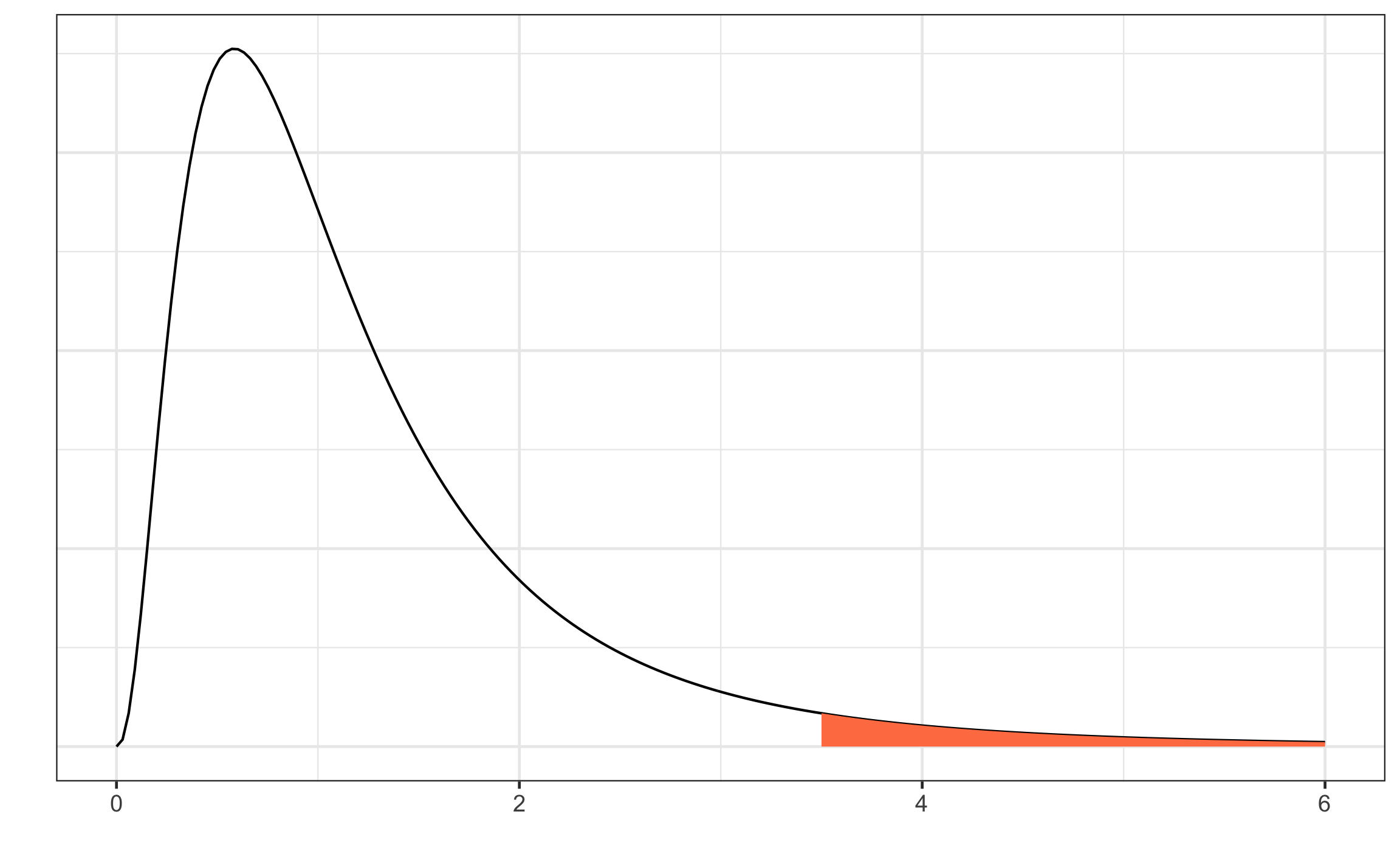
Figura 15.14: Representación de la distribución \(F\), donde se muestra la región crítica o de rechazo en color rojo.
El resultado de ANOVA por lo general se presenta como una tabla, donde manera general lleva la estructura presentada en la Tabla 15.6. El tamaño del efecto para ANOVA se puede obtener de los valores de la tabla: \(\eta^2=SCG/SCT\), donde \(SCT\) es la suma de cuadrados total (\(SCT=SCG+SCE\)) y corresponde con el porcentaje de variación en la variable respuesta explicado por el efecto de los grupos.
| Suma de cuadrados | Grados de liberta | Cuadrados medios | F | |
|---|---|---|---|---|
| Entre grupos | \(SCG = \sum(\bar{x}_g-\bar{x}_T)^2 \cdot n_g\) | \(k-1\) | \(s_1^2 = \frac{\sum(\bar{x}_g-\bar{x}_T)^2 \cdot n_g}{k-1}\) | \(\frac{s_1^2}{s^2}\) |
| Dentro de grupos (error) | \(SCE = \sum\sum(x_{ig}-\bar{x}_g)^2\) | \(N-k\) | \(s^2 = \frac{\sum\sum(x_{ig}-\bar{x}_g)^2}{N-k}\) | |
| Notas: | ||||
| \(\bar{x}_g\) = media del grupo | ||||
| \(\bar{x}_T\) = media total (global) | ||||
| \(x_{ig}\) = valor \(i\) del grupo \(g\) | ||||
| \(n_g\) = tamaño del grupo \(g\) | ||||
| \(k\) = número de grupos | ||||
| \(N\) = total de observaciones |
Cuando el resultado de la prueba de ANOVA es significativo esto indica que al menos uno de los grupos es diferente, pero no se sabe cuál. Para poder responder hay dos opciones:
- Si no se tiene idea o no se ha decidido con anterioridad de cuáles grupos se quieren comparar se pueden realizar análisis posteriores (post-hoc) comparando todos los grupos, donde se ajusta para el error tipo-I. El post-hoc más utilizado es TukeyHSD (Honestly Significant Difference), pero existen otros como Bonferroni, Holm, Scheffe, etc. La ventaja de Tukey es que brinda más información que los otros (diferencia entre grupos e intervalo de confianza para la diferencia).
- Si se han decidido comparaciones (contrastes) a priori éstas son las que se analizan, pero debieron haberse especificado durante la planificación del estudio y antes de recolectar los datos. Estas tienen la ventaja de que se reducen el número de comparaciones, y por lo general se obtienen las mismas conclusiones.
Para demostrar el ANOVA se usa un ejemplo de McKillup & Darby Dyar (2010), donde se tiene el contenido de \(MgO\) presente en cuatro turmalinas en tres sitios diferentes: Mount Mica, Sebago Batholith, Black Mountain. Asuma \(\alpha=.05\).
- Identificar la población, distribución, y la prueba apropiada:
- Población: contenido de \(MgO\) presente en turmalinas en Mount Mica, Sebago Batholith, Black Mountain
- Distribución: F
- Prueba: \(F\)
- Establecer las hipótesis nula y alterna:
- \(H_0: \mu_1 = \mu_2 = \mu_3 \to\) El contenido de \(MgO\) presente en las turmalinas de los tres sitios es el mismo
- \(H_1:\) El contenido de \(MgO\) presente en las turmalinas difiere por lo menos en uno de los tres sitios
- Determinar parámetros de la distribución a comparar (\(H_0\)):
- \(v_1 = k-1 = 3-1=2\)
- \(v_2 = N-k = 12-3 = 9\)
- Determinar valores críticos
- \(\alpha = .05\)
- \(F_{\alpha,v_1,v_2} = F_{.05,2,9} = 4.256\)
- Calcular el estadístico de prueba
- \(F = \frac{36}{3.3} = 10.8\)
- El procedimiento manual no se detalla aquí por ser más extenso y elaborado de lo normal, pero se recomienda al lector revisar las referencias mencionadas para detallarlo y entenderlo
- Tomar una decisión
- El estadístico de prueba es mayor al crítico, \(F > F_{\alpha,v_1,v_2}\)
- El valor-p es menor a \(\alpha = .05\), \(p = .004\)
- Decisión: Se rechaza \(H_0\) y por lo menos uno de los contenidos de \(MgO\) es diferente
En R los datos tienen que estar en formato largo, lo que quiere decir una columna con los valores de la variable de interés, y otra columna con el grupo al que pertenece la medición. Otro punto importante es que la variable agrupadora es mejor que sea del tipo factor.
Los datos del ejemplo se encuentran en el archivo anova MgO.csv
a = 0.05
dat.aov = import('data/anova MgO.csv', setclass = 'tibble') %>%
mutate(Location = as.factor(Location) %>%
fct_reorder(MgO))
dat.aov## # A tibble: 12 x 2
## Location MgO
## <fct> <int>
## 1 Mount Mica 7
## 2 Mount Mica 8
## 3 Mount Mica 10
## 4 Mount Mica 11
## 5 Sebago Batholith 4
## 6 Sebago Batholith 5
## 7 Sebago Batholith 7
## 8 Sebago Batholith 8
## 9 Black Mountain 1
## 10 Black Mountain 2
## 11 Black Mountain 4
## 12 Black Mountain 5N = nrow(dat.aov)Es recomendable hacer una inspección de los grupos, tanto numérica (Tabla 15.7) como gráfica, para darnos una idea de la media y desviaciones estándar. Aquí se observa que todos los grupos tienen la misma desviación estándar (algo poco común), por lo que el supuesto de la homogeneidad de varianzas se mantiene.
dat.aov %>%
group_by(Location) %>%
summarise_all(list(N = ~n(),
Avg = ~mean(.),
SD = ~sd(.)))| Location | N | Avg | SD |
|---|---|---|---|
| Black Mountain | 4 | 3 | 1.826 |
| Sebago Batholith | 4 | 6 | 1.826 |
| Mount Mica | 4 | 9 | 1.826 |
ggplot(dat.aov, aes(Location, MgO)) +
stat_summary(fun.data = mean_cl_normal,
fun.args = list(conf.int = 1-a),
geom = 'pointrange', size = .75) +
labs(x='')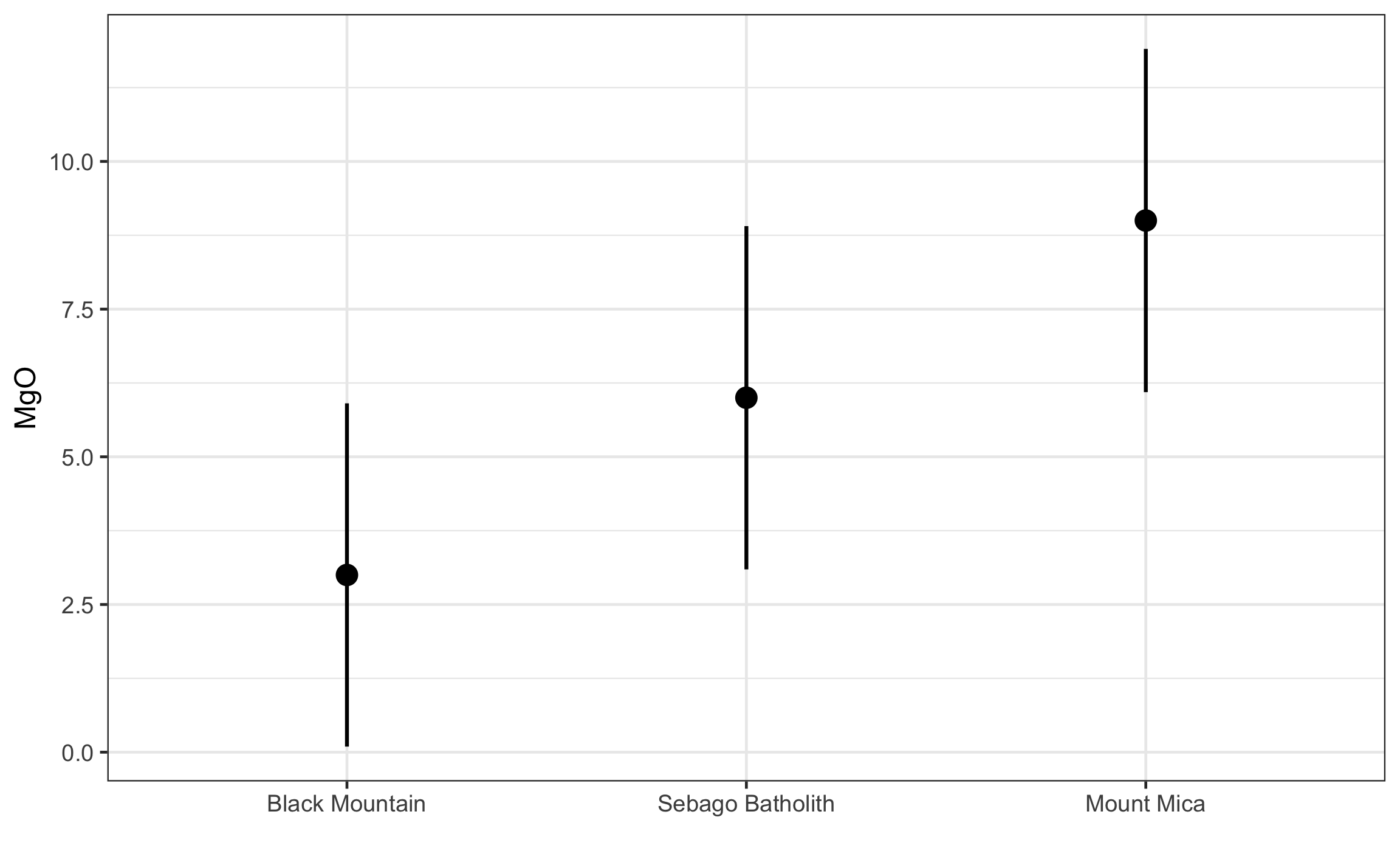
Figura 15.15: Medias e intervalos de confianza (95%) para cada grupo.
Para realizar el ANOVA se puede hacer de diferentes maneras, pero de manera general se expresa como un modelo lineal y ~ x, donde y es la variable de interés y x es la variable agrupadora. Se pueden usar diferentes funciones, dentro de ellas aov, lm, donde siempre es necesario especificar la tabla de datos. La tabla resumen se muestra en la Tabla 15.8, donde se puede confeccionar a partir de la función anova o summary.
mgo.aov = aov(MgO ~ Location, dat.aov)anova(mgo.aov)| Grados libertad | Suma Cuadrados | Cuadrados Medios | F | Valor-p | |
|---|---|---|---|---|---|
| Location | 2 | 72 | 36.0000 | 10.8 | 0.0041 |
| Residuals | 9 | 30 | 3.3333 | NA | NA |
El resultado es significativo, indicando que por lo menos uno de los contenidos de \(MgO\) difiere del resto.
El tamaño del efecto \(\eta^2\) se puede calcular usando las Ecuaciones (15.15), (15.16), y el tamaño del efecto \(\omega^2\) se puede calcular usando las Ecuaciones (15.17), (15.18), donde \(SC_{total}\) es la suma de la columna Suma de cuadrados (Sum Sq). Para este tipo de ANOVA (1-factor entre grupos) se cumple que \(\eta^2 = \eta_p^2\) y \(\omega^2 = \omega_p^2\), ya que hay solo 1 factor, pero para el resto de ocasiones donde haya más de un factor esta igualdad no se cumple y se recomienda incluir ambos tamaños de efecto (global y parcial).
\[\begin{equation} \eta^2 = \frac{SC_{efecto}}{SC_{total}} = \frac{72}{72+30} = .706 \end{equation}\]
\[\begin{equation} \omega^2 = \frac{v_{efecto}(CM_{efecto}-CM_{error})}{SC_{total}+CM_{error}} = \frac{2 (36-3.33)}{102+3.33} = .62 \end{equation}\]
En R el tamaño del efecto, así como el intervalo de confianza, se puede obtener por medio de las funciones eta.F (\(\eta^2\)), eta.partial.SS (\(\eta^2_p\)), omega.F (\(\omega^2\)), omega.partial.SS.bn (\(\omega^2_p\)) de MOTE, y eta_squared, omega_squared de effectsize. Para eta.F y omega.F es necesario indicar los grados de libertad, el valor de \(F\), y el nivel de significancia \(\alpha\), mientras que para eta.partial.SS hay que indicar además las sumas de cuadrados y para omega.partial.SS.bn los cuadrados medios. Para eta_squared y omega_squared lo que se necesita es el objeto de ANOVA y el nivel se confianza, por defecto calcula el \(\eta^2_p\) o \(\omega^2_p\).
Para \(\eta^2\)
aov.eta = eta.F(dfm = 2, dfe = 9, Fvalue = 10.8, a = a)
aov.eta[1:3] %>% unlist()## eta etalow etahigh
## 0.7058824 0.1574104 0.8872368aov.eta.p = eta.partial.SS(dfm = 2, dfe = 9,
ssm = 72, sse = 30,
Fvalue = 10.8, a = a)
aov.eta.p[1:3] %>% unlist()## eta etalow etahigh
## 0.7058824 0.1574104 0.8872368eta_squared(mgo.aov,partial = T,ci = 1-a)## # A tibble: 1 x 5
## Parameter Eta_Sq_partial CI CI_low CI_high
## <chr> <dbl> <dbl> <dbl> <dbl>
## 1 Location 0.706 0.95 0.193 0.859Para \(\omega^2\)
aov.omega = omega.F(dfm = 2, dfe = 9, Fvalue = 10.8, n = N, a = a)
aov.omega[1:3] %>% unlist()## omega omegalow omegahigh
## 0.62025316 0.05224699 0.84844901aov.omega.p = omega.partial.SS.bn(dfm = 2, dfe = 9,
msm = 36,mse = 3.33,
ssm = 72, n = N, a = a)
aov.omega.p[1:3] %>% unlist()## omega omegalow omegahigh
## 0.62051282 0.05249113 0.84857108omega_squared(mgo.aov,partial = T,ci = 1-a)## # A tibble: 1 x 5
## Parameter Omega_Sq_partial CI CI_low CI_high
## <chr> <dbl> <dbl> <dbl> <dbl>
## 1 Location 0.620 0.95 0.0120 0.815Como se encontró un resultado significativo, es necesario indicar dónde se encuentran esas diferencias. Aquí no se definieron contrastes a priori, por lo que se usa Tukey para ajustar el error tipo-I para todas las comparaciones. Se usa la función TukeyHSD donde los argumentos necesarios son el objeto de ANOVA y el nivel de confianza. Aquí se puede interpretar el valor-p con respecto al nivel de significancia escogido, ya que es un valor-p ajustado, de igual manera se puede interpretar el intervalo de confianza. El resumen de la prueba de Tukey se presenta en la Tabla 15.9 y la Figura 15.16. En los resultados se observa que la única diferencia significativa es la de Mount Mica-Black Mountain, ya que el valor-p está por debajo del \(\alpha\) y el intervalo de confianza no incluye 0.
tukey = TukeyHSD(mgo.aov,
conf.level = 1-a) %>%
tidy() %>%
select(-term)| Comparación | Diferencia | \(IC_{inf}\) | \(IC_{sup}\) | Valor-p ajustado |
|---|---|---|---|---|
| Sebago Batholith-Black Mountain | 3 | -0.604 | 6.604 | 0.103 |
| Mount Mica-Black Mountain | 6 | 2.396 | 9.604 | 0.003 |
| Mount Mica-Sebago Batholith | 3 | -0.604 | 6.604 | 0.103 |
ggplot(tukey, aes(comparison, estimate,
ymin = conf.low, ymax = conf.high)) +
geom_pointrange(size = 1) +
geom_hline(yintercept = 0, col = 'red') +
coord_flip() +
theme_bw() +
labs(y = 'Diferencia en medias', x = 'Comparación')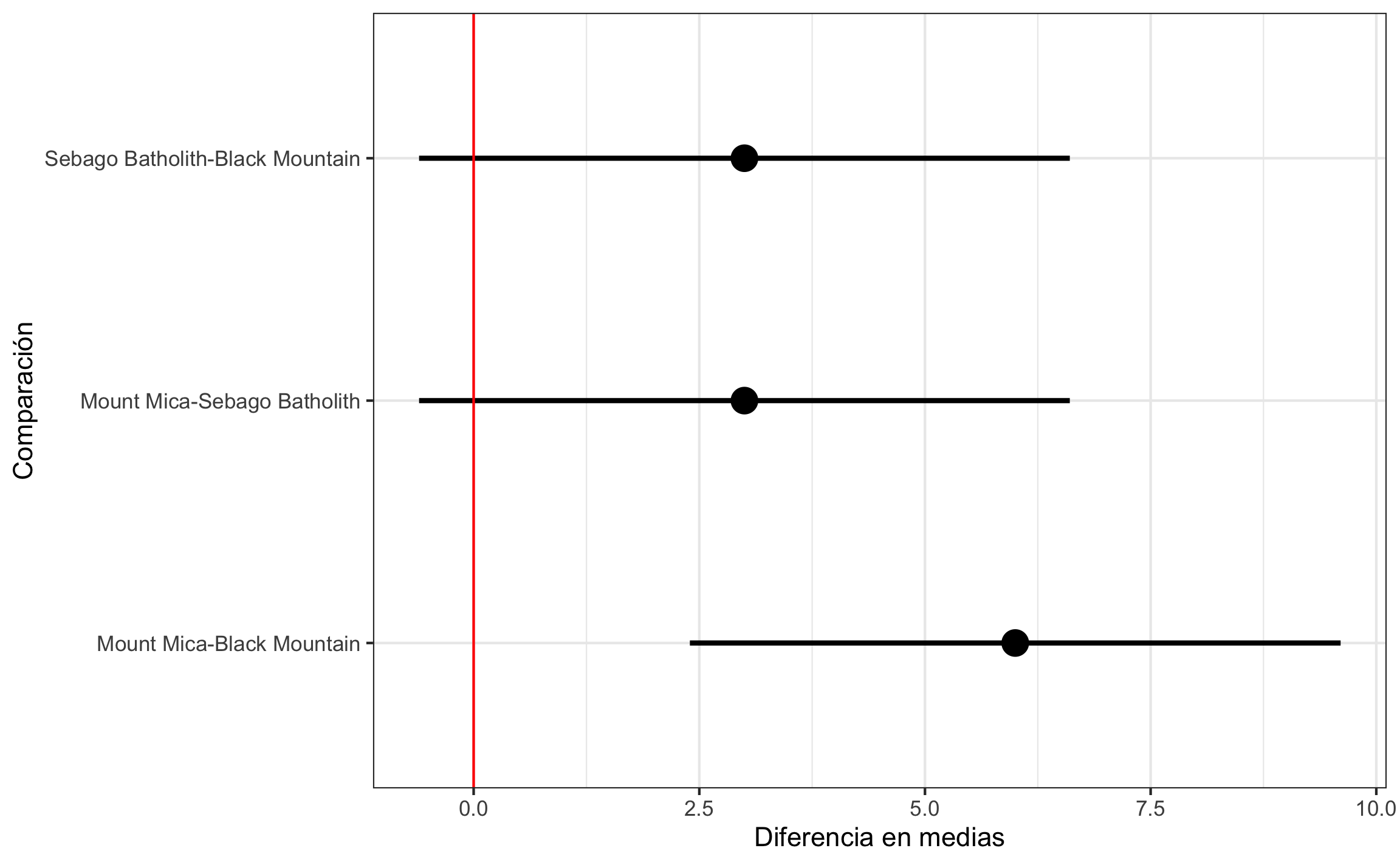
Figura 15.16: Intervalos de confianza (95%) para las comparaciones usando la prueba de Tukey.
Además de realizar los análisis posteriores (contrastes a priori o comparaciones múltiples posteriores) y determinar en dónde hay diferencias significativas, es recomendable calcular el tamaño del efecto (\(d\) o \(g\)) para estos contrastes/comparaciones. Ésto se demuestra en el siguiente bloque de código donde a los resultados de Tukey se le agregan el tamaño de efecto y el intervalo de confianza para éste.
dat.aov.wide = dat.aov %>%
mutate(id = 1:nrow(.)) %>%
pivot_wider(names_from = 'Location',values_from = 'MgO')
tukey %>%
separate(comparison,c('G1','G2'),'-') %>%
mutate(d = map2(G1,G2,~hedges_g(dat.aov.wide[[.x]] %>% na.omit(),
dat.aov.wide[[.y]] %>% na.omit(),
ci = 1-a,correction = F) %>%
as.data.frame)) %>%
unnest(d) %>%
as.data.frame() %>%
select(-CI) %>%
mutate_if(is.numeric,~round(.,3))## # A tibble: 3 x 9
## G1 G2 estimate conf.low conf.high adj.p.value Hedges_g CI_low CI_high
## <chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 Sebago… Black… 3 -0.604 6.60 0.103 1.43 -0.052 2.83
## 2 Mount … Black… 6 2.40 9.60 0.003 2.86 0.836 4.80
## 3 Mount … Sebag… 3 -0.604 6.60 0.103 1.43 -0.052 2.83Conclusión: El contenido de \(MgO\) varía significativamente entre las localidades, \(F\)(2, 9) = 10.80, \(p\) = .004. El tamaño del efecto es grande, \(\eta^2\) = .71, 95% IC [.16, .89], pero con un rango muy amplio. Análisis posteriores con Tukey HSD indican que hay una diferencia entre Mount Mica - Black Mountain (\(\Delta M = 6.00\), 95% IC \([2.39\), \(9.61]\), \(t(9) = 4.65\), \(p = .003\)), pero no así entre Mount Mica - Sebago Batholith (\(\Delta M = 3.00\), 95% IC \([-0.61\), \(6.61]\), \(t(9) = 2.32\), \(p = .103\)), ni Sebago Batholith - Black Mountain (\(\Delta M = 3.00\), 95% IC \([-0.61\), \(6.61]\), \(t(9) = 2.32\), \(p = .103\)).
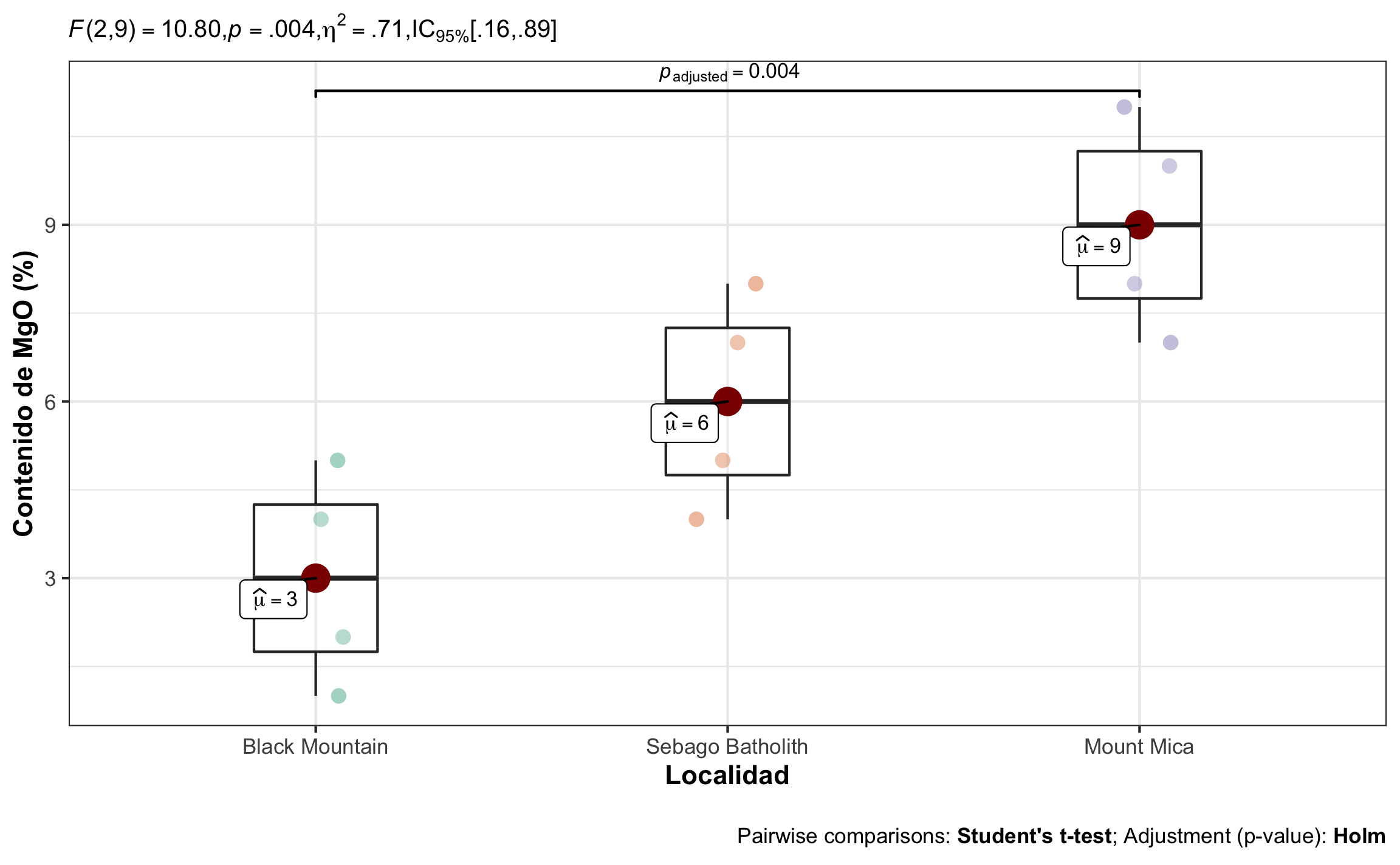
Figura 15.17: Gráfico de caja mostrando el efecto de localidad sobre el contenido de MgO, la comparación significativa, así como el resumen estadístico respectivo.
15.8.1 Relación entre la prueba \(t\) de 2 muestras independientes y ANOVA de 1-factor entre-sujetos
Como se mencionó en la introducción de ANOVA, la prueba \(t\) de 2 muestras independientes es un caso especial de ANOVA con 2 grupos, y se mencionó que \(F=t^2\). En esta pequeña sección se muestra la relación entre estas pruebas, tratando los datos usados en la prueba \(t\) de 2 muestras independientes como un ANOVA.
braq.aov = aov(values~ind,data = braq)
anova(braq.aov)## # A tibble: 2 x 5
## Df `Sum Sq` `Mean Sq` `F value` `Pr(>F)`
## <int> <dbl> <dbl> <dbl> <dbl>
## 1 1 0.121 0.121 3.46 0.0812
## 2 16 0.559 0.0349 NA NAEl resultado de la prueba \(t\) de 2 muestras independientes tenía \(t = 1.86\), y \(p = .081\). Si comparamos estos valores con el resultado de ANOVA se tiene que el valor-p es el mismo, y \(t^2=F \to 1.86^2=3.46\), que efectivamente es el valor de \(F\).
Lo otro que se puede comparar son los tamaños de efecto. Para la prueba \(t\) de 2 muestras independientes se tenía \(d_s = 0.883\), y para el ANOVA de los mismos datos se tiene \(\eta_p^2 = .178\) (el lector puede hacer el cálculo para corroborar).
Para pasar de \(d_s\) a \(\eta_p^2\) se pueden usar las Ecuaciones (15.23) para obtener \(r_{pb}\) y \(\eta_p^2 = r_{pb}^2\), o (15.24) para obtener \(\eta_p^2\) directamente, como se demuestra a continuación.
\[\begin{equation} r_{pb} = \frac{d_s}{\sqrt{d_s^2 + \frac{N^2-2N}{n_1 n_2}}}\\ r_{pb} = \frac{0.883}{\sqrt{0.883^2 + \frac{18^2-2 \cdot 18}{8 \cdot 10}}} = .422\\ \eta_p^2 = r_{pb}^2 = .422^2 = .178\\ \eta_p^2 = \frac{t^2}{t^2+v} = \frac{1.86^2}{1.86^2+16} = .178 \end{equation}\]
Como se puede observar se obtiene el mismo valor de \(\eta^2\) para ambas pruebas, demostrando de nuevo la relación entre las mismas.
Este pequeño ejemplo demuestra la relación que hay entre las pruebas mencionadas, donde lo importante es que se obtiene la misma conclusión.
15.9 Correlación de Pearson
En la sección de Correlación (10.3) se introdujo el concepto de correlación, más específicamente la correlación de Pearson. Esta es una medida de asociación entre dos variables (en este caso numéricas) que indica la magnitud y dirección de dicha asociación. La idea de la prueba para la correlación es determinar si la correlación encontrada es significativa o no, o sea, si difiere de cero (Borradaile, 2003; Davis, 2002; Field et al., 2012; Nolan & Heinzen, 2014; Swan & Sandilands, 1995; Trauth, 2015).
Para determinar la significancia de la correlación de Pearson se usa una prueba \(t\). Esta prueba se realiza con un ejemplo de Davis (2002), donde se tiene la longitud de los ejes de cantos en una playa (Tabla 15.10). Se quiere determinar si la correlación entre los ejes \(a\) y \(b\) es significativa, asumiendo \(\alpha = .1\).
| Canto | Eje-a | Eje-b | Eje-c |
|---|---|---|---|
| 1 | 8 | 7 | 3 |
| 2 | 16 | 8 | 5 |
| 3 | 12 | 10 | 9 |
| 4 | 13 | 12 | 5 |
| 5 | 16 | 14 | 5 |
| 6 | 14 | 9 | 8 |
| 7 | 16 | 13 | 13 |
| 8 | 11 | 6 | 3 |
| 9 | 15 | 9 | 9 |
| 10 | 13 | 10 | 9 |
| Fuente: Davis (2002) |
- Identificar la población, distribución, y la prueba apropiada:
- Población: relación entre ejes \(a\) y \(b\)
- Distribución: de correlaciones
- Prueba: \(t\) de correlación
- Establecer las hipótesis nula y alterna:
- \(H_0: \rho = 0 \to\) No hay relación entre los ejes
- \(H_1: \rho \neq 0 \to\) Hay una relación entre los ejes
- Nota: \(\rho\) es el parámetro poblacional para la correlación
- Determinar parámetros de la distribución a comparar (\(H_0\)):
- \(r_{a,b} = .597\)
- \(v = N-2 = 10-2 = 8\)
- Aquí el único parámetro del que depende la prueba son los grados de libertad \(v\), pero se muestra el valor de \(r\) encontrado
- Determinar valores críticos
- \(\alpha = .1\)
- \(t_{\alpha/2,v} = t_{.1/2,8} = |1.860|\)
- Calcular el estadístico de prueba
- \(t = \frac{r \sqrt{v}}{\sqrt{1-r^2}} = \frac{.597 \cdot \sqrt{8}}{\sqrt{1-.597^2}} = 2.10\)
- \(90\% \ IC \ [.066,.864]\)
- Tomar una decisión
- El estadístico de prueba es mayor al crítico, \(t > t_{\alpha/2,v}\)
- El valor-p es menor a \(\alpha = .1\), \(p = .068\)
- El valor de \(0\) no cae dentro del intervalo de confianza, \(IC \ [.066,.864]\)
- Decisión: Se rechaza \(H_0\)
- Nota: Tomar en cuenta que si se escogiera \(\alpha=.05\), no se rechazaría \(H_0\)
En R así como está la función cor para calcular el coeficiente de correlación, se tiene la función cor.test para la prueba específica. Se pueden especificar el tipo de correlación (method) y el nivel de significancia. El coeficiente de correlación es ya un tamaño de efecto, por lo que no es necesario realizar ningún cálculo adicional.
cantos = tibble(Canto = 1:10,
a = c(8,16,12,13,16,14,16,11,15,13),
b = c(7,8,10,12,14,9,13,6,9,10),
c = c(3,5,9,5,5,8,13,3,9,9))
a = 0.1
r.res = cor.test(~a+b,data = cantos,
method = 'pearson',
conf.level = 1-a)
r.res##
## Pearson's product-moment correlation
##
## data: a and b
## t = 2.1031, df = 8, p-value = 0.06861
## alternative hypothesis: true correlation is not equal to 0
## 90 percent confidence interval:
## 0.0661825 0.8641924
## sample estimates:
## cor
## 0.5966799Conclusión: Los ejes \(a\) y \(b\) están correlacionados, \(r = .60\), 90% IC \([.07\), \(.86]\), \(t(8) = 2.10\), \(p = .069\). El efecto se puede considerar grande, con un rango de pequeño, hasta muy grande.
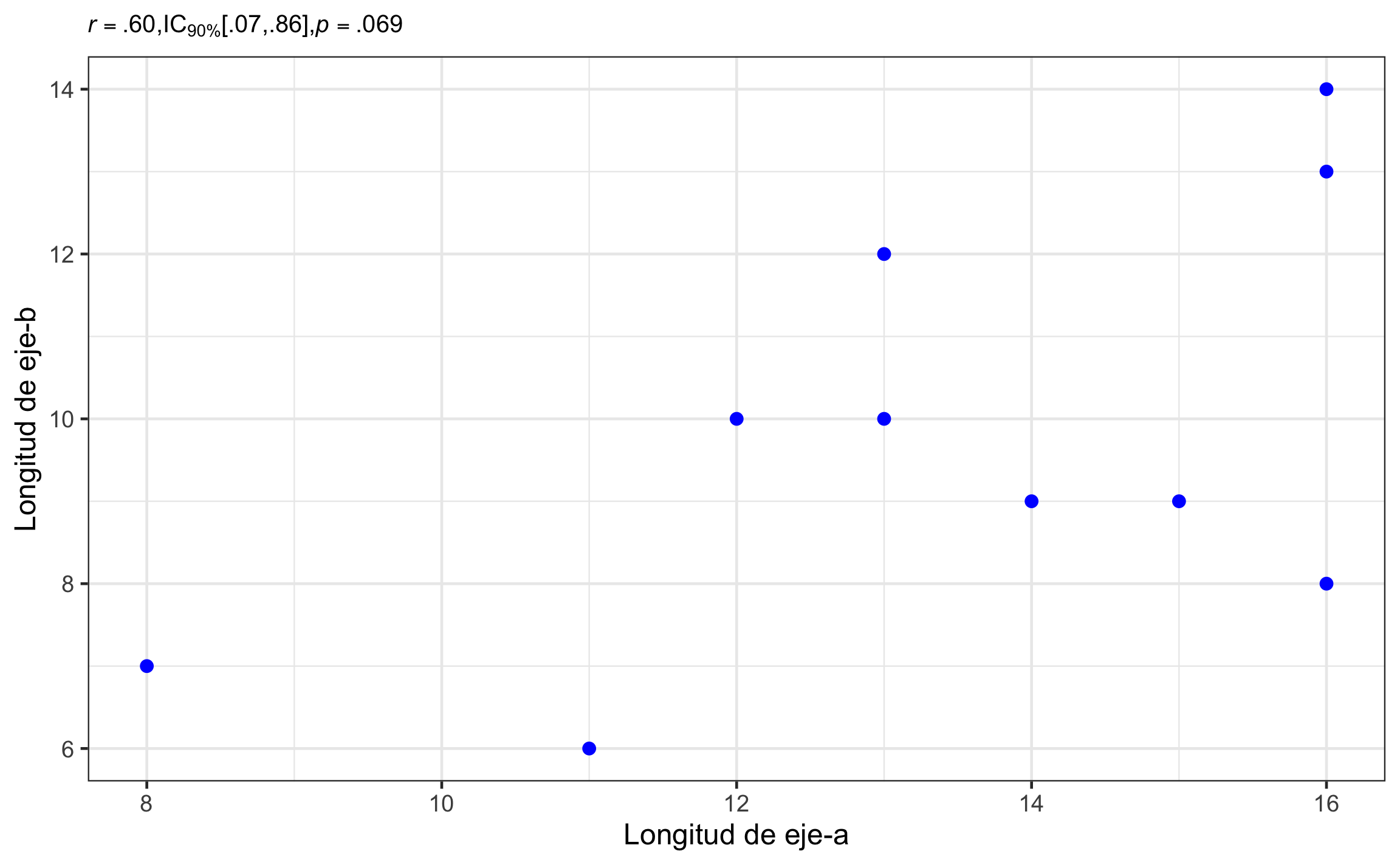
Figura 15.18: Gráfico de dispersión mostrando la relación entre longitud de 2 ejes de cantos de playa, así como el resumen estadístico respectivo.
15.10 Correlación Punto Biserial
La correlación punto biserial es una medida de asociación entre dos variables, donde una variable es cuantitativa continua y la otra es cualitativa con dos categorías (dicotómica). La idea de la correlación es determinar la asociación entre los niveles de la variable cualitativa con respecto a la variable continua. La prueba determina si hay una diferencia o relación significativa entre estas variables, o si hay un efecto de la variable cualitativa sobre la variable continua. Lo anterior es la misma idea tras la prueba \(t\) de dos muestras independientes, por lo que la conclusión es la misma pero con un tamaño de efecto diferente, \(r\) en vez de \(d\) (Field et al., 2012; Sheskin, 2011).
El procedimento para calcular esta correlación sería:
- Asignar una de las categorías como 1 y la otra como 0,
- Calcular la media de la variable continua para cada categoría (\(\bar{y}_1, \ \bar{y}_0\)),
- Calcular la desviación estándar de la variable continua (\(s_y\)),
- Calcular \(r_{pb}\) usando la Ecuación (15.12).
Lo anterior se demuestra a continuación con los datos del ejemplo usado en la prueba \(t\) de 2 muestras independientes (15.6), para demostrar que son homólogas y se obtienen las mismas conclusiones. Para determinar la significancia de la correlación punto biserial se usa la misma prueba \(t\) que se usó con la correlación de Pearson.
braq = braq %>%
mutate(ind.bin = ifelse(ind == 'A',1,0))
braq## # A tibble: 18 x 3
## values ind ind.bin
## <dbl> <fct> <dbl>
## 1 3.2 A 1
## 2 3.1 A 1
## 3 3.1 A 1
## 4 3.3 A 1
## 5 2.9 A 1
## 6 2.9 A 1
## 7 3.5 A 1
## 8 3 A 1
## 9 3.1 B 0
## 10 3.1 B 0
## 11 2.8 B 0
## 12 3.1 B 0
## 13 3 B 0
## 14 2.6 B 0
## 15 3 B 0
## 16 3 B 0
## 17 3.1 B 0
## 18 2.8 B 0N = nrow(braq)
braq %>%
group_by(ind.bin) %>%
summarise(media = mean(values),
n = n())## # A tibble: 2 x 3
## ind.bin media n
## <dbl> <dbl> <int>
## 1 0 2.96 10
## 2 1 3.12 8braq %>%
summarise(s_y = sd(values))## # A tibble: 1 x 1
## s_y
## <dbl>
## 1 0.2\[\begin{equation} r_{pb} = \frac{\bar{y}_1-\bar{y}_0}{s_y}\sqrt{\frac{n_1 n_0}{N(N-1)}}\\ r_{pb} = \frac{3.125-2.96}{0.2}\sqrt{\frac{8 \cdot 10}{18(18-1)}} = .422 \end{equation}\]
La dirección del efecto está únicamente en función de cuál categoría se escoge como 1. Lo que indica el valor de \(r_{pb} = .422\) es que hay una relación positiva hacia la capa A (los braquiópodos son más largos en la capa A), ya que ésta fue la que se codificó como 1.
- Identificar la población, distribución, y la prueba apropiada:
- Población: relación entre la longitud de braquiópodos y la capa a la que pertenecen
- Distribución: \(t\)
- Prueba: \(t\) de correlación
- Establecer las hipótesis nula y alterna:
- \(H_0: \rho_{pb} = 0 \to\) No hay relación entre la longitud de braquiópodos y la capa a la que pertenecen
- \(H_1: \rho_{pb} \neq 0 \to\) Hay una relación entre la longitud de braquiópodos y la capa a la que pertenecen
- Determinar parámetros de la distribución a comparar (\(H_0\)):
- \(r_{pb} = .422\)
- \(v = N-2 = 18-2 = 16\)
- Determinar valores críticos
- \(\alpha = .05\)
- \(t_{\alpha/2,v} = t_{.05/2,16} = |2.12|\)
- Calcular el estadístico de prueba
- \(t = \frac{r_{pb} \sqrt{v}}{\sqrt{1-r_{pb}^2}} = \frac{.422 \cdot \sqrt{16}}{\sqrt{1-.422^2}} = 1.86\)
- \(95\% \ IC \ [-.056,.742]\)
- Tomar una decisión
- El estadístico de prueba es menor al crítico, \(t < t_{\alpha/2,v}\)
- El valor-p es mayor a \(\alpha = .05\), \(p = .081\)
- El valor de \(0\) cae dentro del intervalo de confianza, \(IC \ [-.056,.742]\)
- Decisión: No se rechaza \(H_0\)
- Nota: Tomar en cuenta que si se escogiera \(\alpha=.1\), se rechazaría \(H_0\)
En R se usa la función cor.test con las columnas de la variable continua y la variable dicotómica (1 y 0), usando el tipo de correlación (method) de pearson, e indicando el nivel de significancia. El coeficiente de correlación es ya un tamaño de efecto, por lo que no es necesario realizar ningún cálculo adicional.
a = .05
rpb.res = cor.test(~values+ind.bin,data = braq,
method = 'pearson',
conf.level = 1-a)
rpb.res##
## Pearson's product-moment correlation
##
## data: values and ind.bin
## t = 1.861, df = 16, p-value = 0.08122
## alternative hypothesis: true correlation is not equal to 0
## 95 percent confidence interval:
## -0.05608465 0.74247724
## sample estimates:
## cor
## 0.4218307Estos resultados muestran el mismo valor \(t\) y mismo valor-p que la prueba \(t\) de 2 muestras independientes, demostrando que ambas son homólogas.
Conclusión: La longitud de los braquiópos no está correlacionada con la capa a la cual pertenecen, \(r_{pb} = .42\), 95% IC \([-.06\), \(.74]\), \(t(16) = 1.86\), \(p = .081\). El efecto se puede considerar mediano, con un rango amplio de muy pequeño, en la dirección opuesta, hasta muy grande.
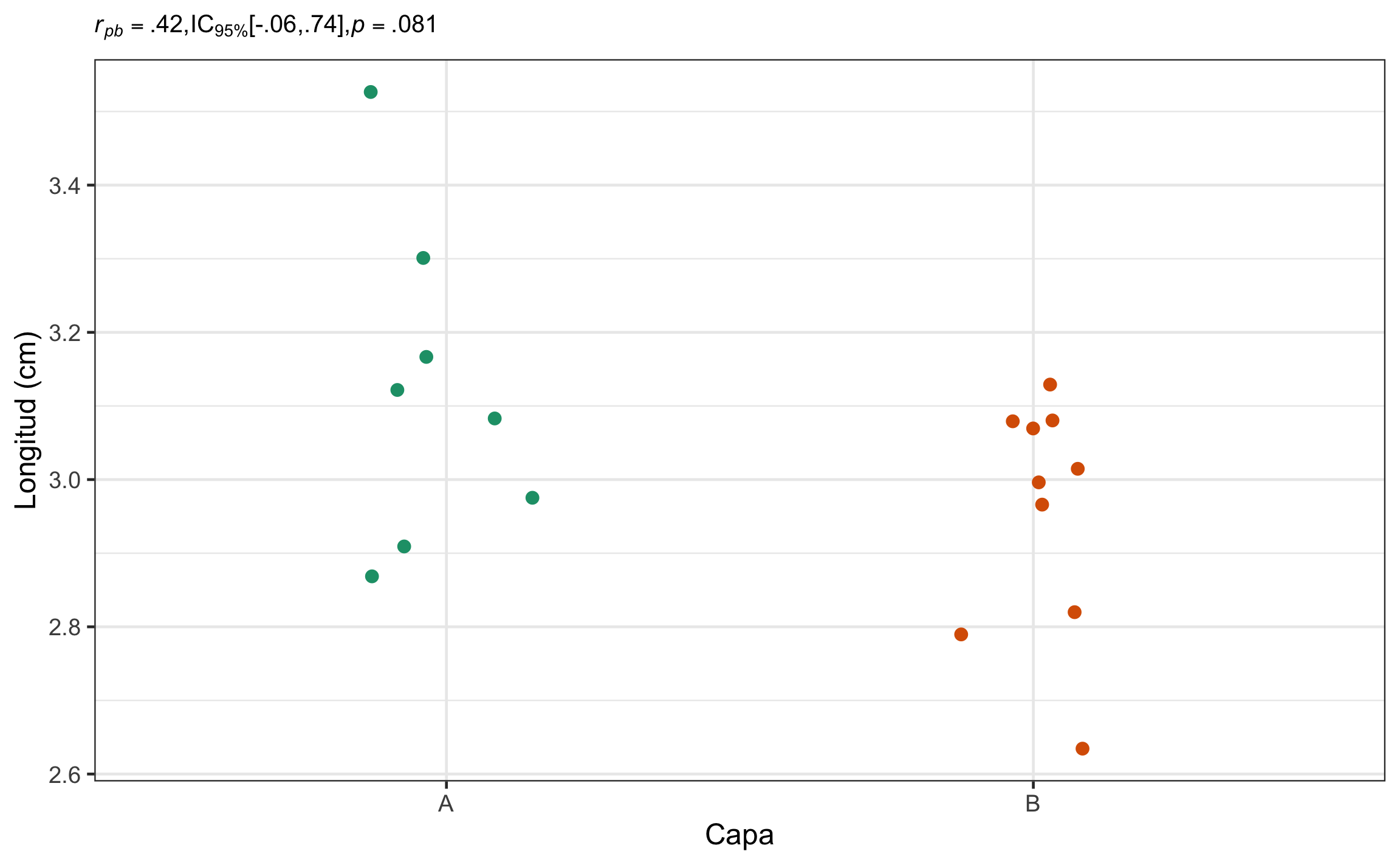
Figura 15.19: Gráfico de dispersión mostrando la relación entre longitud de los braquiópodos de acuerdo a la capa que pertencen, así como el resumen estadístico respectivo.
15.11 \(\chi^2\) para 1 varianza
Así como se pueden realizar pruebas estadísticas sobre la media poblacional (\(\mu\)), se pueden realizar pruebas estadísticas sobre la varianza poblacional (\(\sigma^2\)), aunque son menos comunes. Por esto último es que para estas pruebas no hay tamaños de efecto estandarizados, sino más bien se usan los datos en escala original.
El uso de la prueba \(\chi^2\) de 1 muestra se realiza con el ejemplo de la sección 14.2.3 (Swan & Sandilands, 1995), donde se tenía el contenido de cuarzo en secciones delgadas de una roca ígnea. Es posible que esta muestra provenga de una población con varianza 12 (\(\sigma^2_0=12\))? Asuma \(\alpha = .05\).
- Identificar la población, distribución, y la prueba apropiada:
- Población: variabilidad del contenido de cuarzo en la roca ígnea
- Distribución: de varianza
- Prueba: \(\chi^2\) de 1 muestra porque se tiene 1 muestra, se quiere hacer inferencia sobre la variabilidad, y se quiere comparar con un valor hipotético
- Establecer las hipótesis nula y alterna:
- \(H_0: \sigma^2 = \sigma^2_0 \to\) La variabilidad en el contenido de cuarzo en la roca ígnea es igual a un valor hipotético o conocido (12)
- \(H_1: \sigma^2 \neq \sigma^2_0 \to\) La variabilidad en el contenido de cuarzo en la roca ígnea es diferente a un valor hipotético o conocido (12)
- Determinar parámetros de la distribución a comparar (\(H_0\)):
- \(\sigma^2_0 = 20\)
- \(v = N-1 = 8-1 = 7\)
- Determinar valores críticos
- \(\alpha = .05\)
- \(\chi^2_{\alpha/2,v} = \chi^2_{.05/2,7} = 12.83\)
- \(\chi^2_{1-\alpha/2,v} = \chi^2_{1-0.05/2,7} = 0.83\)
- Calcular el estadístico de prueba
- \(\chi^2 = \frac{(n-1)s^2}{\sigma_0^2} = \frac{(8-1)9.507}{12} = 5.546\)
- \(4.16 < \sigma^2 < 39.38 \to 95\% \ IC \ [4.16,39.38]\)
- Tomar una decisión
- El estadístico de prueba cae entre los valores críticos
- El valor-p es mayor a \(\alpha = .05\), \(p = .8127\)
- El valor hipotético del parámetro cae dentro del intervalo de confianza, \(IC \ [4.16, 39.38]\)
- Decisión: No se rechaza \(H_0\)
En R el paquete DescTools trae la función VarTest para realizar esta prueba, donde ocupa brindar el vector de datos, la varianza poblacional (sigma.squared), y el nivel de confianza.
sigma0 = 12
a = 0.05
cuarzo = c(23.5, 16.6, 25.4, 19.1, 19.3, 22.4, 20.9, 24.9)
n = length(cuarzo)
chi.res = VarTest(x = cuarzo,
sigma.squared = sigma0,
conf.level = 1-a)
chi.res##
## One Sample Chi-Square test on variance
##
## data: cuarzo
## X-squared = 5.5457, df = 7, p-value = 0.8127
## alternative hypothesis: true variance is not equal to 12
## 95 percent confidence interval:
## 4.155981 39.381007
## sample estimates:
## variance of x
## 9.506964Conclusión: La variabilidad del contenido de cuarzo no difiere significativamente del valor propuesto, \(s^2 = 9.51\), 95% IC \([4.16\), \(39.38]\), \(\chi^2(7, n = 8) = 5.55\), \(p = .813\).
15.12 \(F\) para 2 varianzas
En algunas de las pruebas se hace la suposición de igualdad de varianzas. Lo anterior se puede evaluar empíricamente comparando la menor y mayor desviación estándar, donde la relación entre ellas no debiera ser mayor a 2 (Cumming & Calin-Jageman, 2017). Si se quiere realizar de manera formal se puede realizar la prueba aquí descrita.
El uso de la prueba \(F\) para 2 varianzas se realiza con el ejemplo de la sección 15.6 (Swan & Sandilands, 1995), donde se tenían braquiópodos en dos capas (A, B) y se les midió la longitud (cm). Es factible la suposición de igualdad de varianzas (\(\sigma^2_1=\sigma^2_2\))? Asuma \(\alpha = .05\).
- Identificar la población, distribución, y la prueba apropiada:
- Población: variabilidad de la longitud de braquiópodos en las capas A y B
- Distribución: de razón de varianzas (\(F\))
- Prueba: \(F\) para 2 muestras (varianzas), se quiere hacer inferencia sobre la variabilidad, y se quieren comparar las varianzas de 2 muestras
- Establecer las hipótesis nula y alterna:
- \(H_0: \sigma^2_1 = \sigma^2_2, \ \frac{\sigma^2_1}{\sigma^2_2} = 1 \to\) La variabilidad la longitud de braquiópodos de la capa A es igual a la variabilidad la longitud de braquiópodos de la capa B
- \(H_1: \sigma^2_1 \neq \sigma^2_2, \ \frac{\sigma^2_1}{\sigma^2_2} \neq 1 \to\) La variabilidad la longitud de braquiópodos de la capa A es diferente a la variabilidad la longitud de braquiópodos de la capa B
- Determinar parámetros de la distribución a comparar (\(H_0\)):
- \(v_1 = n_1-1 = 8-1 = 7\)
- \(v_2 = n_2-1 = 10-1 = 9\)
- Determinar valores críticos
- \(\alpha = .05\)
- \(F_{\alpha/2,v_1,v_2} = F_{.05/2,8,10} = 3.85\)
- \(F_{1-\alpha/2,v_1,v_2} = F_{1-0.05/2,8,10} = 0.23\)
- Calcular el estadístico de prueba
- \(\frac{\sigma^2_1}{\sigma^2_2} = \frac{0.042}{0.029} = 1.45\)
- \(0.345 < \frac{\sigma^2_1}{\sigma^2_2} < 6.985 \to 95\% \ IC \ [0.345,6.985]\)
- Tomar una decisión
- El estadístico de prueba cae entre los valores críticos
- El valor-p es mayor a \(\alpha = .05\), \(p = .599\)
- El valor hipotético del parámetro (1) cae dentro del intervalo de confianza, \(IC \ [0.345, 6.985]\)
- Decisión: No se rechaza \(H_0\)
En R la función var.test para realizar esta prueba, donde se ocupan brindar los vectores de datos, la razón de varianzas (ratio), y el nivel de confianza.
a = 0.05
f.res = var.test(x = A,y = B,
ratio = 1,
conf.level = 1-a)
f.res##
## F test to compare two variances
##
## data: A and B
## F = 1.4367, num df = 7, denom df = 9, p-value = 0.5994
## alternative hypothesis: true ratio of variances is not equal to 1
## 95 percent confidence interval:
## 0.3423094 6.9294596
## sample estimates:
## ratio of variances
## 1.436688Conclusión: La variabilidad de la longitud de los braquiópodos en las capas A y B no varia significativamente, \(\text{razón de varianzas} = 1.44\), 95% IC \([0.34\), \(6.93]\), \(F(7, 9) = 1.44\), \(p = .599\).
Referencias
American Psychological Association. (2010). Publication Manual of the American Psychological Association (6.ª ed.).
Ben-Shachar, M. S., Makowski, D., & Lüdecke, D. (2020). effectsize: Indices of Effect Size and Standardized Parameters. https://CRAN.R-project.org/package=effectsize
Borradaile, G. J. (2003). Statistics of Earth Science Data: Their Distribution in Time, Space and Orientation. Springer-Verlag Berlin Heidelberg.
Buchanan, E. M., Gillenwaters, A. M., Scofield, J. E., & Valentine, K. D. (2019). MOTE: Effect Size and Confidence Interval Calculator. https://CRAN.R-project.org/package=MOTE
Cohen, J. (1988). Statistical Power Analysis for the Behavioral Sciences (2.ª ed.). Erlbaum.
Cumming, G. (2012). Understanding The New Statistics - Effect Sizes, Confidence Intervals, and Meta-Analysis. Rutledge.
Cumming, G., & Calin-Jageman, R. (2017). Introduction to the New Statistics: Estimation, Open Science, and Beyond. Rutledge.
Cumming, G., & Finch, S. (2005). Inference by Eye: Confidence Intervals and How to Read Pictures of Data. American Psychologist, 60(2), 170-180. https://doi.org/10.1037/0003-066X.60.2.170
Davis, J. C. (2002). Statistics and Data Analysis in Geology (3.ª ed.). John Wiley & Sons.
Ellis, P. D. (2010). The Essential Guide to Effect Sizes : Statistical Power, Meta-Analysis, and the Interpretation of Research Results. Cambridge University Press.
Erceg-Hurn, D., Cumming, G., & Calin-Jageman, R. (2017). itns: Datasets from the book Introduction to the New Statistics.
Field, A., Miles, J., & Field, Z. (2012). Discovering Statistics Using R. SAGE Publications Ltd.
Fritz, C. O., Morris, P. E., & Richler, J. J. (2012). Effect size estimates: Current use, calculations, and interpretation. Journal of Experimental Psychology: General, 141(1), 2-18. https://doi.org/10.1037/a0024338
Grissom, R. J., & Kim, J. J. (2005). Effect Sizes for Research: A Broad Practical Approach. Erlbaum.
Hedges, L. V., & Olkin, I. (1985). Statistical Methods for Meta-Analysis. Academic Press.
Lakens, D. (2013). Calculating and reporting effect sizes to facilitate cumulative science: A practical primer for t-tests and ANOVAs. Frontiers in Psychology, 4. https://doi.org/10.3389/fpsyg.2013.00863
Magnusson, K. (2020). Interpreting Cohen’s d Effect Size: An Interactive Visualization (Versión 2.1.1) [Computer software]. https://rpsychologist.com/d3/cohend/
McGrath, R. E., & Meyer, G. J. (2006). When effect sizes disagree: The case of r and d. Psychological Methods, 11(4), 386-401. https://doi.org/10.1037/1082-989X.11.4.386
McGraw, K. O., & Wong, S. P. (1992). A Common Language Effect Size Statistic. Psychonomic Bulletin, 111(2), 361-365.
McKillup, S., & Darby Dyar, M. (2010). Geostatistics Explained: An Introductory Guide for Earth Scientists. Cambridge University Press. www.cambridge.org/9780521763226
Nakagawa, S., & Cuthill, I. C. (2007). Effect size, confidence interval and statistical significance: A practical guide for biologists. Biological Reviews, 82(4), 591-605. https://doi.org/10.1111/j.1469-185X.2007.00027.x
Nolan, S. A., & Heinzen, T. E. (2014). Statistics for the Behavioral Sciences (3.ª ed.). Worth Publishers.
Olejnik, S., & Algina, J. (2000). Measures of Effect Size for Comparative Studies: Applications, Interpretations, and Limitations. Contemporary Educational Psychology, 25(3), 241-286. https://doi.org/10.1006/ceps.2000.1040
Reiser, B., & Faraggi, D. (1999). Confidence intervals for the overlapping coefficient: The normal equal variance case. Journal of the Royal Statistical Society, 48(3), 413-418.
Revelle, W. (2020). psych: Procedures for Psychological, Psychometric, and Personality Research. https://CRAN.R-project.org/package=psych
Ruscio, J. (2008). A probability-based measure of effect size: Robustness to base rates and other factors. Psychological Methods, 13(1), 19-30. https://doi.org/10.1037/1082-989X.13.1.19
Sheskin, D. J. (2011). Handbook of Parametric and Nonparametric Statistical Procedures (5.ª ed.). CRC Press.
Swan, A., & Sandilands, M. (1995). Introduction to Geological Data Analysis. Blackwell Science.
Thompson, B. (2007). Effect sizes, confidence intervals, and confidence intervals for effect sizes. Psychology in the Schools, 44(5), 423-432. https://doi.org/10.1002/pits.20234
Tomczak, M., & Tomczak, E. (2014). The need to report effect size estimates revisited. An overview of some recommended measures of effect size. Trends in Sport Sciences, 1(21), 19-25.
Torchiano, M. (2018). effsize: Efficient Effect Size Computation. https://CRAN.R-project.org/package=effsize
Trauth, M. (2015). MATLAB® Recipes for Earth Sciences (4.ª ed.). Springer-Verlag Berlin Heidelberg.
Triola, M. F. (2004). Probabilidad y Estadística (9.ª ed.). Pearson Educación.
Walpole, R. E., Myers, R. H., & Myers, S. L. (2012). Probabilidad y Estadística Para Ingeniería y Ciencias. Pearson.
Zou, G. Y. (2007). Toward using confidence intervals to compare correlations. Psychological Methods, 12(4), 399-413. https://doi.org/10.1037/1082-989X.12.4.399