Capítulo 8 Introducción a estadística
8.1 Introducción
Este capitulo da una introducción a estadística, en qué consiste, para qué se usa, los tipos, modelos y nomenclatura que se usan.
Estadística es la ciencia que estudia la manera en que se recolecta, se analiza, se interpreta la información proveniente de una población, así como el modo en que se extrapola esos resultados a otros casos similares. Tiene como objetivo principal analizar datos y transformarlos en información útil para tomar decisiones y sacar conclusiones, donde hay incertidumbre y variación.
8.2 Tipos
En general hay dos tipos de estadística:
- Descriptiva: Lo que se hace es recopilar, organizar, resumir y presentar datos para facilitar su análisis y aplicación (Tablas y/o gráficos). En este tipo es donde se ubica lo que se conoce como análisis exploratorio de datos (AED o EDA en inglés), y consiste en el proceso para utilizar herramientas estadísticas (como gráficas, medidas de tendencia central y medidas de variación), con la finalidad de investigar conjuntos de datos para comprender sus características importantes. Un ejemplo se observa en la Figura 8.1.
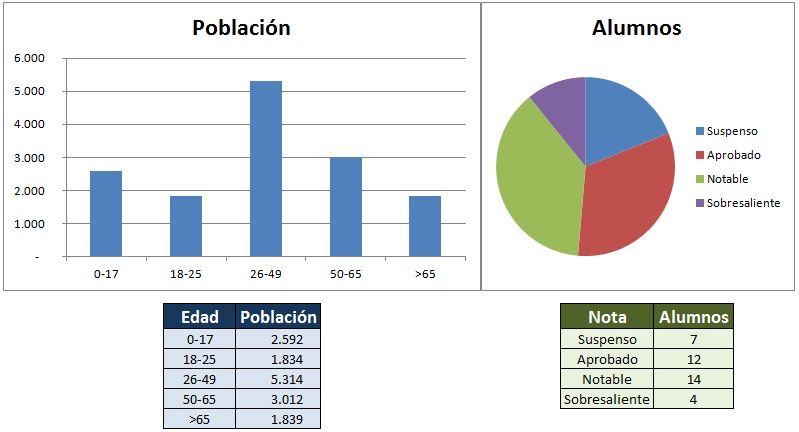
Figura 8.1: Ejemplo de estadística desciptiva y análisis exploratorio de datos. Tomado de: http://www.universoformulas.com/imagenes/estadistica/descriptiva/estadistica-descriptiva.jpg
{kind=link}
- Inferencial: El objetivo es hacer inferencias en base a una muestra, con la intención de generalizar a una población de interés (Figura 8.2). En este caso los resultados se usan para corroborar o refutar creencias sobre la población de interés y sacar conclusiones con sustento estadístico.
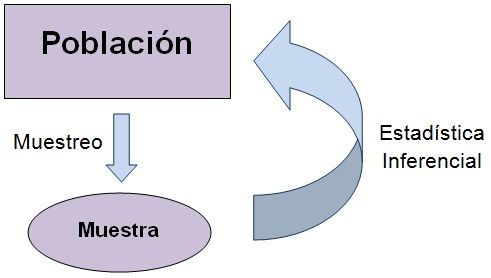
Figura 8.2: Proceso de estadística inferencial. Tomado de: http://www.universoformulas.com/imagenes/estadistica/inferencia/proceso-estadistica-inferencial.jpg
{kind=link}
8.3 Modelos
Determinístico: Donde las mismas entradas producirán las mismas salidas, sin variación, esto debido a que no hay incertidumbre en los datos, se conocen con certeza.
Probabilístico (aleatorio, estocástico): Donde los resultados (salidas) dependen de las entradas y de los componentes aleatorios (incertidumbre), pudiendo producir resultados distintos a partir de una misma entrada. Los resultados se expresan en términos de probabilidad, que refleja la incertidumbre del modelo.
8.4 Nomenclatura
En estadística se maneja cierta nomenclatura (definiciones) que es importante conocer y saber usar apropiadamente. Dentro de las definiciones que se van a trabajar a los largo del curso son:
- Población
- Conjunto con alguna característica de interés
- Normalmente muy grande para poder abarcarlo (estudiarlo) por completo
- Muestra
- Subconjunto de la población de interés sobre el cual se hacen las observaciones y análisis
- Debería ser representativa
- Variable
- Característica observable de los componentes de una población (muestra) y que puede tomar distintos valores
- Observación o dato
- Valor obtenido para los componentes de la muestra, como resultado de algún tipo de medición
Los conceptos de población y muestra se muestran en la siguiente figura.
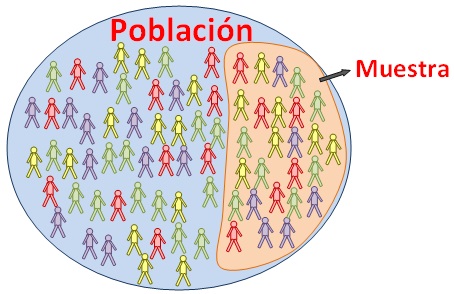
Figura 8.3: Ejemplo de una población a la cual se le toma una muestra. Tomado de: http://aprendiendoadministracion.com/wp-content/uploads/2016/01/muestra-estadistica.jpg
{kind=link}
8.5 Variables
Hay dos tipos generales de variables: Cualitativa y Cuantitativa. Esto es presentado por Triola (2004), así como la subdivisión de dichos tipos de variables, presenta a continuación.
8.5.1 Cualitativa
Lo que se conoce como datos categóricos, donde las entradas o datos toman valores de clases o niveles. Dentro de R estas son las que so codifican como factores. Dentro de este tipo podemos encontrar una subdivisión:
- Nominal (nom): donde las clases o niveles no tienen un orden específico,
- Ordinal (ord): donde las clases o niveles tienen un orden relativo, que se puede pensar como una escala.
Ejemplos de datos cualitativos son: color (nom), grado de meteorización (ord), nivel de fisuramiento (ord), intensidad (ord), escala de dureza de Mohs (ord), etc.
8.5.2 Cuantitativa
Corresponden con datos numéricos, es el tipo de dato que por lo general se asocia a técnicas estadísticas y de análisis de datos, pero no se deben obviar los datos cualitativos.
Se puede dividir en:
- Intervalo: donde datos los datos se encuentran igualmente espaciados y no hay un cero absoluto, o sea pueden haber valores negativos,
- Razón: donde hay un cero absoluto, correspondiendo con valores positivos.
También se puede dividir en:
- Discretos (disc): por medio de conteos, corresponde con números enteros,
- Continuos (cont): por medio de mediciones (magnitudes), corresponde con infinitos valores entre enteros, puede expresarse con decimales.
Ejemplos de datos cuantitativos son: edad (cont), orientación (cont), espesor (cont), número de fisuras (disc), magnitud (cont), esfuerzos (cont), deformaciones (cont), longitud (cont), superficie (cont), volumen (cont), tiempo (cont), temperatura (cont), etc.
En las ciencias geológicas y de la tierra se manejan varios tipos de datos especiales, que van a requerir de adaptar técnicas de análisis generales para los casos específicos. Dentro de estos datos se tiene:
- Cerrados: Las variables son expresadas como proporciones y suman hasta un valor fijo total (Ej: 100%), en general el interés es más en la razón entre las variables y no el valor de la variable. Composiciones (Ej: tipo de roca) representan la mayoría de este tipo de datos.
- Espaciales: La(s) variable(e) de interés posee(n) componentes en 2D o 3D representando su distribución espacial (ubicación en un área determinada). Ejemplos: distribución de un tipo de fósil, cambios en el espesor de una capa de arenisca, distribución de trazas en el agua subterránea.
- Direccionales: Los datos son expresados en ángulos/orientaciones entre 0 y 360 y pueden tener ademas una inclinación. Ejemplos: rumbo o buzamiento de una capa, orientación de fósiles elongados, dirección del flujo de una colada de lava.
Una representación gráfica de los tipos de datos se observa en la Figura 8.4.
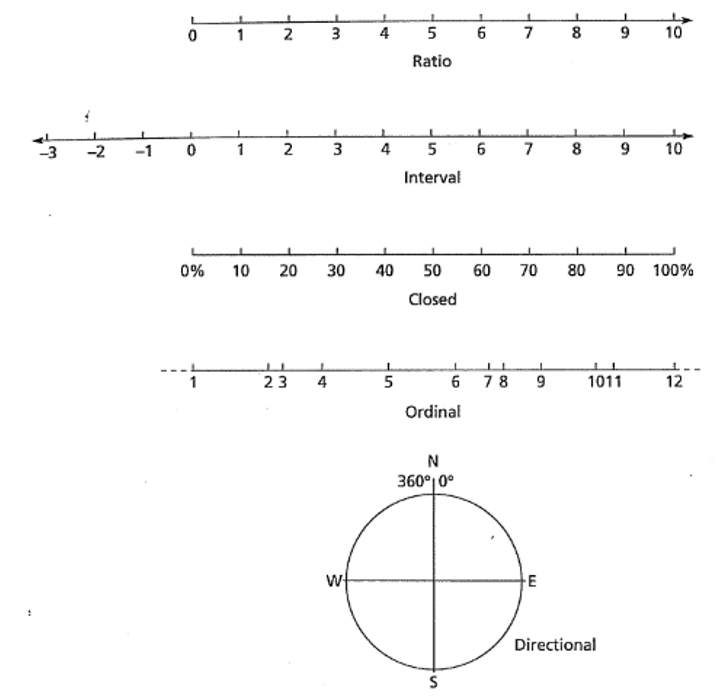
Figura 8.4: Representación gráfica de los tipos de datos. Los datos cerrados (closed) y direccionales (directional) son más típicos de la ciencias geológicas (Swan & Sandilands, 1995).
8.6 Métodos de análisis
Existen diferentes métodos de análisis de datos. Éstos van a depender del tipo de dato y la cantidad de variables que se tengan. Dentro de las principales metodologías se tienen y una representación gráfica de las variable de interés se presenta en la Figura 8.5:
- Univariable: Se analiza cada variable por separado, el interés está en enfocarse en una variable por si sola a la vez y sin considerar la relación que pueda tener con otras.
- Bivariable: Se analizan dos variables en conjunto, enfocándose en su relación y/o dependencia. Es la versión simple de un análisis multivariable.
- Multivariable: Cuando el análisis involucra 2 o más variable de interés a la vez y se requiere determinar la relación e interacción entre dichas variables.
- Secuencias: Cuando los datos se presentan como secuencias (por lo general implicando algún patrón o ciclicidad) en el tiempo/espacio, donde la forma más simple es un análisis bivariable donde una de las variables es el tiempo/espacio.
- Espacial: Cuando la ubicación de las muestras es de interés y se requiere entender o determinar cómo se dispone una variable en un área determinada. Por lo general tres (o cuatro) variables analizadas a la vez, donde dos (o tres) corresponden con la ubicación espacial y la otra corresponde con alguna medida de interés geológico, existen opciones univariables y multivariables.
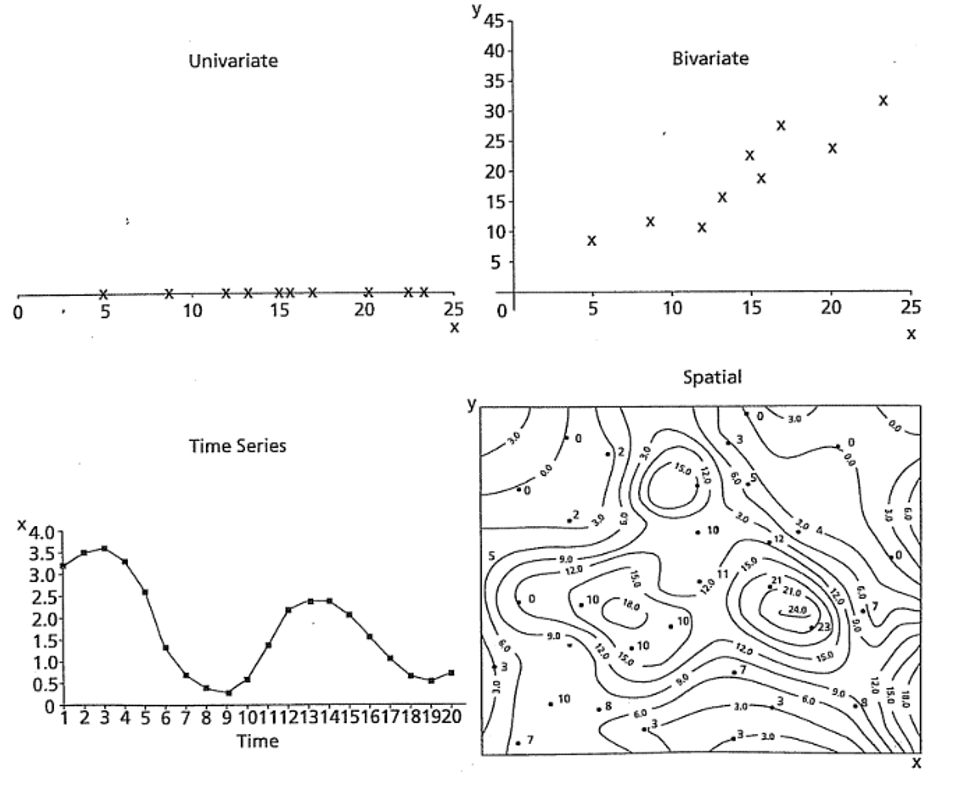
Figura 8.5: Representación gráfica de las variables correspondientes a diferentes metodologías de análisis de datos (Swan & Sandilands, 1995).
8.7 Muestreo
El muestreo es un procedimiento para obtener datos/observaciones de una población, con la finalidad de usar esta información para realizar inferencias acerca de dicha población (Davis, 2002). Las muestras son subconjuntos de los datos. El conjunto de todas las muestras que se pueden obtener de la población se denomina espacio muestral. La(s) muestra(s) debe(n) ser representativa(s), donde esto va a depender de la adecuada implementación de alguna de las técnicas de muestreo presentadas más adelante.
En la Figura 8.6 se presenta y retoma la el concepto de muestra geológica, donde la población de interés es un afloramiento especifico, pero dicho afloramiento es demasiado grande para muestrear por completo, por lo que se deben tomar varias observaciones (muestras geológicas) para obtener una muestra que representa a la población meta.
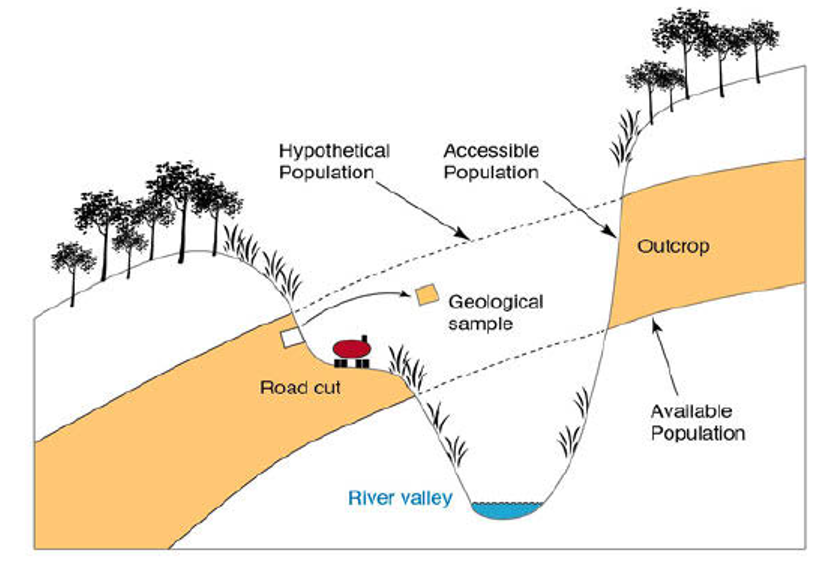
Figura 8.6: Representación de una población de interés geológico donde es necesaria la toma de observaciones (muestras geológicas) para obtener una muestra representativa de dicha población (Trauth, 2015).
8.7.1 Tipos
Se presentan los tipos o técnicas de muestreo más comunes y que permiten obtener una muestra representativa de la población, descritos en más detalle en Triola (2004).
8.7.1.1 Aleatorio Simple
Una muestra se selecciona de modo que todos los elementos de la población tengan la misma probabilidad de ser elegidos. En general es poco recomendado cuando la población es muy grande o heterogénea (Figura 8.7).
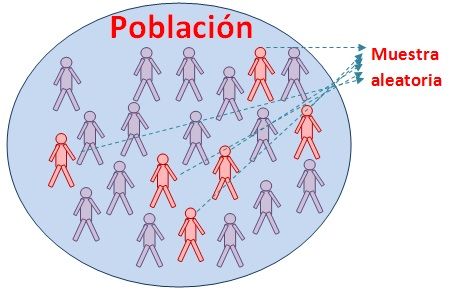
Figura 8.7: Representación de un muestreo aleatorio simple. Tomado de: http://www.universoformulas.com/imagenes/estadistica/inferencia/muestreo-probabilistico.jpg
{kind=link}
8.7.1.2 Sistemático
Se elige un punto de partida y luego seleccionamos cada k-ésimo (por ejemplo cada quincuagésimo) elemento en la población. Conlleva algunos riesgos cuando el marco muestral es repetitivo o de naturaleza cíclica (Figura 8.8).

Figura 8.8: Representación de un muestreo sistematico. Tomado de: http://www.universoformulas.com/imagenes/estadistica/inferencia/muestreo-sistematico.jpg
{kind=link}
8.7.1.3 Estratificado
Consiste en definir previamente los estratos (grupos) que posee una población a partir de características comunes entre sus elementos y distintas con los elementos de los otros estratos. A partir de eso se deben tomar muestras aleatorias en cada estrato (Figura 8.9).
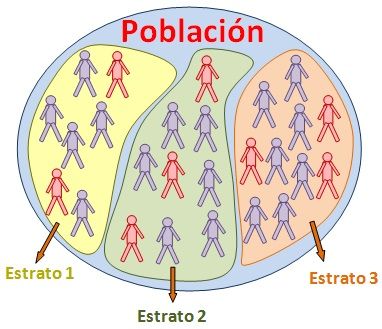
Figura 8.9: Representación de un muestreo estratificado. Tomado de: http://www.universoformulas.com/imagenes/estadistica/inferencia/muestreo-estratificado.jpg
{kind=link}
8.7.1.4 Bloques (conglomerados)
Cuando la población está agrupada en conglomerados naturales, después se seleccionan aleatoriamente algunos de estos conglomerados, y luego se elige a todos los miembros de los conglomerados seleccionados o se muestrean los conglomerados con alguna otra técnica. Se usa cuando los conglomerados son muy heterogéneos y no existen muchas diferencias entre conglomerados (Figura 8.10).
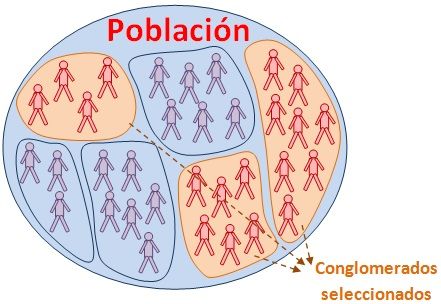
Figura 8.10: Representación de un muestreo en bloques o por conglomerados. Tomado de: http://www.universoformulas.com/imagenes/estadistica/inferencia/muestreo-estratificado.jpg
En geología muchas veces nos vemos forzados por disposición de afloramientos (clustered) o accesibilidad (traverse – cortes de carretera, ríos, etc), especialmente en climas tropicales, ver Figura 8.11, siendo estas las localidades donde se encuentra disponible la población a estudiar. Idealmente un muestreo exhaustivo y de alta resolución seria el que se define en grilla (regular).
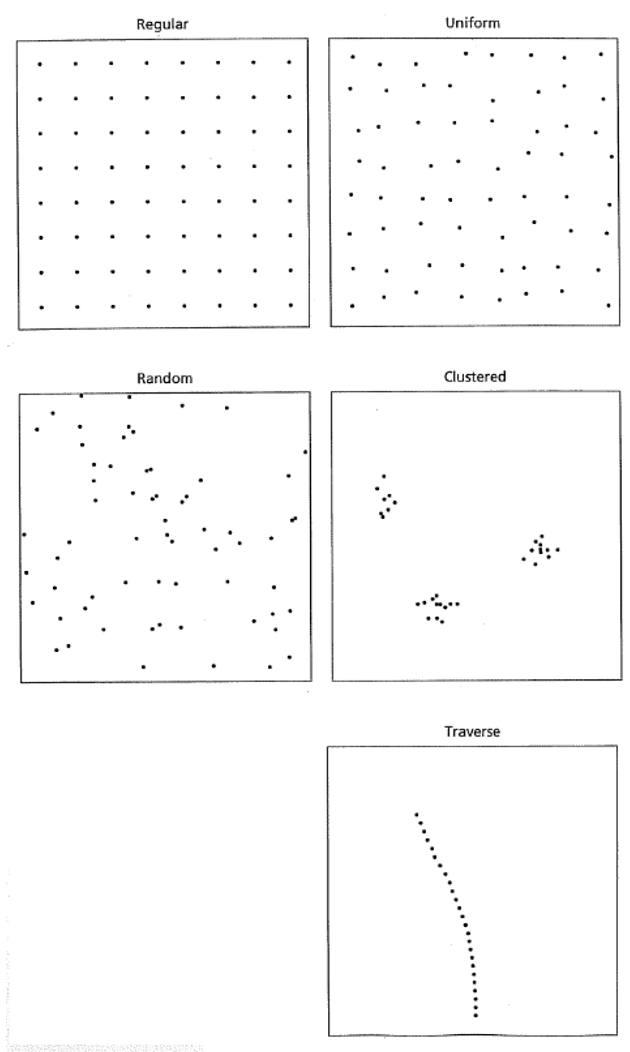
Figura 8.11: Típicas disposiciones de afloramientos en ciencias geológicas, especialmente en climas tropicales (Swan & Sandilands, 1995).
8.8 Incertidumbre
Además de los retos de recolectar muestras representativas, las mediciones geológicas tienen incertidumbre. No es posible realizar una medición exacta (que siempre es la misma) y equipos de alta precisión aún van a tener incertidumbre, reducida pero existe. El objetivo durante la recolección de muestras es reducir la incertidumbre a la hora de tomar mediciones, haciéndolas más precisas y exactas.
Con lo anterior se puede diferenciar entre error reproducible y sistemático. El error reproducible es donde se tienen diferencias entre mediciones repetidas y se asocia con precisión, donde se puede detectar por medio de la dispersión de los datos, a menor dispersión mayor precisión. El error sistemático es más difícil de detectar, no se puede estimar únicamente a partir de mediciones repetidas, a menos que se tenga un valor de referencia (valor verdadero); se asocia con exactitud, donde mientras más cerca del valor de referencia mayor la exactitud. Estos conceptos se pueden visualizar en la Figura 8.12.
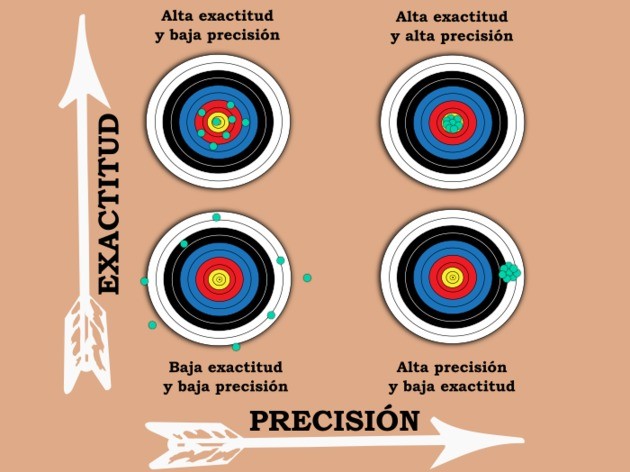
Figura 8.12: Diferencia entre precisión y exactitud. Tomado de: https://www.diferenciador.com/diferencia-entre-exactitud-y-precision/
Referencias
Davis, J. C. (2002). Statistics and Data Analysis in Geology (3.ª ed.). John Wiley & Sons.
Swan, A., & Sandilands, M. (1995). Introduction to Geological Data Analysis. Blackwell Science.
Trauth, M. (2015). MATLAB® Recipes for Earth Sciences (4.ª ed.). Springer-Verlag Berlin Heidelberg.
Triola, M. F. (2004). Probabilidad y Estadística (9.ª ed.). Pearson Educación.