Capítulo 19 Geoestadística
19.1 Introducción
En este capítulo se va a introducir el análisis geoestadístico. La geoestadística es una rama de la estadística espacial, donde el principal objetivo es la caracterización de sistemas espaciales que no son por completo conocidos, o sea, hay incertidumbre. La situación típica es tener mediciones de una variable en ciertos puntos, y se quiere conocer (estimar, interpolar, simular) la distribución de esta variable en una región. Por lo anterior, una diferencia con la estadística clásica es que la ubicación de la muestra es importante y es un factor en el análisis, por lo que las muestras no van a ser independientes, sino que se espera que presenten una relación (dependencia) espacial.
La geoestadística se puede usar principalmente con dos fines: interpolación (estimación) o simulación. En la interpolación (estimación) lo que se hace es obtener el valor promedio de la variable de interés, mientras que en la simulación lo que se hace es generar N posibles realizaciones de dicha variable, sujetos (condicionados) o no a datos observados (medidos).
En cierta forma, la dependencia espacial, es similar a la auto-correlación (18.3.2), pero a diferencia de ésta, que trabaja con datos en 1 dimensión (\(x\) o \(t\)), la geoestadística lidia con la relación de una o más variables en 2 (\(x\), \(y\)), 3 (\(x\), \(y\), \(z\) o \(t\)), e inclusive 4 (\(x\), \(y\), \(z\), \(t\)) dimensiones.
Lo que se va a presentar y explicar en este capítulo se basa en extractos de capítulos de Davis (2002), Swan & Sandilands (1995), Borradaile (2003), y McKillup & Darby Dyar (2010), así como textos más exhaustivos y completamente dedicados a esta temática, dentro de los cuales Chilès & Delfiner (1999), Cressie (1993), Goovaerts (1997), Isaaks & Srivastava (1989), Webster & Oliver (2007), y Wackernagel (2003), corresponden con referencias clásicas y actualizadas. Para base teórica y práctica de cómo implementarlo en R se recomienda consultar Nowosad (2019) y Pebesma & Bivand (2020a).
19.2 Métodos de interpolación
De manera breve se mencionan diferentes métodos que se pueden usar, y han sido comúnmente utilizados, para la interpolación de variables en dos o más dimensiones. De manera general se tienen:
- Polígonos de Thiessen
- Triangulación
- Vecinos naturales (natural neighbours)
- Inverso de la distancia (inverse distance)
- Superficies de tendencia (trend surface)
- Ajuste polinomial (splines)
- Kriging
El énfasis de este capítulo (y de la geoestadística en general) va a ser el método de Kriging, el cual se considera (cuando aplica) como el método más robusto y preciso en comparación con el resto. En inglés se le conoce como blue que quiere decir best linear unbiased estimator y significa mejor estimador lineal no sesgado. A diferencia del resto, Kriging brinda una estimación del error de interpolación, por lo que se puede determinar la precisión de los resultados.
19.3 Conceptos de geoestadística
En esta sección se definen algunos conceptos fundamentales en geoestadística, que forman las bases teóricas y prácticas para el análisis geoestadístico (19.4).
19.3.1 Variable regionalizada
Es una variable aleatoria que varía localmente pero tiene una dependencia (estructura) regional, o sea su valor depende de la ubicación.
19.3.2 Correlación espacial
Hay una relación que depende de la distancia entre observaciones, donde datos más cercanos entre si se relacionan más que datos más alejados.
19.3.3 Diagrama de dispersión-\(h\) (\(h\)-scatterplot)
Muestra cómo varia una variable con respecto a si misma a una distancia \(h\) y dirección específica (Figura 19.1). Conforme los valores son menos similares, la nube de puntos se ensancha y dispersa más con respecto a la línea \(x=y\).
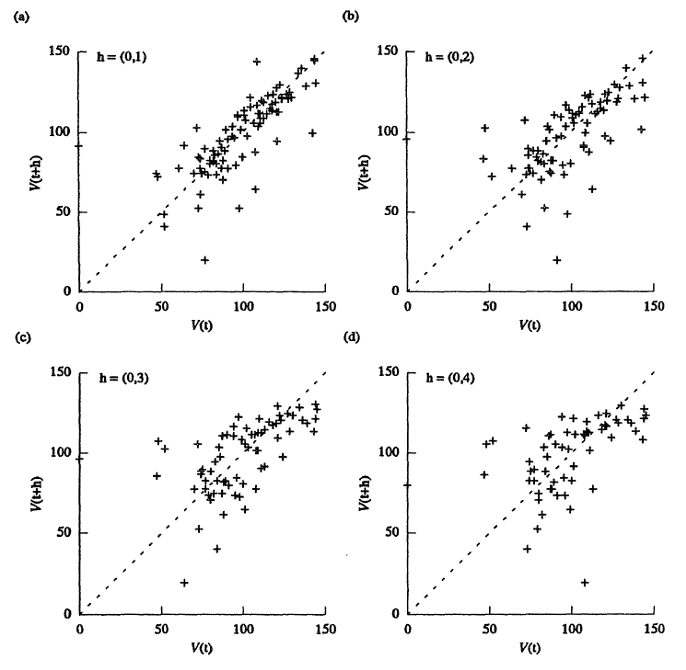
Figura 19.1: Ejemplo de diagrama de dispersión-\(h\), donde se observa como al incrementar la distancia la dispersión incrementa. Tomado de Isaaks & Srivastava (1989).
19.3.4 Semivarianza
Medida de disimilitud espacial que varía con la distancia entre observaciones, y se expresa mediante la Ecuación (19.1), donde \(Z(x_i)\) es el valor de la variable en la posición \(x_i\), \(Z(x_i+h)\) es el valor de la variable a una distancia \(h\), \(N\) es el número total de puntos (observaciones), y \(N(h)\) es el número de pares de puntos que se encuentran a una distancia \(h\) específica. A modo de recomendación se deben tener más de 30 pares de puntos por cada distancia, y no calcularla a más de la mitad de la máxima distancia.
\[\begin{equation} \gamma(h) = \frac{1}{2N(h)}\sum_{i=1}^{N(h)} [Z(x_i+h)-Z(x_i)]^2 \tag{19.1} \end{equation}\]
Para datos en una grilla regular se puede calcular usando al separación entre puntos como las diferentes distancias \(h\) (Figura 19.2). Para datos irregularmente espaciados es necesario agrupar los puntos en bandas (Figura 19.3), donde hay que definir una tolerancia de la distancia (\(w\), por lo general \(h/2\)), y una tolerancia angular (\(\alpha/2\)).
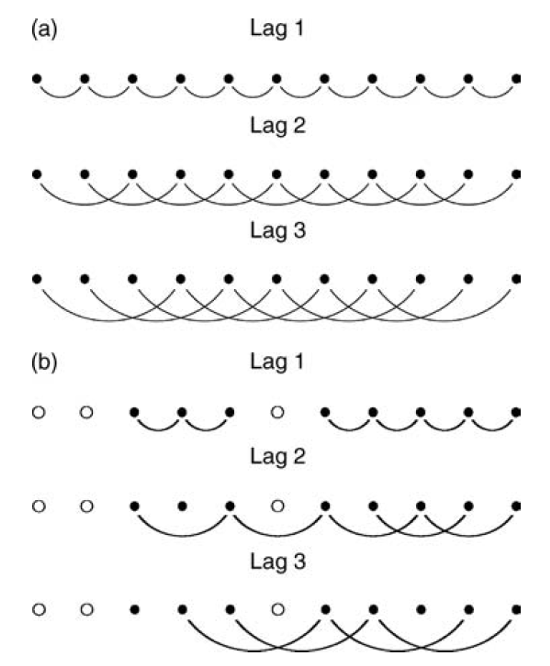
Figura 19.2: Esquema del calculo de la semivarianza para diferentes distancias donde los datos están completos (a) y donde hay vacíos de datos (b). Tomado de Webster & Oliver (2007).
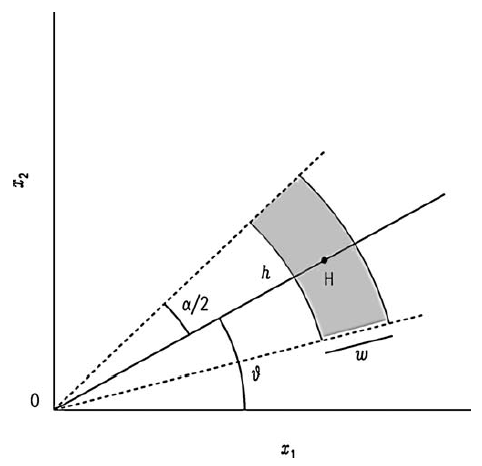
Figura 19.3: Esquema del calculo de la semivarianza para diferentes distancias donde los datos están irregularmente espaciados. Tomado de Webster & Oliver (2007).
19.3.5 Variograma experimental
Representación discreta de la relación espacial de la variable, donde se muestra como varía la semivarianza (para cada \(h\)) con respecto a la distancia (Figura 19.4). Se construye a partir de los datos y es similar a un diagrama de dispersión. Este un paso importante en el análisis geoestadístico (19.4), ya que el usuario/analista tiene completo control sobre la construcción del variograma. Es importante definir la distancia máxima, recordando que no debe ser más de la mitad de la máxima separación entre puntos, y el intervalo de distancias, o sea, cada cuánto se va a calcular la semivarianza. Estos parámetros van a controlar el cálculo del variograma y por ende el ajuste de un modelo y la interpolación.
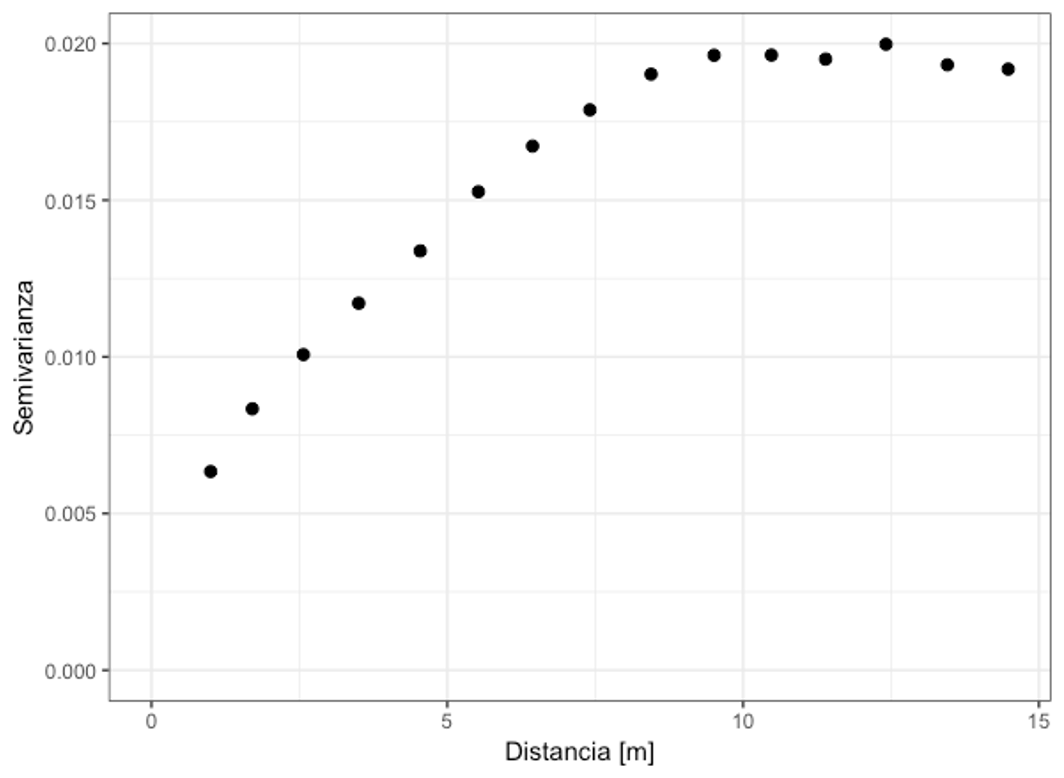
Figura 19.4: Ejemplo de variograma experimental, mostrando la relación espacial de la variable.
19.3.6 Modelo de variograma
Para poder hacer predicciones a cualquier distancia es necesario ajustar un modelo al variograma experimental, similar al ajuste lineal para un diagrama de dispersión. Para poder ajustar un modelo es necesario determinar las partes que lo van a componer (Figura 19.5):
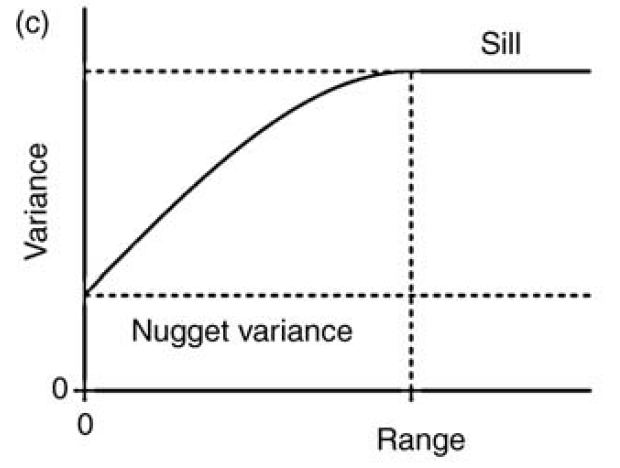
Figura 19.5: Modelo de variograma mostrando las partes: meseta, pepita, y rango. Tomado de Webster & Oliver (2007).
- Meseta total (\(S\), sill): Cota superior del variograma o el limite del variograma cuando la distancia \(h\) tiende a infinito, y por lo general corresponde con el valor de la varianza de la variable de interés.
- Meseta parcial (\(C_1\), partial sill): Es la diferencia entre la meseta total y la pepita (\(C_1 = S - C_0\)). Si no hay pepita (\(C_0=0\)), entonces \(C_1 = S\).
- Pepita (\(C_0\), nugget): El intercepto y representa una discontinuidad puntual del semivariograma en el origen.
- Rango (\(a\), range): Zona de influencia, la distancia a partir de la cual dos observaciones son independientes, el variograma se estabiliza y se alcanza la meseta.
19.3.6.1 Tipos
- Potencia
Este modelo se usa cuando el variograma experimental no presenta una meseta, y se estima mediante la Ecuación (19.2), donde \(\alpha\) es la pendiente, \(0<\lambda<2\) y controla la concavidad o convexidad del modelo. Se representa como se muestra en la Figura 19.6.
\[\begin{equation} \gamma(h) = C_0 + \alpha h^{\lambda} \tag{19.2} \end{equation}\]
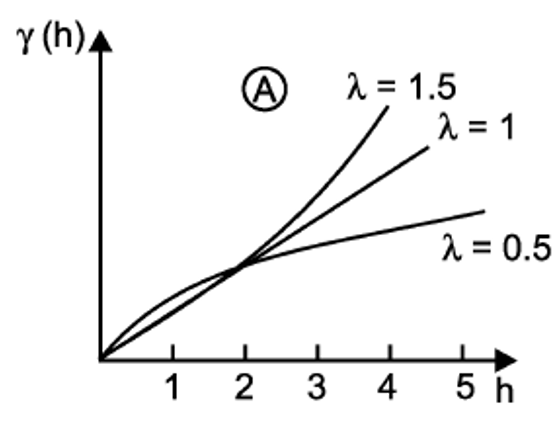
Figura 19.6: Modelo de potencia. Tomado de Sarma (2009).
- Esférico
Este modelo presenta una meseta clara, es de los más usados en ciencias de la tierra y tiene un comportamiento lineal cerca del origen, y se estima mediante la Ecuación (19.3). Se representa como se muestra en la Figura 19.7.
\[\begin{equation} \gamma(h) = \begin{cases} C_0 + C_1 \left[ \frac{3}{2}\left( \frac{h}{a}\right) - \frac{1}{2}\left( \frac{h}{a}\right)^3 \right] & \text{para } h < a\\ C_0 + C_1 & \text{para } h > a \end{cases} \tag{19.3} \end{equation}\]
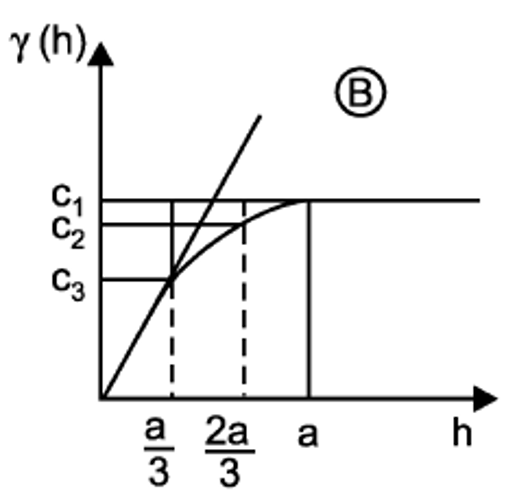
Figura 19.7: Modelo esférico. Tomado de Sarma (2009).
- Exponencial
Este modelo no alcanza una meseta sino más bien tiene un comportamiento asintótico, y se estima mediante la Ecuación (19.4). Como no alcanza una meseta lo que se usa en el modelo como rango es \(r=a/3\), o sea, una tercera parte del rango esperado. Se representa como se muestra en la Figura 19.8.
\[\begin{equation} \gamma(h) = C_0 + C_1 \left[ 1 - exp\left(-\frac{h}{r}\right) \right] \tag{19.4} \end{equation}\]
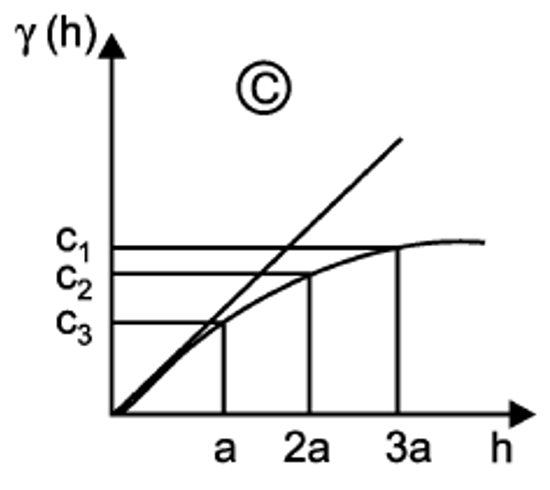
Figura 19.8: Modelo exponencial. Tomado de Sarma (2009).
- Gaussiano
Este modelo, similar al exponencial, no alcanza una meseta sino más bien tiene un comportamiento asintótico, además tiene un comportamiento suavizado cerca del origen. Como no alcanza una meseta lo que se usa en el modelo como rango es \(r=a/\sqrt{3}\), o sea, el rango esperado entre la raíz de 3. Se estima mediante la Ecuación (19.5), y se representa como se muestra en la Figura 19.9.
\[\begin{equation} \gamma(h) = C_0 + C_1 \left[ 1 - exp\left(-\frac{h}{r}\right)^2 \right] \tag{19.5} \end{equation}\]
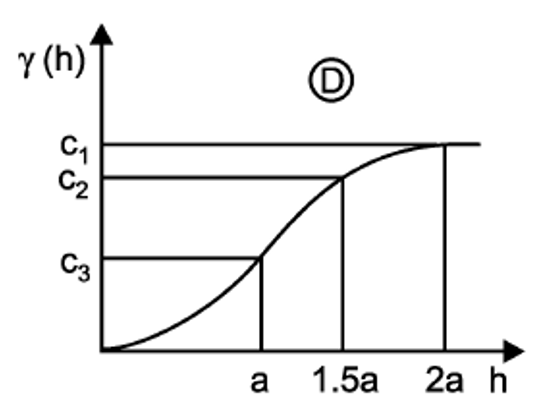
Figura 19.9: Modelo gaussiano. Tomado de Sarma (2009).
La Figura 19.10 muestra los tres modelos más usados en geociencias, donde todos representan una estructura con los parámetros: \(C_0=0\), \(C_1=30\), y \(a=210\). Se observa como el modelo esférico tiene un comportamiento lineal cerca del origen, el modelo exponencial un comportamiento más creciente, y el modelo gaussiano un comportamiento suavizado. Además, los modelos exponencial y gaussiano no alcanzan la meseta, mientras que el esférico sí la alcanza.
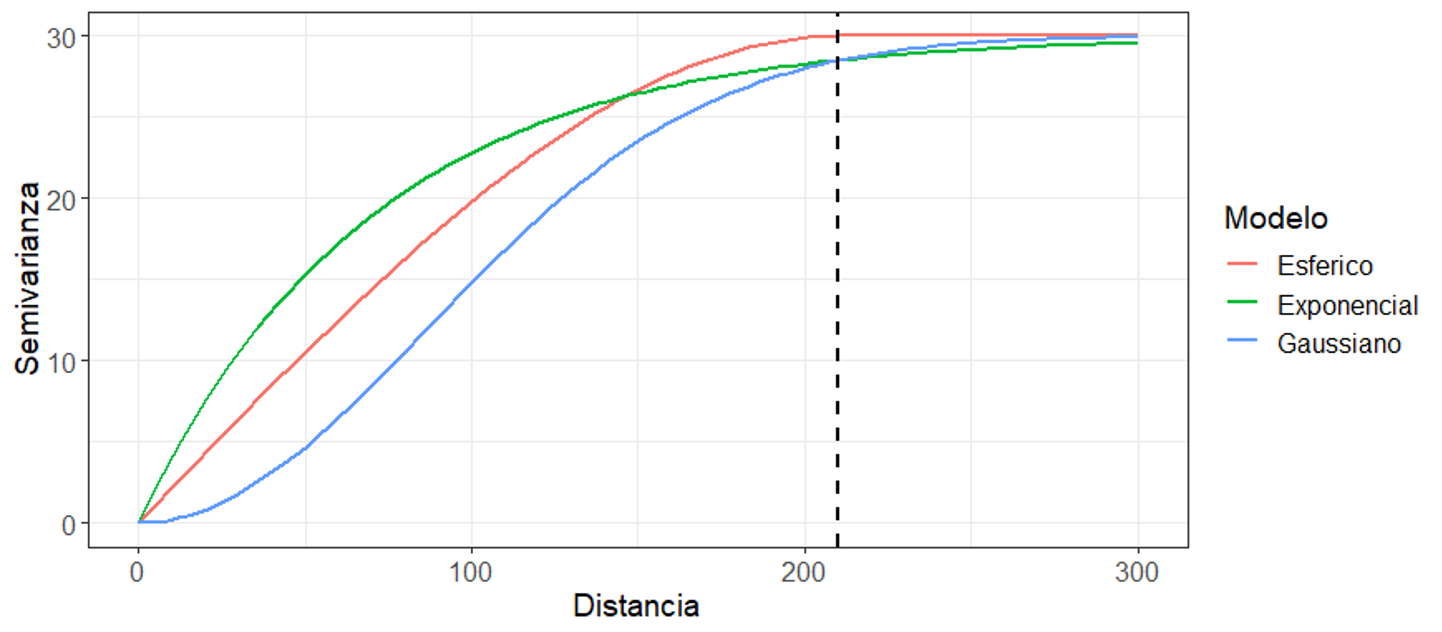
Figura 19.10: Comparación visual de los tres modelos más usados en geociencias, todos respresentando la misma estructura (\(C_0=0\), \(C_1=30\), y \(a=210\)).
19.3.7 Anisotropía
La correlación espacial puede no solo depender de la distancia sino también de la dirección. Si la correlación depende de la dirección se denomina anisotrópica (direccional). Si la correlación no depende de la dirección se denomina isotrópica (omnidireccional). El tipo de anisotropía más común, y fácil de modelar, es la anisotropía geométrica, donde se tiene la misma meseta pero diferente rango en diferentes direcciones. La anisotropía zonal es donde se tiene diferente mesetas en diferentes direcciones.
La anisotropía se puede detectar por medio de lo que se conoce como mapa de la superficie de variograma (Figura 19.11 A) y/o variogramas direccionales (Figura 19.11 B). De manera general, para la anisotropía geométrica, va a haber una dirección principal que va a coincidir con la dirección que presenta el mayor rango (donde hay más continuidad espacial), y una dirección menor que ocurre de forma perpendicular a la principal. En el caso de la Figura 19.11 la dirección principal ocurre a los 35° y la menor a los 125°. La razón entre la dirección menor y principal se conoce como razón de anisotropía y varía entre 0 y 1, donde valores pequeños indican una fuerte anisotropía y valores altos indican poca o nula anisotropía.
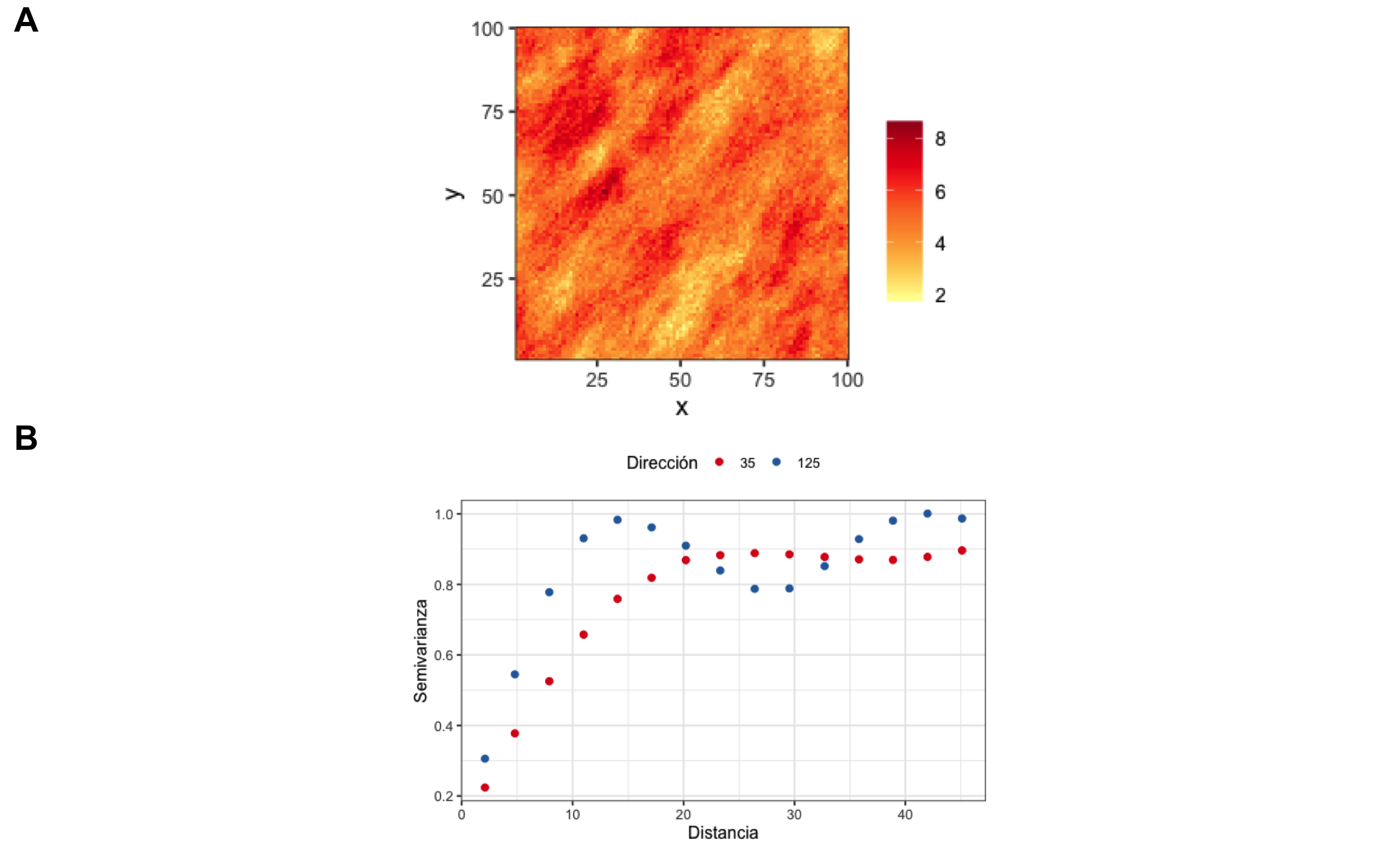
Figura 19.11: A Ejemplo de mapa de la superficie de variograma, mostrando anisotropía donde el eje principal ocurre en la dirección 35 y el eje menor ocurre en la dirección 125. B Variogramas direccionales donde se observa como en la dirección de 35 se alcanza un rango mayor (\(\sim 25\)), mientras que en la dirección perpendicular (125) el rango es menor (\(\sim 15\))
19.3.8 Validación cruzada
El ajuste de un modelo de variograma es mejor evaluado por medio de lo que se conoce como validación cruzada. Esta técnica se puede emplear de dos maneras: LOO (leave-one-out) o K-Fold, en inglés. LOO implica que iterativamente se deja por fuera cada uno de los puntos muestreados y con el modelo ajustado se predice el valor en ese punto, obteniéndose así un error con el valor conocido y el predecido. K-Fold divide los puntos en K bloques (folds), dejando un bloque por fuera a la vez y prediciendo valores para todos los puntos de este bloque con el modelo ajustado, y se repite para cada uno de los K bloques. Para cantidades de datos grandes K-Fold es más rápido que LOO.
Para evaluar el ajuste se tienen diferentes métricas, y la idea es comparar cada una de estas métricas para diferentes modelos ajustados y escoger el modelo que presente mejores métricas.
- Error medio (\(ME\)): Esta métrica corresponde con la media de los errores (residuales), e idealmente se tiene una media de 0. Se expresa mediante la Ecuación (19.6). Comparando modelos se escogería el que presente un error más cercano a 0.
\[\begin{equation} ME = \frac{1}{N} \sum_{i=1}^{N} (Y_i-\hat{Y_i}) \tag{19.6} \end{equation}\]
- Error cuadrático medio (\(RMSE\)): Esta métrica cuantifica la desviación promedio entre los valores observados y predecidos, donde idealmente se desean valores pequeños. Se expresa mediante la Ecuación (19.7). Comparando modelos se escogería el que presente un \(RMSE\) menor.
\[\begin{equation} RMSE = \sqrt{\frac{1}{N} \sum_{i=1}^{N} (Y_i-\hat{Y_i})^2} \tag{19.7} \end{equation}\]
- Razón de desviación cuadrática media (\(MSDR\)): Esta métrica compara que tan cerca está la diferencia entre predicción y valor actual con respecto a la varianza obtenida de la interpolación (error/varianza de Kriging, \(s^2_{ei}\)). Idealmente este valor debería andar cerca de 1. Se expresa mediante la Ecuación (19.8). Comparando modelos se escogería el que presente un MSDR más cercano a 1.
\[\begin{equation} MSDR = \frac{1}{N} \sum_{i=1}^{N} \frac{(Y_i-\hat{Y_i}^2)}{s^2_{ei}} \tag{19.8} \end{equation}\]
19.3.9 Kriging
Método de interpolación (estimación) que utiliza toda la información procedente del variograma experimental y su ajuste para obtener unos factores de ponderación optimizados. El valor interpolado (estimado) corresponde con una media ponderada basada en la distancia e información del variograma (correlación espacial). Es el mejor ajuste posible con respecto a los puntos más cercanos (al punto a interpolar) en el variograma teórico (modelo). Los puntos que estén dentro del rango van a tener influencia sobre el punto a interpolar, y mientras más alejados los puntos menos peso y menos influencia. Lo anterior se resume en la Figura 19.12.
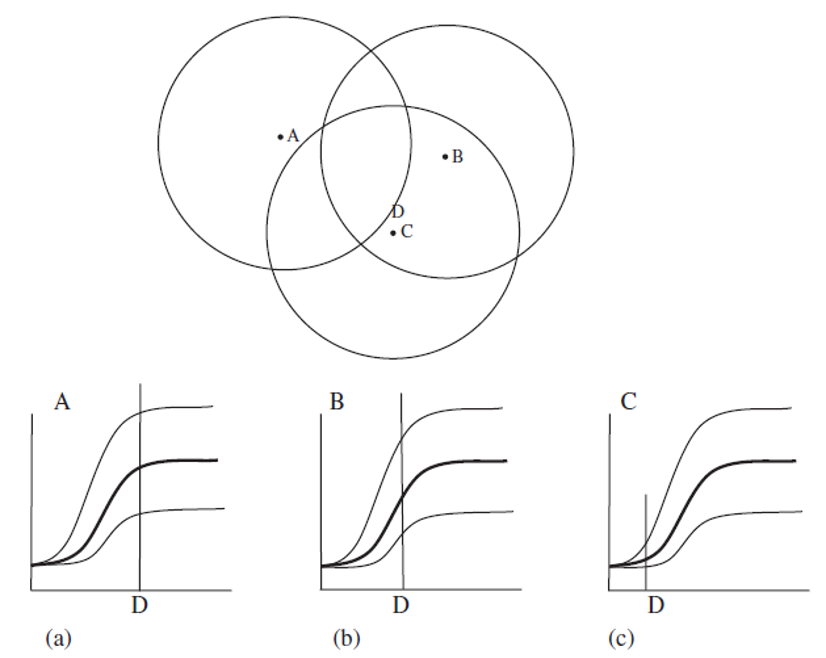
Figura 19.12: Visualización del proceso de interpolación mediante Kriging, donde para el punto a interpolar (D), el punto que está más cercano (C) tiene más peso (influencia, baja semivarianza), y el punto más lejano (A) prácticamente no tiene peso ya que cae fuera del rango. Tomado de McKillup & Darby Dyar (2010).
Dentro de las ventajas del Kriging están:
- Compensa por efectos de agrupamiento (clustering), al dar menos peso individual a puntos dentro del agrupamiento que a puntos aislados,
- Da una estimación de la variable y del error (varianza de Kriging).
La interpolación resultante presenta las siguientes características (Figura 19.13):
- Suaviza los resultados (puede variar dependiendo del modelo usado en el ajuste),
- Sobre-estima valores pequeños y sub-estima valores grandes.
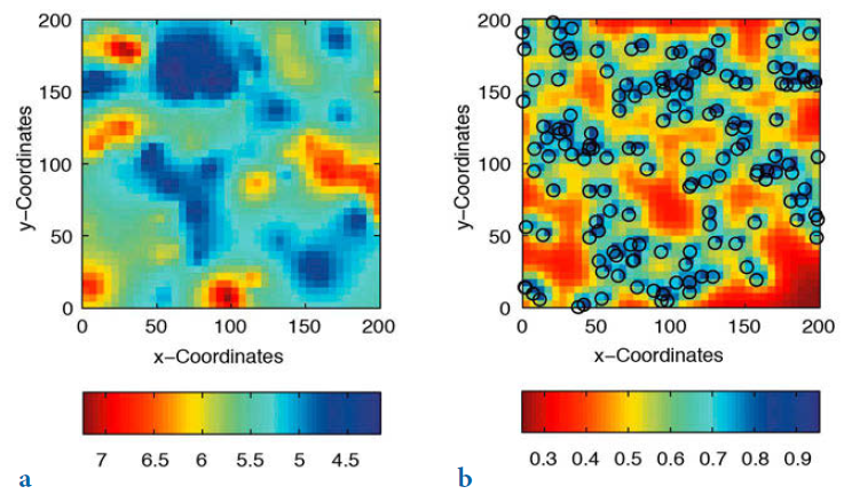
Figura 19.13: Ejemplo del resultado de interpolación (a), y su error (b), por medio de Kriging. Tomado de Trauth (2015).
Kriging es una metodología general, por lo que hay varios tipos dependiendo de lo que se tenga (conozca), las características de la variable y cantidad y tipos de variables. En general Kriging funciona mejor cuando los datos están normalmente distribuidos y son estacionarios, esto último quiere decir que hay poca o ninguna variación en la media y varianza de la(s) variable(s). Además, si los datos presentan una tendencia (el variograma no alcanza una meseta) es necesario lidiar con ésto, lo se puede trabajar de dos maneras: se trabaja con los residuales al remover la tendencia (esencialmente lo que hace el Kriging Universal), o se ajusta un modelo que no alcance una meseta (potencia).
Los tipos de Kriging más comunes son:
- Simple: En este caso se asume que se conoce la media de la variable (lo cual no es necesariamente cierto), y que ésta es constante. Por lo anterior no es práctico de usar.
- Ordinario: Éste es el más usado, se asume una media constante pero no conocida, y además los datos no deben tener una tendencia.
- Lognormal: Se usa cuando los datos tienen una fuerte asimetría positiva, y corresponde con aplicar Kriging Ordinario sobre los datos log-transformados, por lo general usando el logaritmo natural. La transformación inversa del resultado de la interpolación NO es simplemente exponenciar los resultados, por lo que hay que tener cuidado con esto. Cressie (1993), Webster & Oliver (2007) y otros proveen más detalles y las fórmulas específicas para realizar la transformación inversa de manera apropiada.
- Universal: Para el caso en que la media es no constante y no conocida, se le conoce como Kriging con tendencia. Esta es una forma de lidiar con datos con tendencia, como el caso típico de niveles piezométricos.
- CoKriging: Se usa cuando se requiere lidiar con 2 o más variables, es la versión multivariable de Kriging ordinario. Las variables deben presentar co-regionalización, lo que quiere decir que las variables tienen que variar conjuntamente en el espacio.
- Indicador: Se usa cuando los datos son cualitativos (categóricos) o se transforman datos cuantitativos en cualitativos, y lo que se obtiene es la probabilidad condicional de cada categoría. Puede lidiar con cualquier distribución de los datos, por lo que se considera un método no-paramétrico.
19.4 Análisis geoestadístico
Esta sección muestra cómo realizar un análisis geoestadístico completo, usando como ejemplo los datos de jura que fueron inicialmente presentados y trabajados por Goovaerts (1997), y vienen en el paquete gstat (Pebesma & Graeler, 2020), donde vienen varios juegos de datos y el que se va a usar es jura.pred. En estos datos, que se ubican en la región de Jura en Suiza, se va a enfocar el análisis en el contenido de cobre (Cu). El paquete gstat es el principal paquete que se va a usar para el análisis geoestadístico.
19.4.1 Análisis Exploratorio de Datos
La idea de este análisis inicial, exploratorio, es determinar la distribución de la variable de interés, para determinar si es necesaria alguna transformación para que presenten una distribución aproximadamente normal. Además, se determina la varianza que va a ser una aproximación de la meseta del variograma.
data('jura',package = 'gstat')
datos = jura.pred
myvar = 'Cu' # variable a modelar
summary(datos)## Xloc Yloc long lat Landuse
## Min. :0.626 Min. :0.580 Min. :6.828 Min. :47.12 Forest : 33
## 1st Qu.:2.282 1st Qu.:1.487 1st Qu.:6.849 1st Qu.:47.12 Pasture: 56
## Median :3.043 Median :2.581 Median :6.859 Median :47.13 Meadow :165
## Mean :2.980 Mean :2.665 Mean :6.858 Mean :47.14 Tillage: 5
## 3rd Qu.:3.665 3rd Qu.:3.752 3rd Qu.:6.867 3rd Qu.:47.15
## Max. :4.920 Max. :5.690 Max. :6.884 Max. :47.16
## Rock Cd Co Cr
## Argovian :53 Min. :0.1350 Min. : 1.552 Min. : 8.72
## Kimmeridgian:85 1st Qu.:0.6375 1st Qu.: 6.520 1st Qu.:27.44
## Sequanian :63 Median :1.0700 Median : 9.760 Median :34.84
## Portlandian : 3 Mean :1.3091 Mean : 9.303 Mean :35.07
## Quaternary :55 3rd Qu.:1.7150 3rd Qu.:11.980 3rd Qu.:42.22
## Max. :5.1290 Max. :17.720 Max. :67.60
## Cu Ni Pb Zn
## Min. : 3.96 Min. : 4.20 Min. : 18.96 Min. : 25.20
## 1st Qu.: 11.02 1st Qu.:13.80 1st Qu.: 36.52 1st Qu.: 55.00
## Median : 17.60 Median :20.56 Median : 46.40 Median : 73.56
## Mean : 23.73 Mean :19.73 Mean : 53.92 Mean : 75.08
## 3rd Qu.: 27.82 3rd Qu.:25.42 3rd Qu.: 60.40 3rd Qu.: 89.92
## Max. :166.40 Max. :53.20 Max. :229.56 Max. :219.32Desc(datos[[myvar]],plotit = F)## ------------------------------------------------------------------------------
## datos[[myvar]] (numeric)
##
## length n NAs unique 0s mean meanCI
## 259 259 0 225 0 23.727 21.193
## 100.0% 0.0% 0.0% 26.262
##
## .05 .10 .25 median .75 .90 .95
## 5.916 7.576 11.020 17.600 27.820 48.800 60.780
##
## range sd vcoef mad IQR skew kurt
## 162.440 20.713 0.873 11.505 16.800 2.843 11.751
##
## lowest : 3.96, 4.2, 4.4, 4.44, 4.52
## highest: 96.0, 106.8, 112.04, 120.8, 166.4(S = var(datos[[myvar]])) # varianza de la variable## [1] 429.0132ggplot(datos, aes_string(myvar)) +
geom_histogram(aes(y = stat(density)), bins = 10,
col = 'black', fill = 'blue', alpha = .5) +
geom_vline(xintercept = mean(datos[[myvar]]), col = 'red') +
geom_density(col = 'blue') +
labs(y = 'Densidad')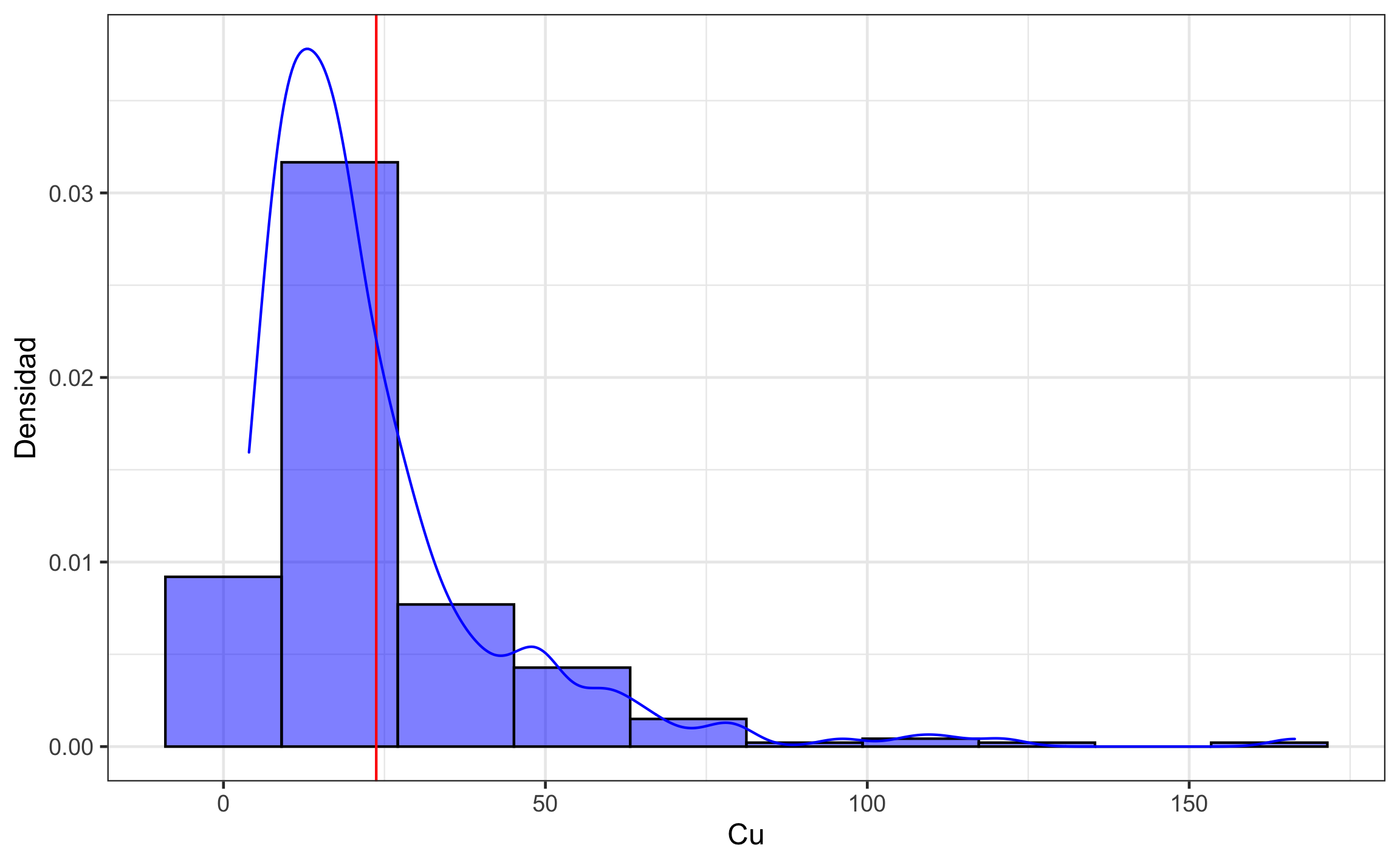
Figura 19.14: Distribución de los datos crudos del contenido de Cu.
Como los datos muestran una fuerte asimetría positiva \(>1\) (Figura 19.14), es necesario trabajar con el logaritmo de los datos. Si la asimetría estuviera entre 0.5 y 1, se podría trabajar con la raíz cuadrada de los datos.
datos = datos %>%
mutate(logCu = log(Cu))
myvar = 'logCu' # variable a modelar
Desc(datos[[myvar]],plotit = F)## ------------------------------------------------------------------------------
## datos[[myvar]] (numeric)
##
## length n NAs unique 0s mean meanCI
## 259 259 0 225 0 2.903282 2.817260
## 100.0% 0.0% 0.0% 2.989303
##
## .05 .10 .25 median .75 .90 .95
## 1.777658 2.024965 2.399631 2.867899 3.325749 3.887730 4.107256
##
## range sd vcoef mad IQR skew kurt
## 3.738151 0.703021 0.242147 0.684137 0.926118 0.322519 -0.076503
##
## lowest : 1.376244, 1.435085, 1.481605, 1.490654, 1.508512
## highest: 4.564348, 4.670958, 4.718856, 4.794136, 5.114395(S = var(datos[[myvar]])) # varianza de la variable## [1] 0.4942381ggplot(datos, aes_string(myvar)) +
geom_histogram(aes(y = stat(density)), bins = 10,
col = 'black', fill = 'blue', alpha = .5) +
geom_vline(xintercept = mean(datos[[myvar]]), col = 'red') +
geom_density(col = 'blue') +
labs(y = 'Densidad')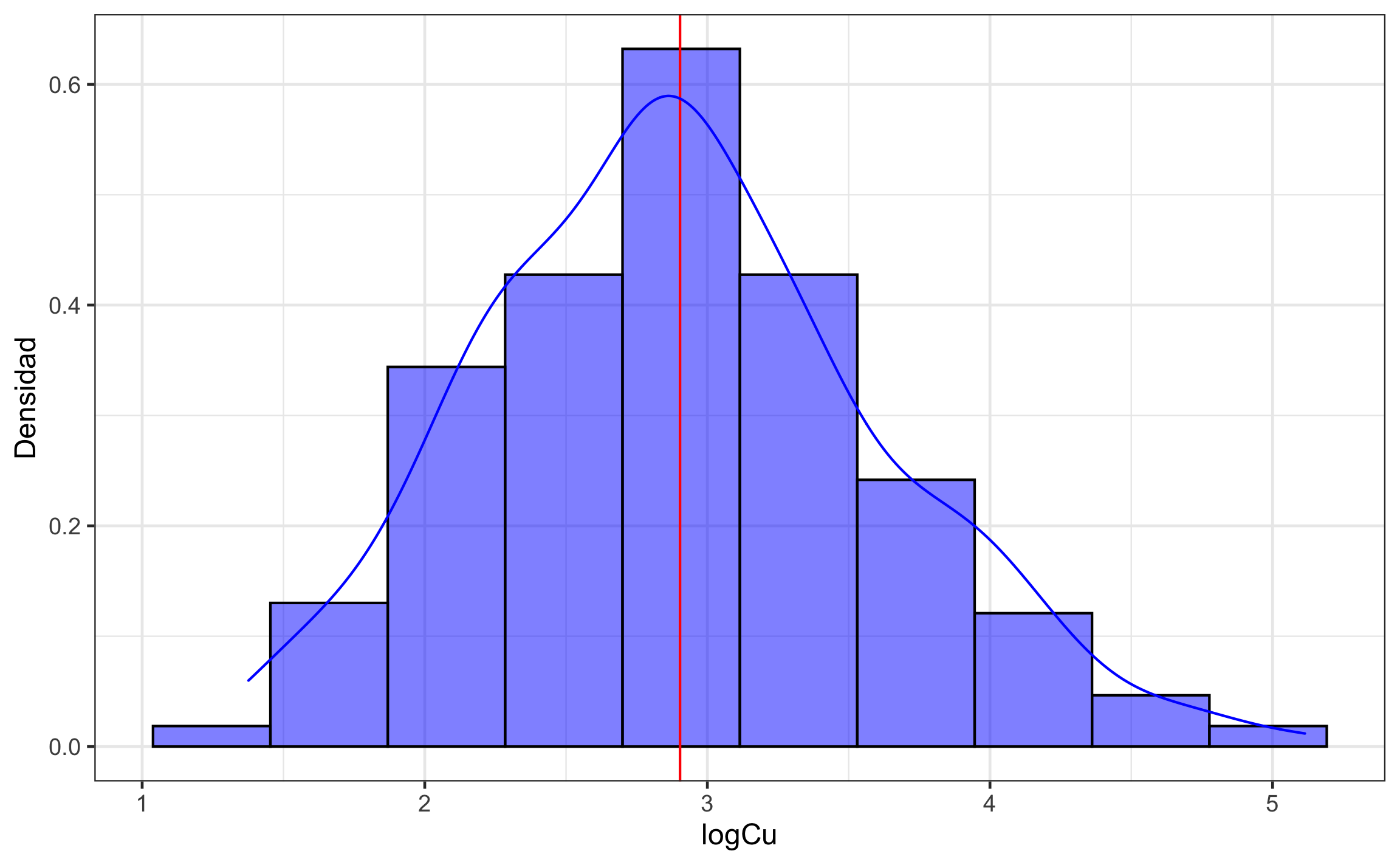
Figura 19.15: Distribución de los datos log-transformados del contenido de Cu.
Ya con la transformación los datos muestran una distribución aproximadamente normal (Figura 19.15), por lo que son más aptos para el modelado geoestadístico.
Antes de proceder con el modelado geoestadístico en R, es necesario convertir los datos en objetos espaciales y realizar ciertas operaciones previas para preparar y estudiar los datos.
Los datos traen información de dos sistemas de coordenadas, uno local (x,y) y otro global (long, lat). Para efectos de cálculos es recomendado trabajar en sistemas planos (x,y). Para pasar a objeto espacial se usa la función st_as_sf del paquete sf (Pebesma, 2020a), donde los argumentos son los datos, las columnas donde están las coordenadas, y el código del sistema de coordenadas. En este caso se van a usar la latitud y longitud, y posteriormente se van a transformar al sistema plano local, para trabajar con unidades plana (SI).
datos_sf = st_as_sf(datos, coords = 3:4, crs = 4326) %>%
st_transform(21781) %>%
mutate(X = st_coordinates(.)[,1], Y = st_coordinates(.)[,2]) %>%
relocate(X, Y)
datos_sp = as(datos_sf, 'Spatial')
coordnames(datos_sp) = c('X','Y')Es importante conocer las distancias ya que no es recomendado calcular el variograma experimental a distancias mayores a la mitad de la distancia máxima. El siguiente bloque de código calcula las distancias para usar como referencia.
dists = st_distance(datos_sf) %>% .[lower.tri(.)] %>% unclass()
distancias = signif(c(min(dists), mean(dists), max(dists)),6) # rango de distancias
names(distancias) = c('min', 'media', 'max')
distancias## min media max
## 4.97591 2036.87000 5597.05000Una opción para representar los datos y el resultado de la interpolación, es usando el polígono que encierra los datos. El siguiente bloque realiza el cálculo de dicho polígono.
outline = st_convex_hull(st_union(datos_sf))Hay que definir una grilla sobre la cual se va a realizar la interpolación, los puntos a los cuáles se les va a estimar el valor de la variable de interés. El siguiente bloque calcula una grilla rectangular y una versión recortada conforme el polígono anterior, generando objetos stars (Pebesma, 2020b) que son similares a objetos raster (Hijmans, 2020a) pero más versátiles, y que se usan en general para arreglos espaciales.
bb = st_bbox(datos_sf)
dint = max(c(bb[3]-bb[1],bb[4]-bb[2])/nrow(datos_sf))
dx = seq(bb[1],bb[3],dint) # coordenadas x
dy = seq(bb[4],bb[2],-dint) # coordenadas y
st_as_stars(matrix(0, length(dx), length(dy))) %>%
st_set_dimensions(1, dx) %>%
st_set_dimensions(2, dy) %>%
st_set_dimensions(names = c("X", "Y")) %>%
st_set_crs(st_crs(datos_sf)) -> datosint
datosint2 = st_crop(datosint, outline)Siempre es importante visualizar la distribución espacial de los datos. Las Figuras 19.16 y 19.17 muestran mapas estáticos e interactivos, respectivamente, de los datos, donde los puntos se encuentran rellenados con el contenido de Cu log-transformado.
ggplot() +
geom_sf(data = outline, col = 'cyan', alpha = .1, size = .75) +
geom_sf(data = datos_sf, aes_string(col = myvar), size = 3, alpha = 0.6) +
scale_color_viridis_c() +
labs(x = x_map, y = y_map) +
if (!is.na(st_crs(datos_sf))) {
coord_sf(datum = st_crs(datos_sf))
}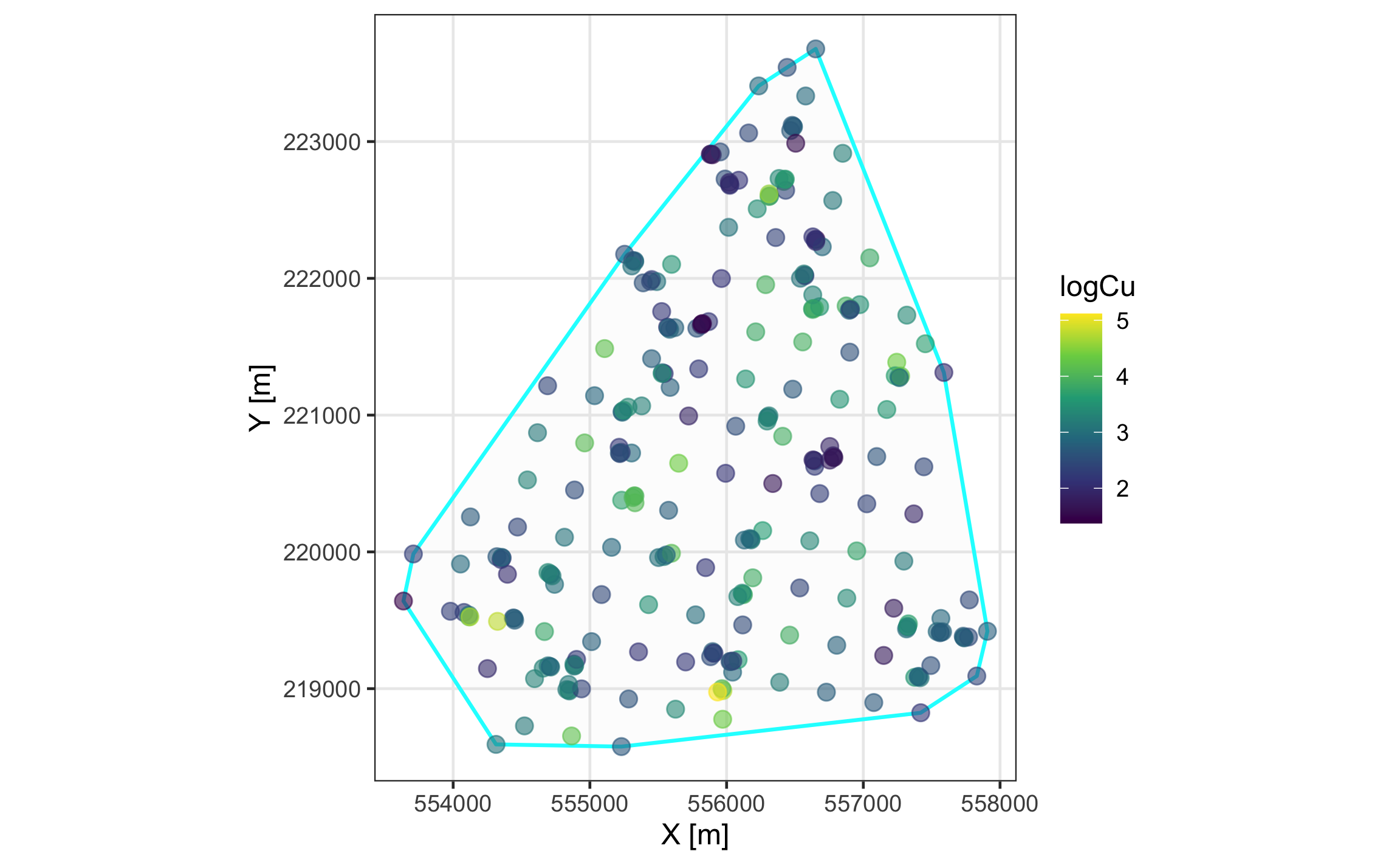
Figura 19.16: Mapa estático de la distribución espacial de los datos.
mapview(outline, alpha.regions = 0, layer.name='Border',
homebutton = F, legend = F, native.crs = F) +
mapview(datos_sf, zcol = myvar, alpha=0.1,
layer.name = myvar, native.crs = F,
col.regions = brewer.pal(9,'YlOrRd'))Figura 19.17: Mapa interactivo de la distribución espacial de los datos.
19.4.2 Modelado geoestadístico
Ya con los datos presentando una distribución aproximadamente normal, y los objetos espaciales definidos, se puede proceder al modelado geoestadístico. En este caso se va a usar Kriging Lognormal, que es aplicar Kriging Ordinario a los datos log-transformados.
19.4.2.1 Variograma experimental
Lo primero es crear el variograma omnidireccional (Figura 19.18). Para esto se crea un objeto gstat donde se define la fórmula y los datos a usar. La fórmula para el caso de Kriging Ordinario es similar a modelar solamente el intercepto (variable ~ 1), mientras que para el Kriging Universal sería similar a agregar predictores (variable ~ predictor), donde comúnmente se usan las coordenadas (variable ~ X + Y).
Para crear el variograma como tal, se usa la función variogram, que tiene como argumentos el objeto gstat, el intervalo de distancia (width) y la distancia máxima a la cual calcular la semivarianza (cutoff).
g = gstat(formula = as.formula(paste(myvar,'~1')),
data = datos_sf) # objeto gstat para hacer geoestadistica
# variograma experimental cada cierta distancia (width), y hasta cierta distancia (cutoff)
dat.vgm = variogram(g,
width = 100,
cutoff = 1500) ggplot(dat.vgm,aes(x = dist, y = gamma)) +
geom_point(size = 2) +
labs(x = x_var, y = y_var) +
geom_hline(yintercept = S, col = 'red', linetype = 2) +
ylim(0, max(dat.vgm$gamma)) +
xlim(0, max(dat.vgm$dist)) +
geom_text_repel(aes(label = np), size = 3)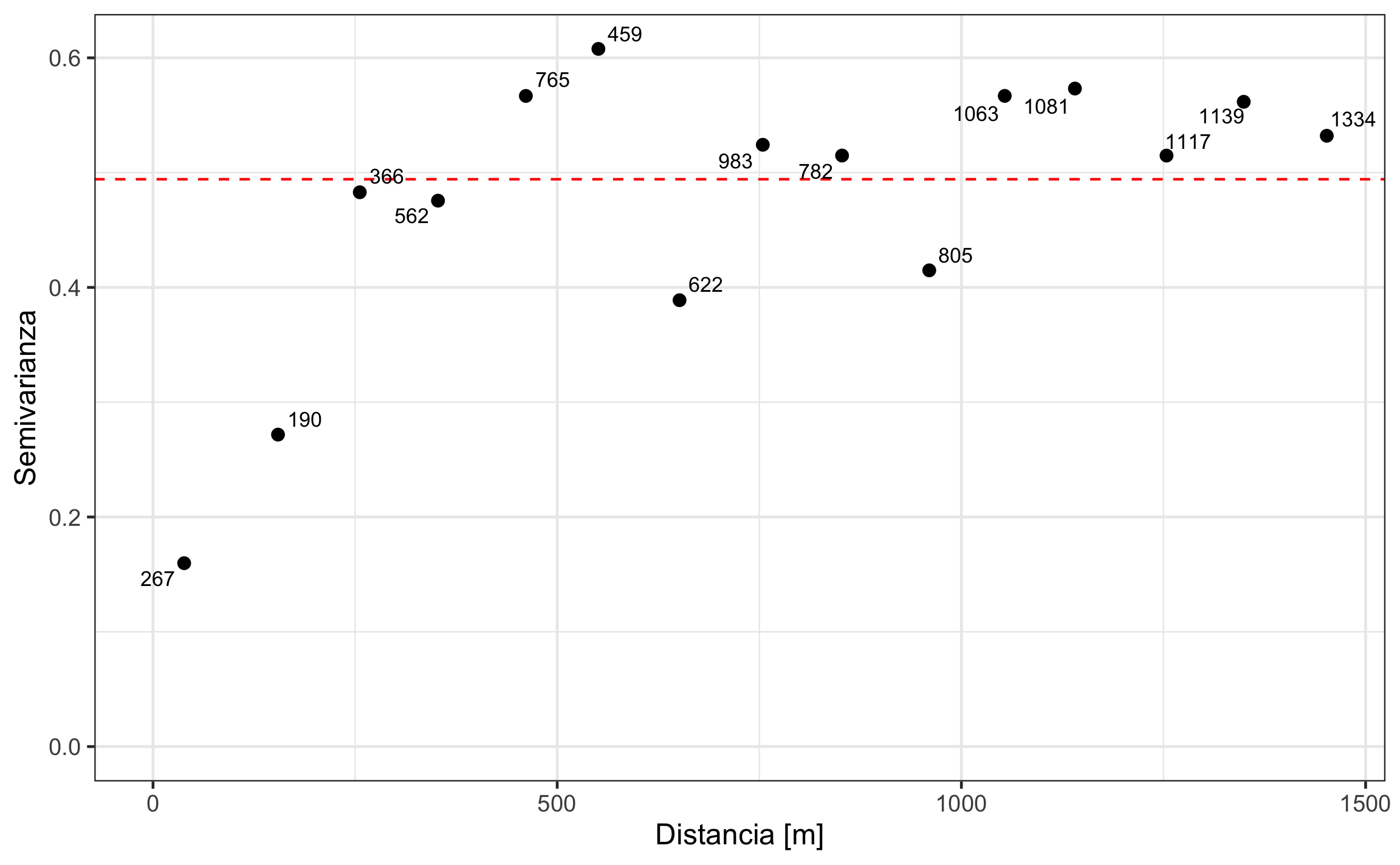
Figura 19.18: Variograma omnidireccional del logaritmo de Cu. Las etiquetas de los puntos corresponden con el número de pares de puntos usados para el cálculo de la semivarianza. La línea roja punteada corresponde con la varianza de los datos, que es una aproximación a la meseta de los datos.
Para evaluar la anisotropía se realizan tanto el mapa de la superficie de variograma (Figura 19.19), como los variogramas direccionales (Figura 19.20). Para el mapa de la superficie de variograma es necesario definir la extensión (cutoff), el ancho del pixel (width, no es el mismo que para el variograma), y definir que es un mapa (map=TRUE).
map.vgm <- variogram(g,
width = 200,
cutoff = 1500,
map = TRUE)ggplot(data.frame(map.vgm), aes(x = map.dx, y = map.dy, fill = map.var1)) +
geom_raster() +
scale_fill_gradientn(colours = plasma(20)) +
labs(x = x_vmap, y = y_vmap, fill = "Semivarianza") +
coord_equal()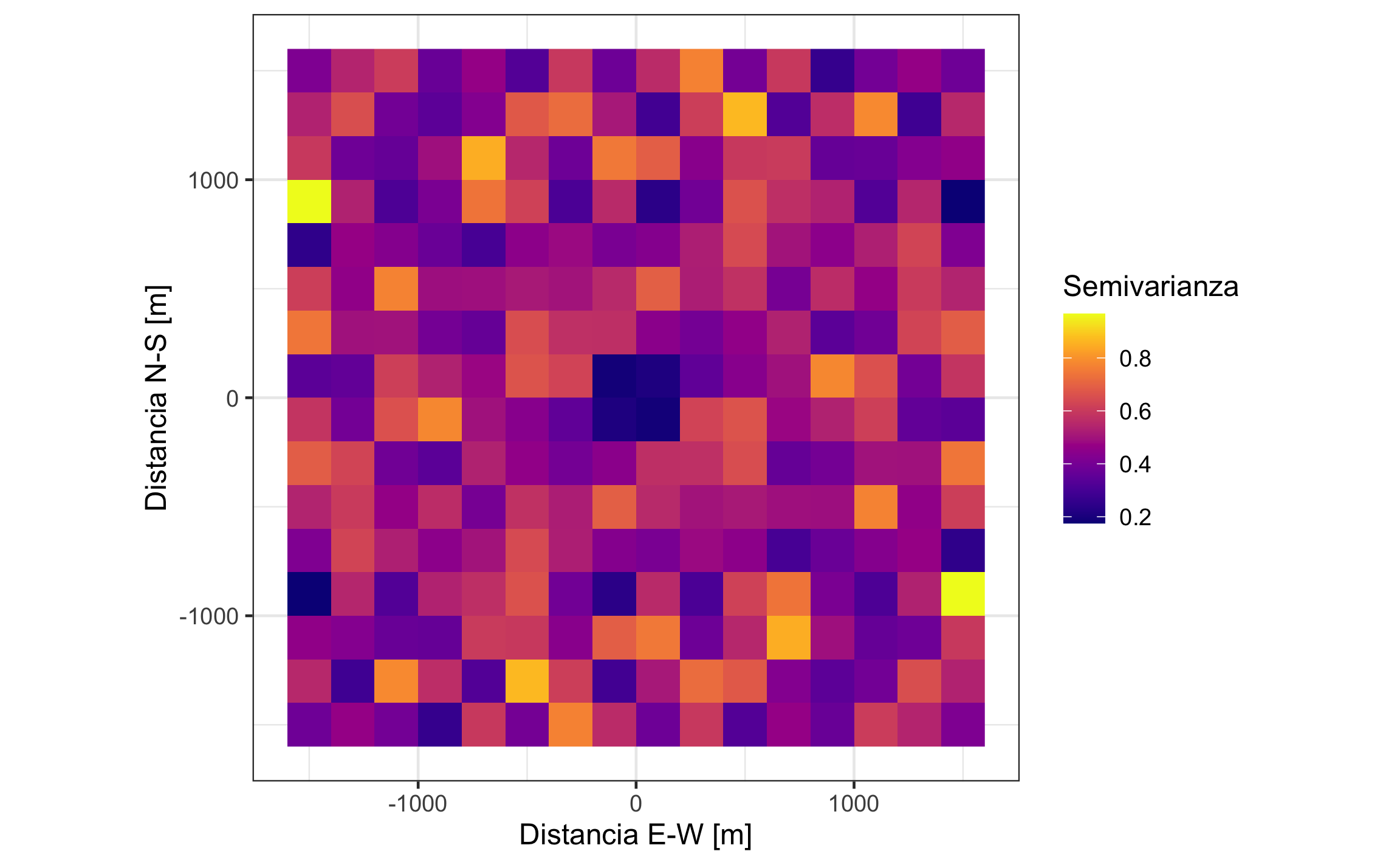
Figura 19.19: Mapa de la superficie de variograma para los datos del logaritmo de Cu.
Para el caso de los variogramas direccionales es necesario definir las direcciones (alpha) y la tolerancia angular (tol.hor), donde lo acostumbrado es usar direcciones cada 45° y la tolerancia angular es la mitad del intervalo entre direcciones.
dat.vgm2 = variogram(g,
alpha = c(0,45,90,135),
tol.hor = 22.5,
cutoff = 1500) # con direcciones y tolerancia angularggplot(dat.vgm2,aes(x = dist, y = gamma,
col = factor(dir.hor), shape = factor(dir.hor))) +
geom_point(size = 2) +
# geom_line() +
labs(x = x_var, y = y_var, col = "Dirección", shape = 'Dirección') +
geom_hline(yintercept = S, col = 'red', linetype = 2) +
ylim(0, max(dat.vgm2$gamma)) +
xlim(0, max(dat.vgm2$dist)) +
scale_color_brewer(palette = 'Dark2') +
facet_wrap(~dir.hor) +
geom_text_repel(aes(label = np), size = 3, show.legend = F)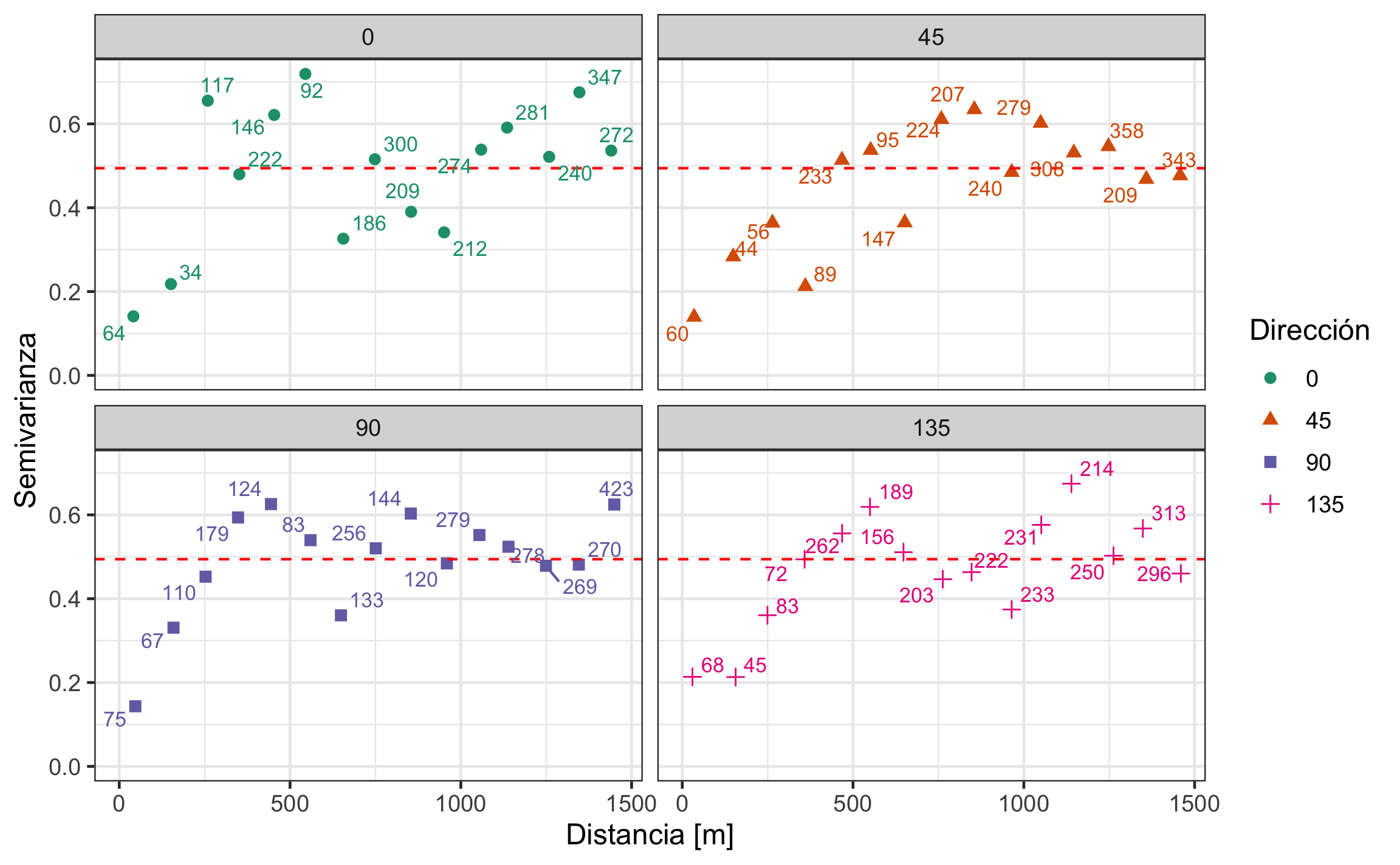
Figura 19.20: Variogramas direccionales cada 45°. La línea roja punteada representa la varianza de los datos, lo que se aproxima a la meseta total.
Tanto el mapa como los variogramas direccionales no muestran señas de anisotropía, por lo que el modelado se puede hacer con el variograma omnidireccional.
19.4.2.2 Ajuste de modelo de variograma
Lo primero que hay que hacer antes de ajustar un modelo al variograma experimental es estimar las partes del variograma (meseta, pepita, rango) y establecer valores iniciales, para posteriormente realizar el ajuste.
Los valores iniciales se estiman a partir del variograma experimenta, en este caso omnidireccional. Revisando la Figura 19.18, se puede estimar una pepita de aproximadamente 0.1, una meseta de 0.4, un rango de 500, y se puede usar un modelo tipo esférico (‘Sph’). Lo anterior se define en el siguiente bloque.
pep = .1 # pepita
meseta = .4 # meseta parcial
mod = "Sph" # modelo a ajustar (esferico)
rango = 500 # rangoLos modelos vienen ya definidos en gstat, por lo que simplemente hay que indicar cuál se quiere usar. Para ver los modelos disponibles se puede ejecutar la función show.vgms (Figura 19.21), que muestra una grilla de los diferentes modelos, donde el nombre del modelo se encuentra en comillas. Para los modelos expuestos anteriormente el nombre en gstat sería: ‘Sph’ para esférico, ‘Exp’ para exponencial, ‘Gau’ para gaussiano, y ‘Pot’ para potencia.
show.vgms()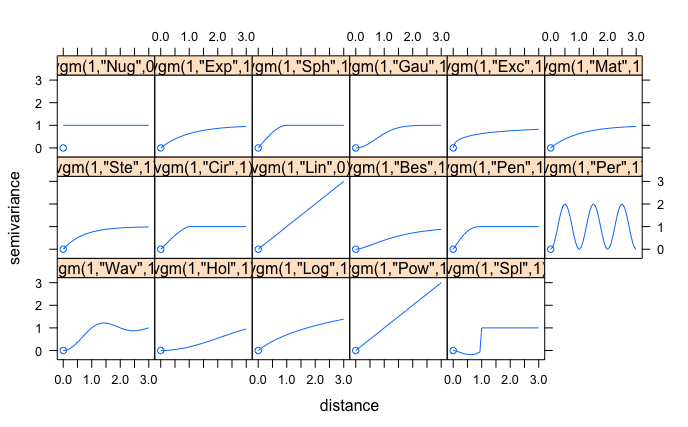
Figura 19.21: Modelos disponibles en gstat
Con estos valores iniciales se puede proceder al ajuste por medio de la función fit.variogram, que requiere el variograma experimental y el modelo que se define por medio de la función vgm. Se realiza un ajuste automático, brindando el modelo ajustado, y a su ve se puede calcular un error del ajuste inicial, pero el más confiable se obtiene con la validación cruzada.
dat.fit = fit.variogram(dat.vgm, model = vgm(meseta, mod, rango, pep))
fit.rmse = sqrt(attributes(dat.fit)$SSErr/(nrow(datos))) # error del ajuste
varmod = dat.fit # modelo ajustadofit.rmse## [1] 0.0006014446varmod## # A tibble: 2 x 9
## model psill range kappa ang1 ang2 ang3 anis1 anis2
## <fct> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 Nug 0.105 0 0 0 0 0 1 1
## 2 Sph 0.424 455. 0.5 0 0 0 1 1El ajuste sobre el variograma se puede visualizar en las Figuras 19.22 y 19.23, donde la primera muestra el ajuste sobre el variograma omnidireccional y la segunda sobre los variogramas direccionales.
plot(dat.vgm, dat.fit, xlab = x_var, ylab = y_var) # omnidireccional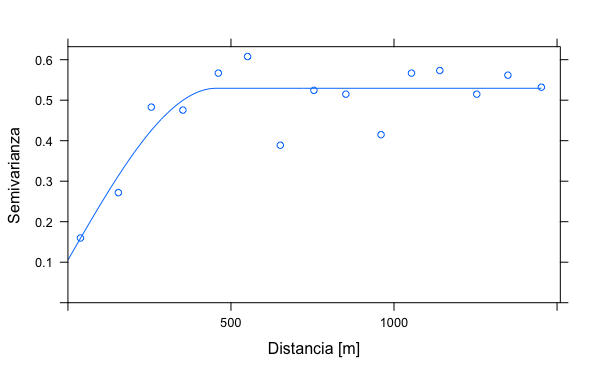
Figura 19.22: Variograma omnidireccional y modelo esférico ajustado.
plot(dat.vgm2, dat.fit, as.table = T, xlab = x_var, ylab = y_var) # direccionales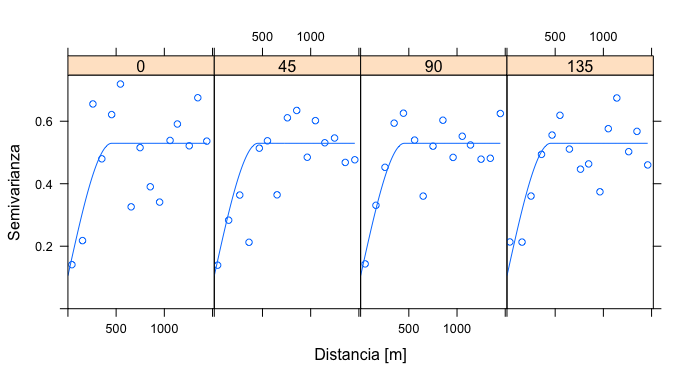
Figura 19.23: Variogramas direccionales y modelo esférico ajustado, mostrando que el modelo aplica para todas las direcciones.
19.4.2.3 Validación cruzada
La validación cruzada es una mejor estimación del error del ajuste del modelo, conforme a lo que se explicó en la sección de Conceptos de geoestadística. Se presenta aquí una descripción numérica de los residuales (error de ajuste), así como el error cuadrático medio (RMSE), la razón de desviación cuadrática media (MSDR), y la correlación entre los valores observados y predecidos. Para esta última lo que se busca es determinar qué tan similares son los valores.
La validación cruzada se realiza por medio de la función krige.cv, la cual requiere los argumentos de la fórmula, datos, y el modelo ajustado.
kcv.ok = krige.cv(as.formula(paste(myvar,'~1')),
locations = datos_sf, model = varmod)cl = .95
summary(kcv.ok$residual)## Min. 1st Qu. Median Mean 3rd Qu. Max.
## -1.465868 -0.313325 -0.028471 -0.002209 0.298852 1.732672xval.rmse = sqrt(mean(kcv.ok$residual^2)) # RMSE - menor es mejor
xval.msdr = mean(kcv.ok$residual^2/kcv.ok$var1.var) # MSDR - ~1 es mejor
xval.mod = lm(observed ~ var1.pred, as.data.frame(kcv.ok))
xval.r2 = xval.mod %>% broom::glance() %>% pull(r.squared)
correl = signif(CorCI(cor(kcv.ok$observed, kcv.ok$var1.pred), nrow(kcv.ok)),3)
metricas = tibble(metric = c('$RMSE$','$MSDR$','$r$','$R^2$'),
estimate = c(xval.rmse,xval.msdr,correl[1],xval.r2))
CIbeta = signif(broom::tidy(xval.mod, conf.int=T)[2,c(2,6,7)],4)
CIbeta## # A tibble: 1 x 3
## estimate conf.low conf.high
## <dbl> <dbl> <dbl>
## 1 0.957 0.809 1.10| Métrica | Valor |
|---|---|
| \(RMSE\) | 0.549 |
| \(MSDR\) | 1.003 |
| \(r\) | 0.623 |
| \(R^2\) | 0.388 |
Las métricas por si solas no dicen mucho, son más útiles cuando se comparan modelos, pero en general se puede decir que presentan valores aceptables (Tabla 19.1), la MSDR está muy cerca de 1, la correlación es alta (.623), y el RMSE es menor a la desviación de los datos (0.703). De forma ideal se debieran ajustar varios modelos, realizar la validación cruzada y escoger el que muestra mejor desempeño.
ggplot(as.data.frame(kcv.ok), aes(var1.pred, observed)) +
geom_point(col = "blue", shape = 1, size = 1.25) +
coord_fixed() +
geom_abline(slope = 1, col = "red", size = 1) +
geom_smooth(se = F, method = 'lm', col = 'green', size = 1.25) +
labs(x = "Predecidos", y = "Observados")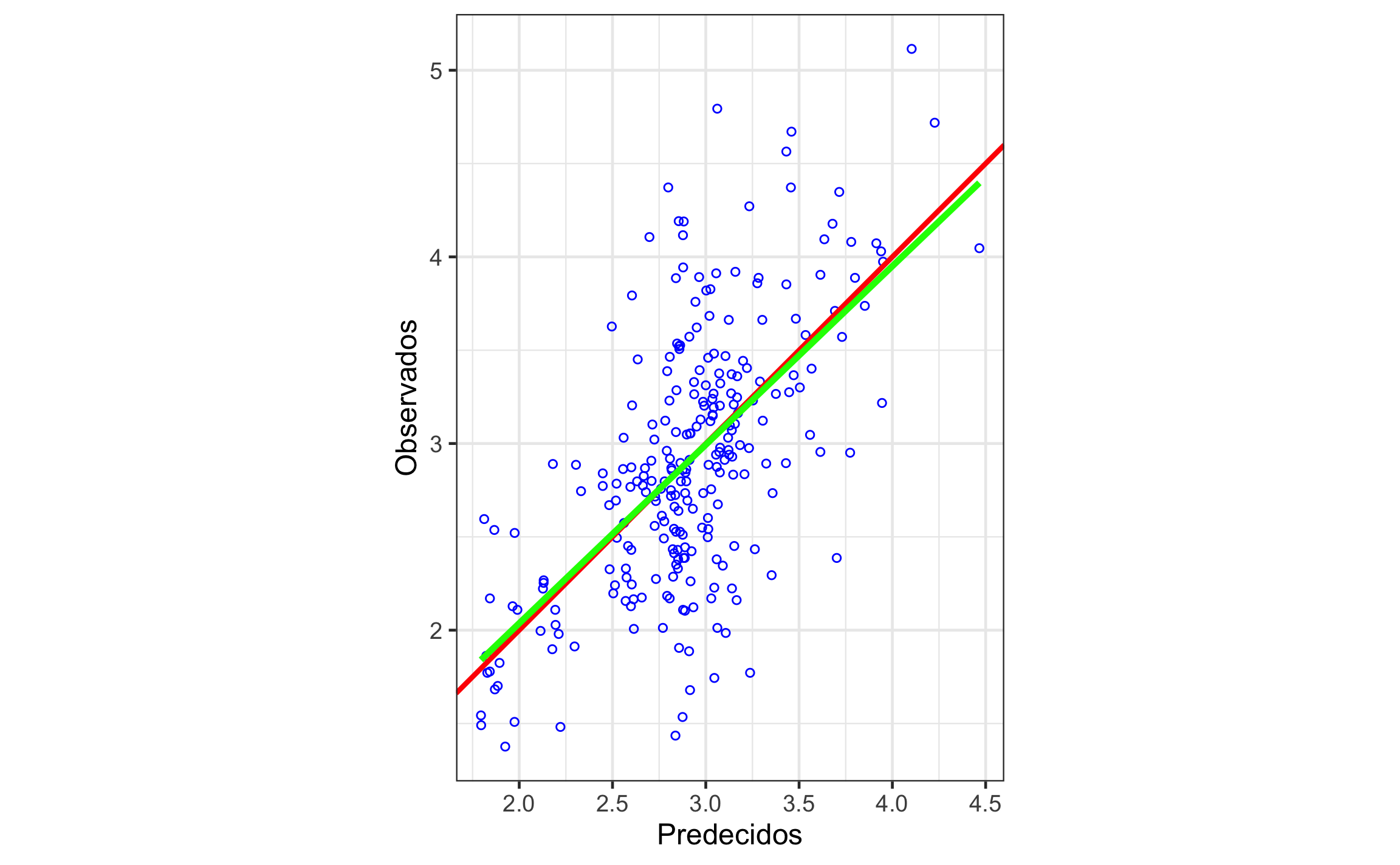
Figura 19.24: Relación entre los valores observados y predecidos por la validación cruzada. La línea roja es la línea 1:1 y la línea verde es la regresión entre los datos.
ggplot(as.data.frame(kcv.ok), aes(residual)) +
geom_histogram(bins = 15, col = 'black', fill = "blue") +
labs(x = "Residuales", y = "Frecuencia") +
geom_vline(xintercept = mean(kcv.ok$residual), col = 'red')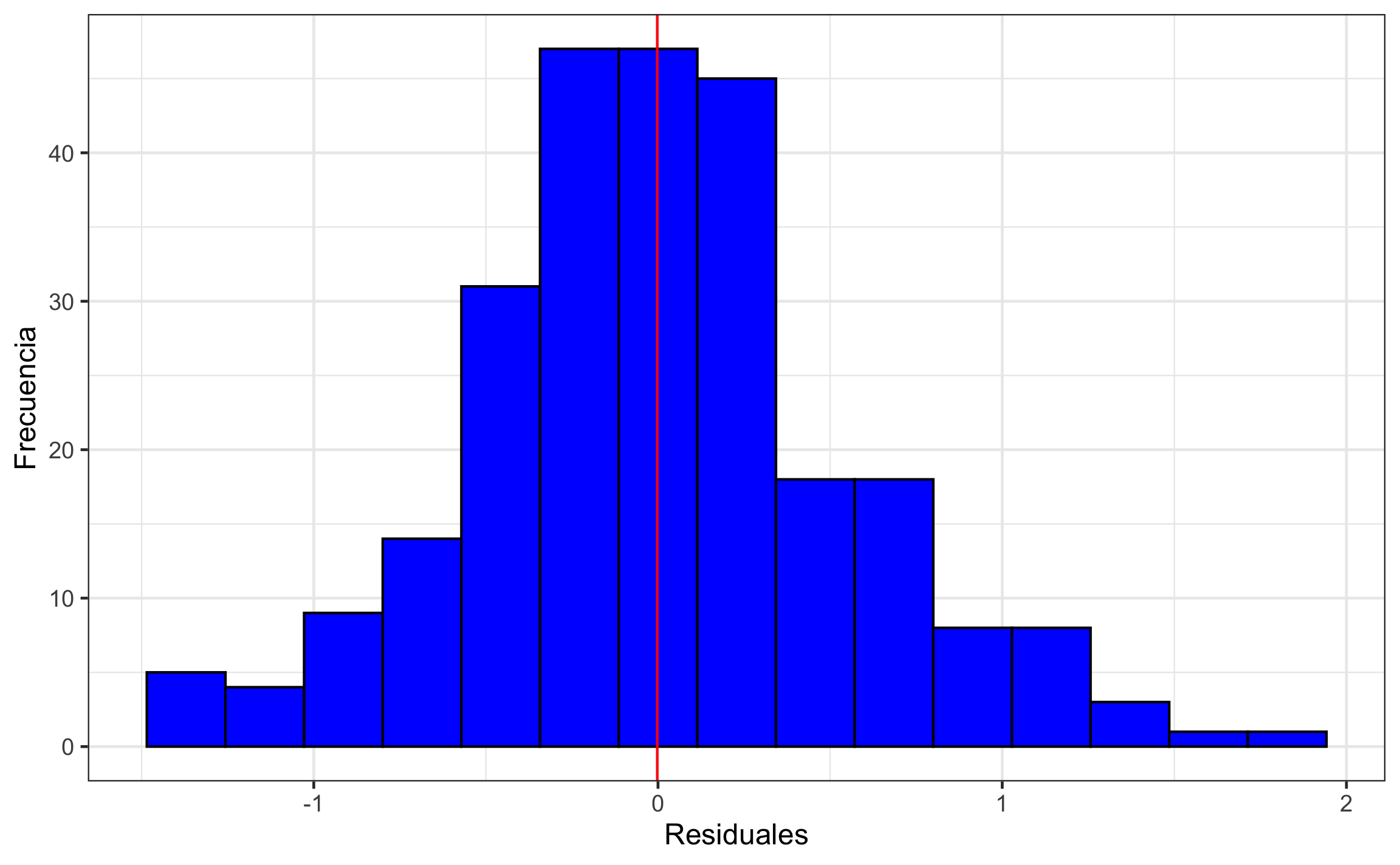
Figura 19.25: Histograma de los residuales, donde lo que se busca es que esten centrados alrededor de 0 y sigan una distribución aproximadamente normal.
Los valores predecidos y los observados muestran buena correlación (r = .623, 95% IC [.542, .692]). La pendiente de la relación entre los valores predecidos y los observados es de 0.9569, 95% IC [0.8092, 1.105]. El histograma de los residuales se observa simétrico y centrado en cero (0). Lo anterior indica un modelo apropiado.
19.4.3 Interpolación (Kriging)
Una vez se ha calculado el variograma, se le ajusta un modelo, y se valida el modelo se puede proceder a la interpolación mediante Kriging. Hay que recalcar que la interpolación como tal es el último paso de todo el proceso, y si no se ejecutan con cuidado los pasos anteriores el resultado que se obtiene puede no tener validez o sentido.
La función general para realizar la interpolación por Kriging es krige, la cual requiere la fórmula, los datos, la grilla a interpolar, y el modelo ajustado al variograma experimental. Esta función resulta en objeto stars, ya que es el formato de la grilla a interpolar, con dos atributos o columnas: los valores predecidos (estimados) en var1.pred y la varianza de la predicción (estimación) en var1.var.
Para el caso de trabajar con datos log-transformados, y como se mencionó en la sección de los tipos de Kriging, no es tan directo como aplicar la transformación inversa para obtener la interpolación en la escala original de los datos. La función krigeTg es capaz de realizar esta transformación inversa de la forma adecuada. La diferencia entre krigeTg y krige es que krigeTg ocupa que la fórmula contenga a la variable SIN transformar (por ejemplo: Cu ~ 1, en vez de logCu ~ 1), y definir el parámetro lambda que para la transformación logarítmica equivale a 0. El objeto resultante va a tener los mismos atributos a los de la función krige y otros más, donde var1TG.pred y var1TG.var corresponde, respectivamente, con las predicciones y varianzas en la escala original de los datos.
ok = krige(as.formula(paste(myvar,'~1')),
locations = datos_sp,
newdata = datosint2,
model = varmod)
okBT = krigeTg(formula = as.formula(paste(str_remove(myvar,'log'),'~1')),
locations = datos_sp,
newdata = datosint,
model = varmod,
lambda = 0)Los mapas de predicción (estimación) y de varianza (error de estimación) se presentan en las Figuras 19.26 y 19.27. Como el objeto a usar es del tipo stars, el paquete stars trae una geometría (geom_stars) para visualizar los datos usando ggplot2, a como se muestra en los siguientes dos bloques para visualizar los atributos respectivos, donde el argumento más importante es el aes(fill) donde se define el atributo a visualizar.
p1 = ggplot() +
geom_stars(data = ok, aes(fill = var1.pred, x = x, y = y)) +
scale_fill_gradientn(colours = viridis(10), na.value = NA) +
coord_sf() +
labs(x = x_map, y = y_map,
title = 'Predicción',
fill = myvar)
p1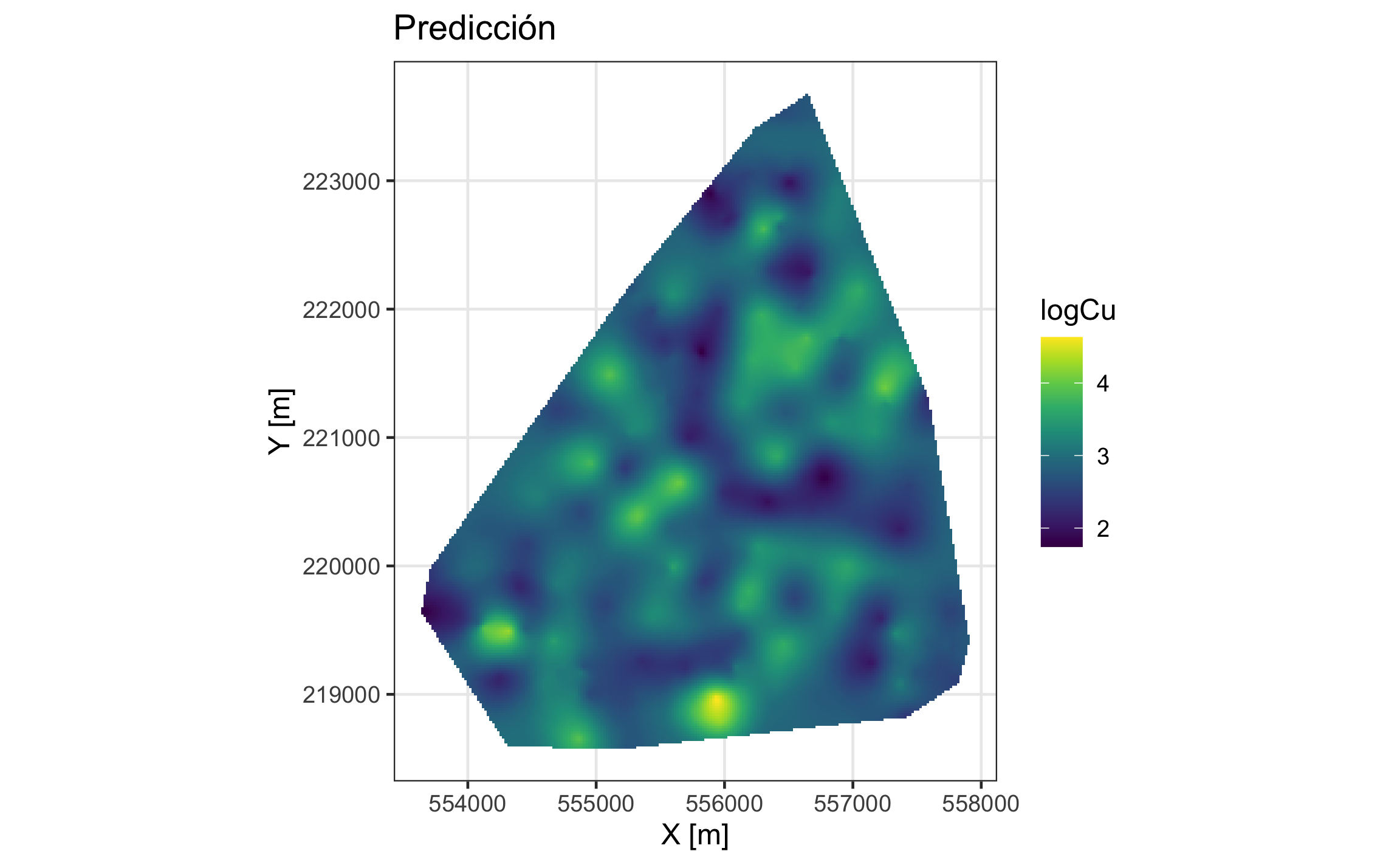
Figura 19.26: Mapa de predicción para el logaritmo de Cu.
p2 = ggplot() +
geom_stars(data = ok, aes(fill = var1.var, x = x, y = y)) +
scale_fill_gradientn(colours = brewer.pal(9,'RdPu'), na.value = NA) +
coord_sf() +
labs(x = x_map, y = y_map,
title = 'Varianza',
fill = myvar)
p2
Figura 19.27: Mapa de varianza (error) para el logaritmo de Cu.
Este capítulo brinda una introducción básica a geoestadística, presentando los conceptos más importantes, los tipos de Kriging que hay, y se demuestra lo presentado con un ejemplo (usando Kriging Lognormal, Kriging Ordinario en datos log-transformados) que representa el caso más típico y común (tal vez a excepción de la transformación logarítmica) en cómo se realiza un análisis geoestadístico de principio a fin. Para más información, detalle, y ejemplos se remite al lector a consultar las referencias sugeridas.
Referencias
Borradaile, G. J. (2003). Statistics of Earth Science Data: Their Distribution in Time, Space and Orientation. Springer-Verlag Berlin Heidelberg.
Chilès, J.-P., & Delfiner, P. (1999). Geostatistics: Modeling Spatial Uncertainty (2.ª ed.). John Wiley & Sons.
Cressie, N. A. C. (1993). Statistics for Spatial Data. John Wiley & Sons.
Davis, J. C. (2002). Statistics and Data Analysis in Geology (3.ª ed.). John Wiley & Sons.
Goovaerts, P. (1997). Geostatistics for Natural Resources Evaluation. Oxford University Press.
Hijmans, R. J. (2020a). raster: Geographic Data Analysis and Modeling. https://CRAN.R-project.org/package=raster
Isaaks, E. H., & Srivastava, R. M. (1989). Applied Geostatistics. Oxford University Press.
McKillup, S., & Darby Dyar, M. (2010). Geostatistics Explained: An Introductory Guide for Earth Scientists. Cambridge University Press. www.cambridge.org/9780521763226
Nowosad, J. (2019). Geostatystyka w R. https://bookdown.org/nowosad/Geostatystyka/
Pebesma, E. (2020a). sf: Simple Features for R. https://CRAN.R-project.org/package=sf
Pebesma, E. (2020b). stars: Spatiotemporal Arrays, Raster and Vector Data Cubes. https://CRAN.R-project.org/package=stars
Pebesma, E., & Bivand, R. (2020a). Spatial Data Science. https://keen-swartz-3146c4.netlify.app
Pebesma, E., & Graeler, B. (2020). gstat: Spatial and Spatio-Temporal Geostatistical Modelling, Prediction and Simulation. https://CRAN.R-project.org/package=gstat
Sarma, D. D. (2009). Geostatistics with Application in Earth Sciences (2.ª ed.). Springer.
Swan, A., & Sandilands, M. (1995). Introduction to Geological Data Analysis. Blackwell Science.
Trauth, M. (2015). MATLAB® Recipes for Earth Sciences (4.ª ed.). Springer-Verlag Berlin Heidelberg.
Wackernagel, H. (2003). Multivariate Geostatistics (3.ª ed.). Springer-Verlag Berlin Heidelberg.
Webster, R., & Oliver, M. A. (2007). Geostatistics for Environmental Scientists (2.ª ed.). John Wiley & Sons.