Capítulo 16 Estadística No Paramétrica
16.1 Introducción
En el capítulo anterior (Pruebas Estadísticas) se introdujeron las pruebas estadísticas paramétricas más comunes, donde la suposición principal era que la(s) variable(s) de interés se encuentra(s) aproximadamente normalmente distribuida(s). Esta suposición aplica más que todo cuando la(s) variable(s) es(son) cuantitativa(s) continua(s) y se tiene una muestra relativamente grande. En los casos donde la(s) variable(s) de interés es(son) nominal u ordinal, o no cumple(n) con otras suposiciones de las pruebas o técnicas de análisis, es más apropiado utilizar pruebas o técnicas no paramétricas. Se recomienda revisar los apéndices para saber cómo reportar estadísticas y resultados de pruebas estadísticas, y para tener una guía de cuál prueba escoger.
Al igual que para las pruebas paramétricas, en los casos que corresponda se presentará el tamaño del efecto respectivo. Para algunas de las pruebas no paramétricas la metodología consiste en transformar los datos continuos a datos ordinales y realizar la prueba sobre estos datos transformados. Los pasos mencionados por Nolan & Heinzen (2014) se pueden aplicar también para estas pruebas.
De manera general lo expuesto en este capítulo se basa en Tomczak & Tomczak (2014), Fritz et al. (2012), Nolan & Heinzen (2014), Borradaile (2003), Walpole et al. (2012), McKillup & Darby Dyar (2010), Field et al. (2012) y Sheskin (2011).
16.2 Pruebas no-paramétricas
Estas pruebas se pueden dividir en dos grupos: para datos nominales (pruebas \(\chi^2\)) y para datos ordinales. Los datos nominales, típicamente presentados como conteos, corresponden con observaciones en categorías excluyentes, queriendo decir que cada observación pertenece a una sola categoría, y tener más observaciones de una categoría implica menos observaciones de la(s) otra(s). Estos datos se pueden presentar en tablas de contingencia (Tabla 16.1), donde se tabulan la cantidad de observaciones que pertenecen a cada una de las categorías.
| Clasto | 1 | 2 | 3 | 4 | Total |
|---|---|---|---|---|---|
| Cuarzo | 23 | 32 | 16 | 20 | 91 |
| Pedernal | 10 | 8 | 16 | 14 | 48 |
| Basalto | 17 | 10 | 18 | 16 | 61 |
| Total | 50 | 50 | 50 | 50 | 200 |
En este capítulo se presentan las siguientes pruebas:
- Prueba \(\chi^2\) de bondad de ajuste (16.4.1)
- \(H_0:\) Datos siguen la distribución/proporción esperada
- Prueba \(\chi^2\) de homogeneidad (16.4.2.1)
- \(H_0:\) Distribución homogénea entre las categorías de variables nominales
- Prueba \(\chi^2\) de independencia/asociación (16.4.2.2)
- \(H_0:\) No hay relación entre variables nominales o éstas son independientes entre si
- Prueba de rango con signo de Wilcoxon (16.5.1)
- \(H_0:\) La mediana es igual a un valor dado
- Prueba de la suma de rangos de Wilcoxon / Prueba U de Mann-Whitney (16.5.2)
- \(H_0:\) No hay diferencia entre las medianas de las dos muestras
- Prueba de Kruskal-Wallis (16.5.3)
- \(H_0:\) No hay diferencia entre las medianas de las muestras
- Correlación de Spearman (16.5.4)
- \(H_0: \rho_s = 0\) No hay relación/asociación entre las variables ordinales
- Bootstrap (remuestreo) (16.6)
- Técnica que permita hacer inferencias por medio de pruebas estadísticas o intervalos de confianza, especialmente útil para casos donde no hay una solución analítica
16.3 Tamaño del efecto
De manera similar a las pruebas paramétricas es importante además de presentar los resultados de pruebas de hipótesis, presentar tamaños de efecto para evaluar la significancia práctica del estudio. Para estas pruebas los tamaños del efecto corresponden principalmente con la familia \(r\), de asociación/relación entre variables, los cuales se presentan en la Tabla 16.2.
| Prueba | Tamaño de efecto |
|---|---|
| Correlación | \[\begin{equation} r_{s} = 1 - \frac{6\sum_i^N[R(x_i)-R(y_i)]^2}{N(N^2-1)} \tag{16.1} \end{equation}\] |
| Rango de 1 y 2 muestras | \[\begin{equation} r = \frac{Z}{\sqrt{N}} \tag{16.2} \end{equation}\] |
| Rango de 2+ muestras | \[\begin{equation} \eta_H^2 = \frac{H-k+1}{N-k} \tag{16.3} \end{equation}\] |
| Rango de 2+ muestras | \[\begin{equation} \epsilon^2 = \frac{H}{(N^2-1)/(N+1)} \tag{16.4} \end{equation}\] |
| \(\chi^2\) | \[\begin{equation} \phi = \sqrt{\frac{\chi^2}{N}} \tag{16.5} \end{equation}\] |
| \(\chi^2\) | \[\begin{equation} V = \sqrt{\frac{\chi^2}{N \cdot v_{min}}} \tag{16.6} \end{equation}\] |
| Notas: | |
| \(N\) = total de observaciones | |
| \(r_{s}\) = coeficiente de correlación de Spearman | |
| \(R(x_i)\) = Rangos de la variable x | |
| \(R(y_i)\) = Rangos de la variable y | |
| \(H\) = Estadístico de Kruskal-Wallis (\(\chi^2\)) | |
| \(k\) = Número de grupos | |
| \(v_{min}\) = grados de libertad mínimo de las filas o columnas de la tabla de contingencia |
El \(\phi\) y Cramer \(V\) comprenden el rango de 0 a 1 y se pueden interpretar similar a \(r\) y \(r_s\), donde valores cercanos a 0 indican poca o nula asociación y valores cerca de 1 indican alta asociación. El \(\phi\) aplica para tablas de \(2 \times 2\) (\(v=1\)) o vectores, mientras que Cramer \(V\) aplica para tablas de diferentes dimensiones (\(r \times c\), \(r = \text{rows/filas}\) y \(c = \text{columnas}\)) (Cohen, 1988; Fritz et al., 2012; Tomczak & Tomczak, 2014). Para clasificar el tamaño del efecto se pueden seguir las mismas guías que para \(r\) (.1, .3, .5). El \(\eta_H^2\) y \(\epsilon^2\) comprenden el rango de 0 a 1 y se interpreta igual a \(R^2\) y \(\eta^2\) presentados en los capítulos de Estadística Descriptiva Bivariable y Pruebas Estadísticas. Para el caso de Cramer \(V\), cuando el \(v_{min} > 1\), se deben ajustar los valores de las clases propuestas por medio de \(\frac{\text{valor}}{\sqrt{v_{min}}}\). Por ejemplo para el tamaño grande de \(.5\) y \(v_{min}=3\) se tendría \(\frac{.5}{\sqrt{3}}=.29\), con lo que ahora un tamaño de efecto grande sería cualquier valor mayor a \(.29\) en vez de \(.5\).
16.4 Pruebas \(\chi^2\) (nominales)
Para la prueba \(\chi^2\) el estadístico se calcula de acuerdo a la Ecuación (16.7), donde \(O_K\) es la frecuencia (conteo) observada y \(E_K\) es la frecuencia (conteo) esperada para la categoría \(K\). Esta prueba requiere que todas las frecuencias (conteos) esperados sean superiores a 5 y que se tengan por lo menos 50 observaciones. Esta prueba es siempre de una cola con la región de rechazo en la cola derecha.
\[\begin{equation} \chi^2 = \sum_{K=1}^K\frac{(O_K-E_K)^2}{E_K} \tag{16.7} \end{equation}\]
En caso de que se encuentre un resultado significativo (rechazar \(H_0\)), ya sea para la prueba de bondad de ajuste, de homogeneidad, o de independencia, es importante explicar dónde o cuáles categorías/celdas, del vector de categorías o combinaciones de categorías de la tabla de contingencia, se desvían de los valores esperados. Para ésto se pueden analizar los residuales ajustados (un tipo de análisis posterior - post-hoc), con lo que cuando un residual ajustado es superior a \(|1.96|\), para un \(\alpha=.05\), esta categoría/celda se considera se desvía significativamente de la hipótesis nula, mostrando dónde se dan estas diferencias entre los valores observados y esperados, pudiendo ayudar a explicar de manera más amplia los resultados.
16.4.1 Bondad de ajuste
Esta prueba se realiza cuando se tiene 1 variable de interés y dicha variable es nominal, y ésta puede tener \(2+\) categorías (\(K\)), y se quiere comparar el conteo de dichas categorías con unos valores esperados o predefinidos, de ahí el término “ajuste”, donde se refiere a qué tanto se “ajusta” o parece lo observado a lo esperado. De manera general la prueba \(\chi^2\) se ajusta a la cantidad de categorías que tenga la variable, pero existen pruebas exactas donde si la variable tiene 2 categorías es una prueba binomial y si tiene 3 o más es una prueba multinomial.
El estadístico se calcula conforme la Ecuación (16.7), donde los grados de libertad son el número de categorías menos uno (\(v=K-1\)).
16.4.1.1 Binomial
Para mostrar la prueba de bondad de ajuste binomial se usa el ejemplo de McKillup & Darby Dyar (2010), donde se tiene una muestra de 20 foraminíferos, clasificados en enrollados a la derecha (16) o a la izquierda (4), y se quiere comparar con las proporciones de .9 y .1 respectivamente. Asuma \(\alpha=.05\).
- Identificar la población, distribución, y la prueba apropiada:
- Población: foraminíferos enrollados a la derecha e izquierda
- Distribución: \(\chi^2\)
- Prueba: \(\chi^2\) de bondad de ajuste, ya que se tiene una variable nominal (dirección en que se enrollan), en este caso con 2 niveles (\(K=2\))
- Establecer las hipótesis nula y alterna:
- \(H_0:\) Los foraminíferos que se contaron siguen las proporciones propuestas (0.9 derecha, 0.1 izquierda)
- \(H_1:\) Los foraminíferos que se contaron siguen otras proporciones
- Determinar parámetros de la distribución a comparar (\(H_0\)):
- \(v = K-1 = 2 - 1 = 1\)
- Determinar valores críticos
- \(\alpha = .05\)
- \(\chi^2_{\alpha,v} = \chi_{.05,1}^2=3.84\)
- Calcular el estadístico de prueba
- Para un \(N=20\) la proporción de .9 equivale a 18 y la proporción de .1 equivale a 2, que serían las frecuencias esperadas (Con estos valores, especialmente el de 2, se estaría violando el supuesto de tener 5 o más frecuencias esperadas)
- \(\chi^2 = \sum_{K=1}^K\frac{(O_K-E_K)^2}{E_K}\)
- \(\chi^2 = \frac{(16-18)^2}{18} + \frac{(4-2)^2}{2} = 2.22\)
- Tomar una decisión
- El estadístico de prueba es menor al crítico, \(\chi^2 < \chi_{\alpha,v}^2\)
- El valor-p es mayor a \(\alpha = .05\), \(p = .136\)
- Decisión: No se rechaza \(H_0\)
En R existe la función chisq.test que realiza esta prueba, donde los argumentos principales son el vector de valores observados (variable nominal) y el vector de probabilidades para cada uno de los valores (categorías) de la variable observada.
a = 0.05
N = 20
chi.gof = chisq.test(c(16,4),p = c(.9,.1))
chi.gof##
## Chi-squared test for given probabilities
##
## data: c(16, 4)
## X-squared = 2.2222, df = 1, p-value = 0.136Como se está violando el supuesto de frecuencias esperadas mínimas (la prueba arroja una advertencia), se puede realizar la prueba exacta binomial (ya que \(K=2\)), que se demuestra aquí únicamente en R. Para ésto se usa la función binom.test, donde se requiere el valor observado para una de las categorías que se determina como el “éxito” (en este caso se escogió los enrollados a la derecha), el total de observaciones, la probabilidad de éxito (probabilidad de la categoría definida anteriormente), y el nivel de confianza.
binom.test(x = 16,n = N,p = 0.9,conf.level = 1-a)##
## Exact binomial test
##
## data: 16 and N
## number of successes = 16, number of trials = 20, p-value = 0.133
## alternative hypothesis: true probability of success is not equal to 0.9
## 95 percent confidence interval:
## 0.563386 0.942666
## sample estimates:
## probability of success
## 0.8Esta prueba arroja la probabilidad de éxito de acuerdo a los datos, el valor-p, y el intervalo de confianza, donde se compararía con la probabilidad definida para la categoría denominada como éxito.
El tamaño del efecto se calcula conforma la Ecuación (16.5).
\[\begin{equation} \phi = \sqrt{\frac{\chi^2}{N}} = \sqrt{\frac{2.22}{20}} = .33 \end{equation}\]
En R se puede calcular \(\phi\) con la función v.chi.sq del paquete MOTE (Buchanan et al., 2019), donde es necesario indicar el estadístico \(\chi^2\), el total de observaciones, el número de filas (para este caso es necesario usar 2 para que pueda funcionar), el número de columnas (categorías, \(K\)), y el nivel de significancia.
chi.gof.phi = v.chi.sq(x2 = chi.gof$statistic,
n = N,
r = 2,
c = 2,
a = a)
chi.gof.phi[1:3] %>% unlist()## v.X-squared vlow vhigh
## 0.3333333 0.2236068 0.8033405Conclusión: El conteo de foraminíferos enrollados a la derecha y a la izquierda no difiere de los valores esperados, \(\chi^2(1, N = 20) = 2.22\), \(p = .136\), \(V\) = .33, 95% IC [.22, .80]. El efecto se puede considerar mediano, pero con un rango amplio de pequeño hasta muy grande.
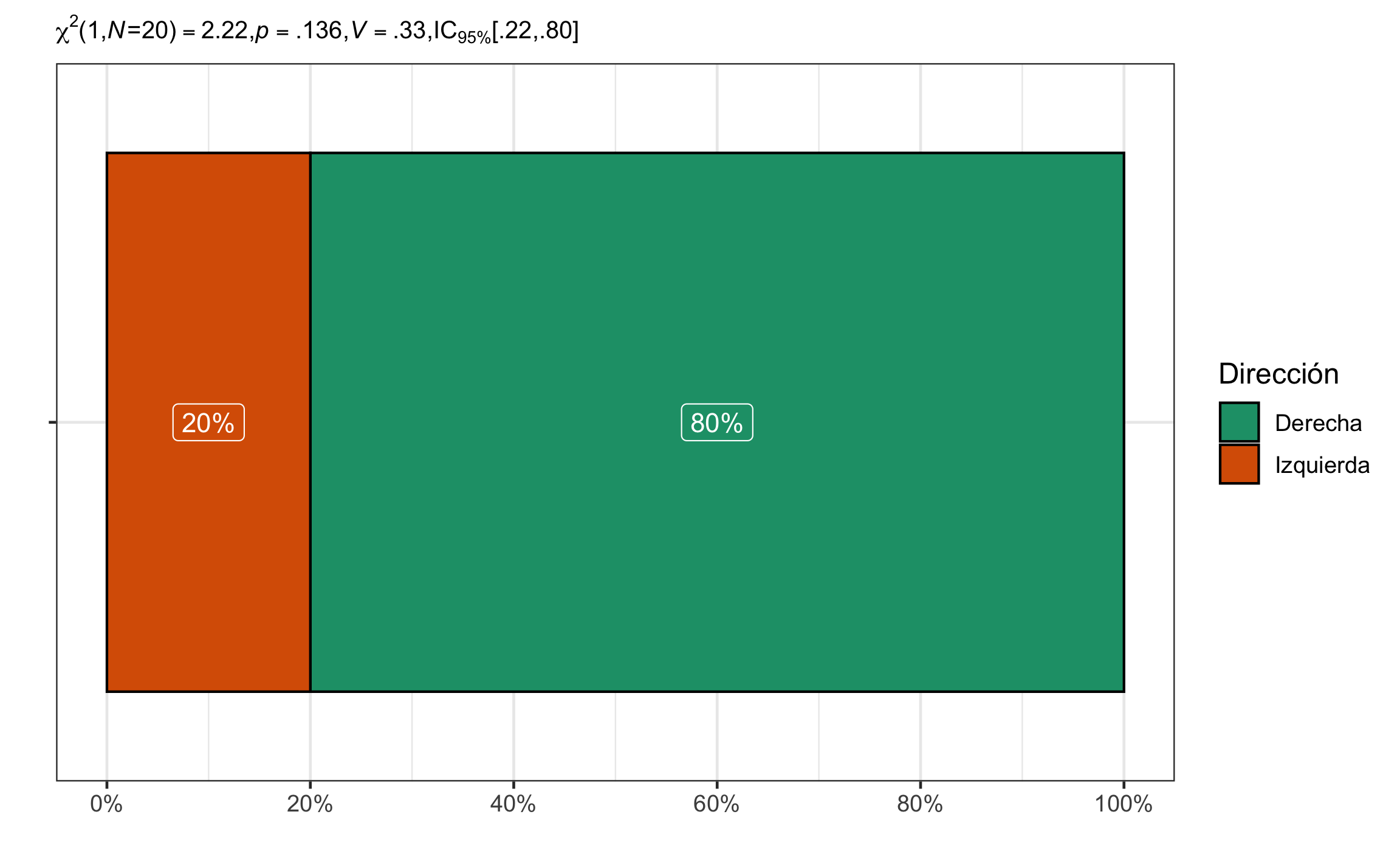
Figura 16.1: Gráfico de barra mostrando la proporción de la dirección de enroscamiento para los foraminíferos, así como el resumen estadístico respectivo.
16.4.1.2 Multinomial
Para mostrar la prueba de bondad de ajuste multinomial se usa el ejemplo de Borradaile (2003), donde se tiene el conteo de 98 minerales (cuarzo - 48, feldespato - 37, mica - 5, hornblenda - 2, magnetita - 6) en un sedimento proveniente de una roca fuente, y se quiere comparar con las proporciones de .384, .319, .156, .106, y .035 respectivamente. Asuma \(\alpha=.05\).
- Identificar la población, distribución, y la prueba apropiada:
- Población: minerales en sedimento de roca fuente
- Distribución: \(\chi^2\)
- Prueba: \(\chi^2\) de bondad de ajuste, ya que se tiene una variable nominal (conteo de granos), en este caso con 5 niveles (\(K=5\))
- Establecer las hipótesis nula y alterna:
- \(H_0:\) La distribución de minerales sigue las proporciones esperadas para la fuente
- \(H_1:\) La distribución de minerales no sigue las proporciones esperadas para la fuente
- Determinar parámetros de la distribución a comparar (\(H_0\)):
- \(v = K-1 = 5 - 1 = 4\)
- Determinar valores críticos
- \(\alpha = .05\)
- \(\chi^2_{\alpha,v} = \chi_{.05,4}^2=9.49\)
- Calcular el estadístico de prueba
- Para un \(N=98\) y de acuerdo a las proporciones, los conteos esperados equivalen a 37.5, 31.3, 15.3, 10.4, y 3.5 (Con estos valores, especialmente el de 3.5, se estaría violando el supuesto de tener 5 o más frecuencias esperadas)
- \(\chi^2 = \sum_{K=1}^K\frac{(O_K-E_K)^2}{E_K}\)
- \(\chi^2 = \frac{(48-37.5)^2}{37.5} + \frac{(37-31.3)^2}{31.3} + \frac{(5-15.3)^2}{15.3} + \frac{(2-10.4)^2}{10.4} + \frac{(6-3.5)^2}{3.5} = 19.54\)
- Tomar una decisión
- El estadístico de prueba es mayor al crítico, \(\chi^2 > \chi_{\alpha,v}^2\)
- El valor-p es menor a \(\alpha = .05\), \(p = .0006\)
- Decisión: Se rechaza \(H_0\)
En R existe la función chisq.test que realiza esta prueba, donde los argumentos principales son el vector de valores observados (variable nominal) y el vector de probabilidades para cada uno de los valores (categorías) de la variable observada.
minerales.nom = c('Cuarzo','Feldespato','Mica','Hornblenda','Magnetita')
a = 0.05
N = 98
observados = c(48,37,5,2,6)
esperados.p = c(.384, .319, .156, .106, .035)
chi.gof.mult = chisq.test(observados, p = esperados.p)
chi.gof.mult##
## Chi-squared test for given probabilities
##
## data: observados
## X-squared = 19.532, df = 4, p-value = 0.0006177Como se está violando el supuesto de frecuencias esperadas mínimas (la prueba arroja una advertencia), se puede realizar la prueba exacta multinomial (ya que \(K=5\)), que se demuestra aquí únicamente en R. Para ésto se usa la función xmulti del paquete XNomial, donde se requieren los vectores de valores observados y valores o proporciones esperadas, y definir el estadístico a usar.
xmulti(obs = observados, expr = esperados.p, statName = 'Chisq')##
## P value (Chisq) = 0.001098Esta prueba arroja el valor-p para la comparación entre las categorías.
Los residuales ajustados se pueden acceder a partir del objeto en que se guarda la prueba, como se muestra en el siguiente bloque. Estos residuales son los que realmente indican si hay una diferencia significativa entre lo observado y lo esperado (\(> |1.96|\) para \(\alpha=.05\)), que para el caso del ejemplo ocurre en las categorías cuarzo (\(O>E\)), mica (\(O<E\)), y hornblenda (\(O<E\)).
chi.gof.mult$stdres %>%
set_names(minerales.nom)## Cuarzo Feldespato Mica Hornblenda Magnetita
## 2.153406 1.243594 -2.864075 -2.752477 1.412610Estos valores se pueden visualizar mejor coloreados de acuerdo a si están por encima (azul) o debajo (rojo) del valor crítico de acuerdo al nivel de significancia \(\alpha\).
| Mineral | stdres |
|---|---|
| Cuarzo | 2.15 |
| Feldespato | 1.24 |
| Mica | -2.86 |
| Hornblenda | -2.75 |
| Magnetita | 1.41 |
La diferencia entre valores observados y esperados se puede visualizar a como se presenta en la Figura 16.2
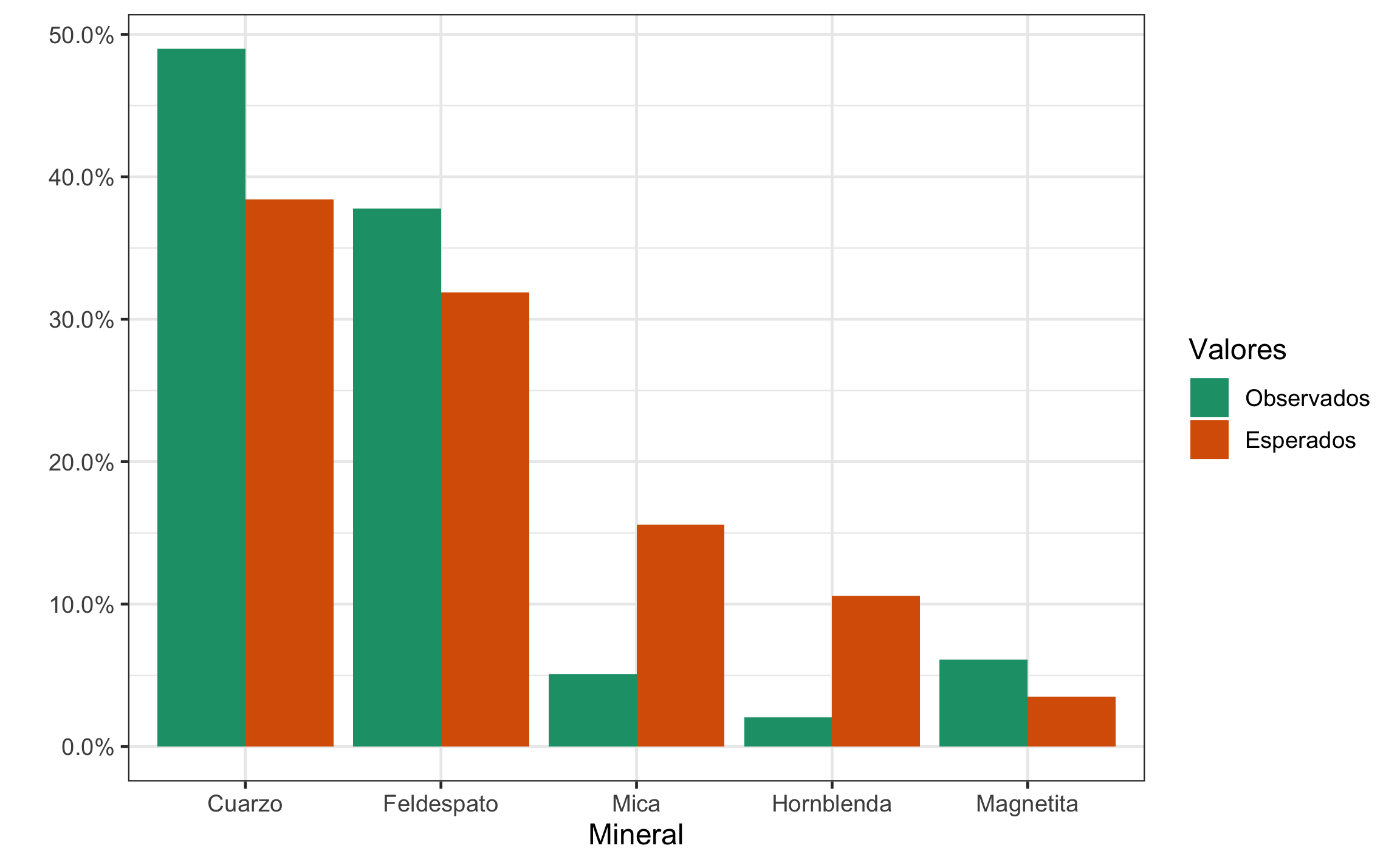
Figura 16.2: Gráfico de barras mostrando los valores observados y esperados para cada uno de los minerales.
El tamaño del efecto se calcula conforma la Ecuación (16.5).
\[\begin{equation} \phi = \sqrt{\frac{\chi^2}{N}} = \sqrt{\frac{19.53}{98}} = .45 \end{equation}\]
En R se puede calcular \(\phi\) con la función v.chi.sq del paquete MOTE, donde es necesario indicar el estadístico \(\chi^2\), el total de observaciones, el número de filas (para este caso es necesario usar 2 para que pueda funcionar), el número de columnas (categorías, \(K\)), y el nivel de significancia.
chi.gof.mult.phi = v.chi.sq(x2 = chi.gof.mult$statistic,
n = N,
r = 2,
c = 5,
a = a)
chi.gof.mult.phi[1:3] %>% unlist()## v.X-squared vlow vhigh
## 0.4464329 0.2826586 0.6474614Conclusión: El conteo de minerales en el sedimento difiere de los valores esperados, \(\chi^2(4, N = 98) = 19.53\), \(p = .001\), \(V\) = .45, 95% IC [.28, .65]. El efecto se puede considerar mediano, pero con un rango amplio de pequeño hasta muy grande.
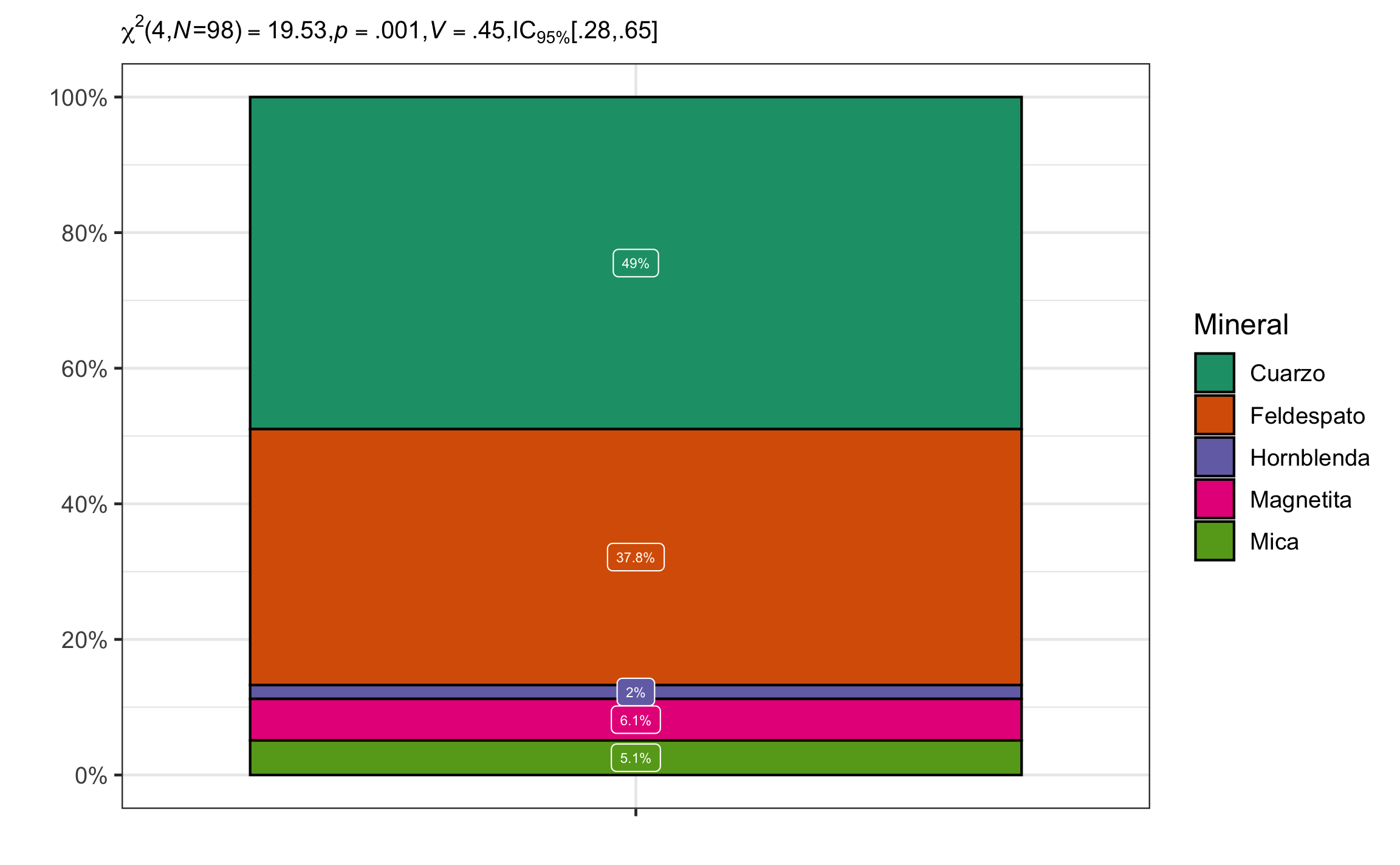
Figura 16.3: Gráfico de barra mostrando la proporción de los minerales, así como el resumen estadístico respectivo.
16.4.2 Tablas de Contingencia
En el caso de que se tienen dos variables nominales (o que se tratan como nominales), y por ende una tabla de contingencia, se pueden definir 2 tipos de muestreo, los cuales van a, de cierta forma, definir el tipo de pregunta (prueba) que se quiere responder (realizar). Estos tipos de muestreo se explican en Agresti (2007), y se asocian a las pruebas respectivas en Sheskin (2011) y Walpole et al. (2012), y serían los siguientes:
- Multinomial independiente: Cuando se determina un total de observaciones a realizar por fila o columna, donde cada fila o columna se interpreta como una muestra multinomial independiente. Se plantea para determinar homogeneidad.
- Multinomial conjunto: Cuando se determina el total de observaciones a realizar en general y se clasifican las observaciones de acuerdo a las categorías de las filas y columnas, donde cada celda es el conteo conjunto de las categorías que la representa. Se plantea para determinar independencia/asociación.
Para el caso de dos variables nominales, donde se representan por medio de una tabla de contingencia, los grados de libertad son \(v = (r-1)(c-1)\), correspondiendo a la multiplicación de los grados de libertad de las filas por los de las columnas.
Las frecuencias esperadas para cada celda de la tabla se determinan mediante la Ecuación (16.8), donde \(f_E = \text{frecuencia esperada}\), \(T_f = \text{total de la fila}\), \(T_c = \text{total de la columna}\), y \(N = \text{total de la tabla}\).
\[\begin{equation} f_E = \frac{T_f \cdot T_c}{N} \tag{16.8} \end{equation}\]
Por ejemplo, para los datos de la Tabla 16.1, para la Capa 1 se tendrían las siguientes frecuencias esperadas (de hecho en este caso las frecuencias esperadas son las mismas para todas las celdas de una misma fila):
\[\begin{equation} f_{E(cuarzo,1)} = \frac{91 \cdot 50}{200} = 22.75\\ f_{E(pedernal,1)} = \frac{48 \cdot 50}{200} = 12\\ f_{E(basalto,1)} = \frac{61 \cdot 50}{200} = 15.25\\ \end{equation}\]
16.4.2.1 Homogeneidad
Para ejemplificar la prueba de homogeneidad se usa el ejemplo de McKillup & Darby Dyar (2010) (Tabla 16.3), donde se tienen 20 mediciones de pozos en 3 localidades diferentes, a los cuales se les determinó si se encontraban contaminados o no con nitratos. Asuma \(\alpha=.05\).
| Townsville | Bowen | Mackay | Total | |
|---|---|---|---|---|
| Si | 12 | 7 | 14 | 33 |
| No | 8 | 13 | 6 | 27 |
| Total | 20 | 20 | 20 | 60 |
- Identificar la población, distribución, y la prueba apropiada:
- Población: nivel de contaminación en las localidades
- Distribución: \(\chi^2\)
- Prueba: \(\chi^2\) de homogeneidad, ya que se tienen dos variables nominales, y se controló la cantidad de observaciones por una de ellas (en este caso localidad)
- Establecer las hipótesis nula y alterna:
- \(H_0:\) La proporción de pozos contaminados o no es la misma para las diferentes localidades
- \(H_1:\) La proporción de pozos contaminados o no es diferente para las diferentes localidades
- Determinar parámetros de la distribución a comparar (\(H_0\)):
- \(v = (r-1)(c-1) = (2-1)(3-1) = 1 \cdot 2 = 2\)
- Determinar valores críticos
- \(\alpha = .05\)
- \(\chi^2_{\alpha,v} = \chi_{.05,2}^2=5.99\)
- Calcular el estadístico de prueba
- Usando la Ecuación (16.8) se tiene que los valores esperados son 11 para los contaminados y 9 para los no contaminados
- \(\chi^2 = \frac{(12-11)^2}{12} + \frac{(8-9)^2}{9} + \dots = 5.25\)
- Tomar una decisión
- El estadístico de prueba es menor al crítico, \(\chi^2 < \chi_{\alpha,v}^2\)
- El valor-p es mayor a \(\alpha = .05\), \(p = .072\)
- Decisión: No se rechaza \(H_0\). El valor-p cercano al \(\alpha\) indica evidencia marginal en favor de no rechazar \(H_0\), por lo que sería bueno investigar más allá los resultados.
Una forma de graficar tablas de contingencia es por medio de gráficos de mosaico, que es similar a un gráfico de barras donde todas las barras tienen la misma longitud y el área (relleno) representa la proporción de observaciones de la respectiva categoría, que a su vez representa las diferentes celdas de la tabla de contingencia. Para el caso del ejemplo se muestra en la Figura 16.4, donde se tiene la proporción de contaminación por localidad.
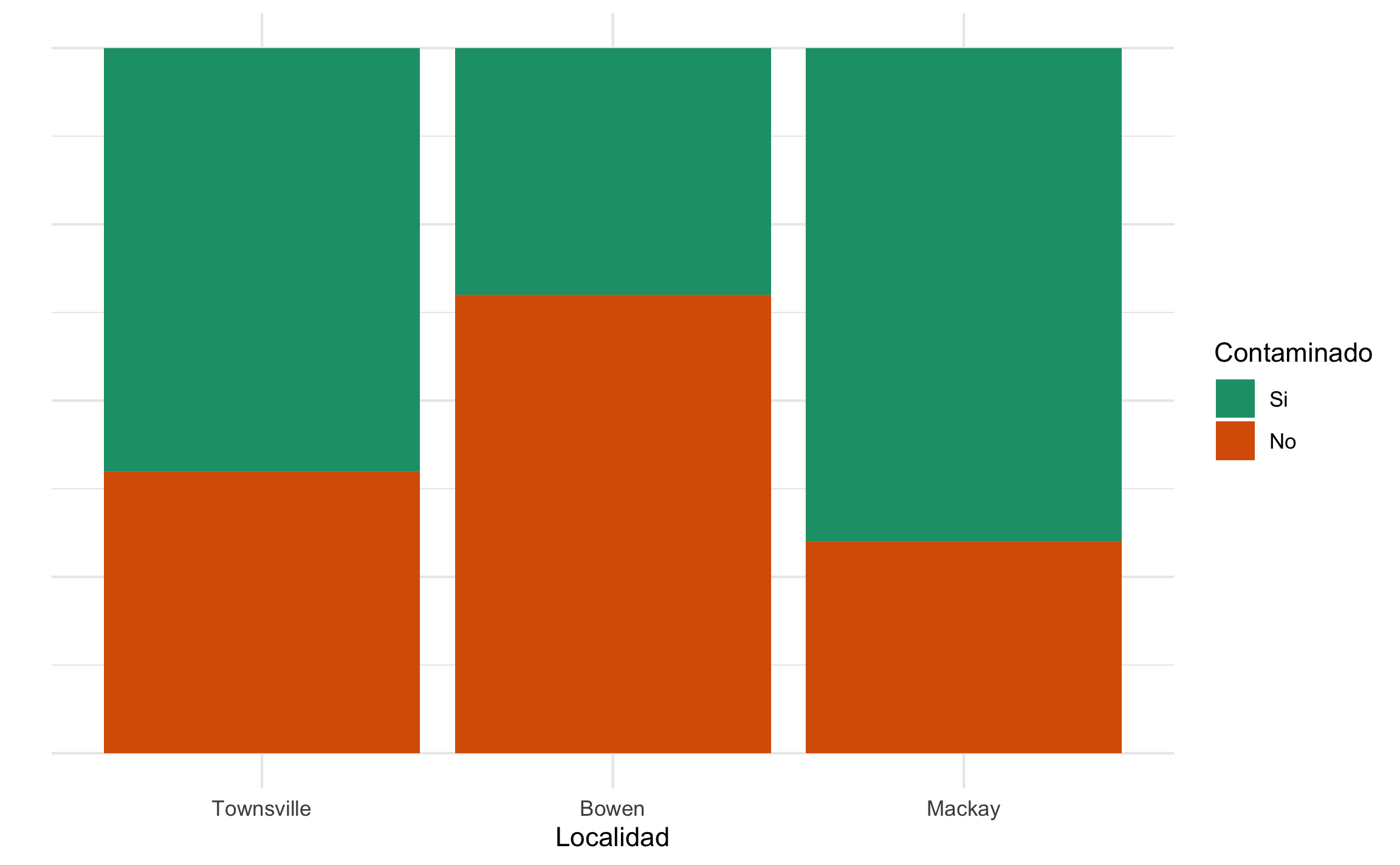
Figura 16.4: Gráfico de mosaico para el ejemplo de nivel de contaminación por localidad.
En R se tiene la función chisq.test para realizar estas pruebas. Para el caso de tablas de contingencia el único argumento que se necesita es la tabla, sin importar qué variable está en las columnas y qué variable está en las filas.
a = 0.05
chi.h = chisq.test(pozos_tab)
chi.h##
## Pearson's Chi-squared test
##
## data: pozos_tab
## X-squared = 5.2525, df = 2, p-value = 0.07235La función mosaic del paquete vcd (Meyer et al., 2017) permite visualizar el gráfico de mosaico, mostrando el valor-p de la prueba, y rellenando las barras (celdas) con los residuales de Pearson. En caso de que haya diferencia significativa entre lo observado y lo esperado las celdas serán coloreadas respectivamente. El gráfico de mosaico de la prueba se muestra en la Figura 16.5.
vcd::mosaic(t(pozos_tab),
direction = 'v',
shade = T,
gp=shading_hcl,
spacing=spacing_equal(sp = unit(.5, "lines")),
labeling=labeling_border(gp_labels = gpar(fontsize = 10)))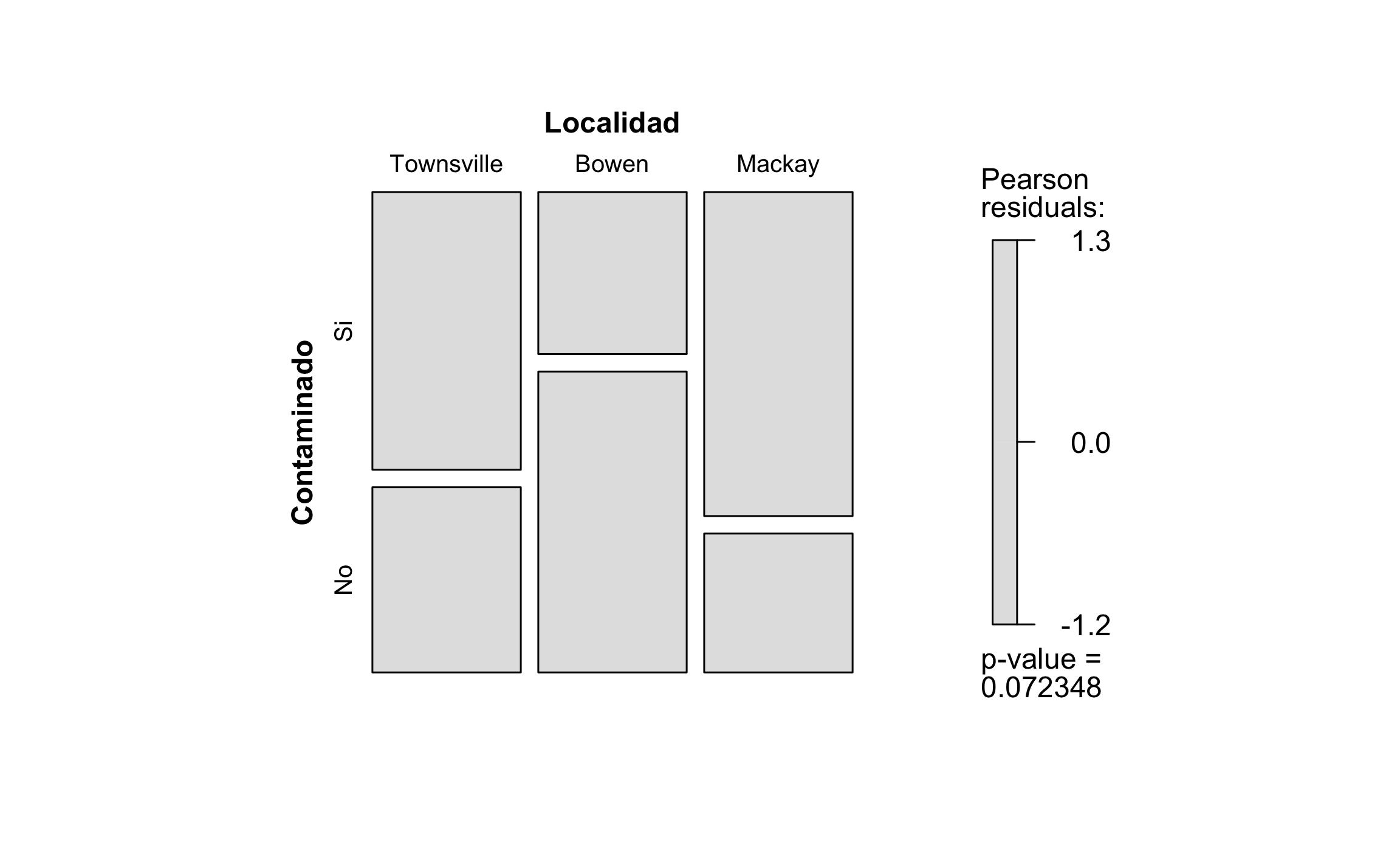
Figura 16.5: Gráfico de mosaico para el ejemplo de nivel de contaminación por localidad, mostrando el valor-p y los residuales.
Los residuales ajustados se pueden acceder a partir del objeto en que se guarda la prueba, como se muestra en el siguiente bloque. Estos residuales son los que realmente indican si hay una diferencia significativa entre lo observado y lo esperado (\(> |1.96|\) para \(\alpha=.05\)), que para el caso del ejemplo ocurre en la localidad de Bowen, donde hay menos valores observados para lo contaminado y más valores observados para lo no contaminado.
chi.h$stdres## Localidad
## Contaminado Townsville Bowen Mackay
## Si 0.5504819 -2.2019275 1.6514456
## No -0.5504819 2.2019275 -1.6514456Estos valores se pueden visualizar mejor coloreados de acuerdo a si están por encima (azul) o debajo (rojo) del valor crítico de acuerdo al nivel de significancia \(\alpha\).
| Contaminado | Townsville | Bowen | Mackay |
|---|---|---|---|
| Si | 0.55 | -2.202 | 1.651 |
| No | -0.55 | 2.202 | -1.651 |
El tamaño del efecto se puede calcular de acuerdo a la Ecuación (16.6) de la siguiente manera:
\[\begin{equation} V = \sqrt{\frac{\chi^2}{N \cdot v_{min}}}\\ V = \sqrt{\frac{5.25}{60 \cdot 1}} = .29 \end{equation}\]
En R se puede calcular por medio de las funciones CramerV del paquete DescTools (Signorell, 2020), y v.chi.sq del paquete MOTE.
CramerV(pozos_tab,
conf.level = 1-a,
method = 'ncchisqadj')## Cramer V lwr.ci upr.ci
## 0.2958751 0.1825742 0.5583684chi.h.v = v.chi.sq(x2 = chi.h$statistic, n = sum(pozos_tab),
r = nrow(pozos_tab), c = ncol(pozos_tab),
a = a)
chi.h.v[1:3] %>% unlist()## v.X-squared vlow vhigh
## 0.2958751 0.1825742 0.5583804Conclusión: El nivel de contaminación no varía significativamente de acuerdo a la localidad, \(\chi^2(2, N = 60) = 5.25\), \(p = .072\), \(V\) = .30, 95% IC [.18, .56]. El efecto se puede considerar mediano, pero con un rango amplio de pequeño hasta grande. Aunque el resultado no fue estadísticamente significativo, el valor-p se encuentra cerca del nivel de significancia, y si se estudian los residuales ajustados se ve que la localidad de Bowen difiere de los valores esperados.
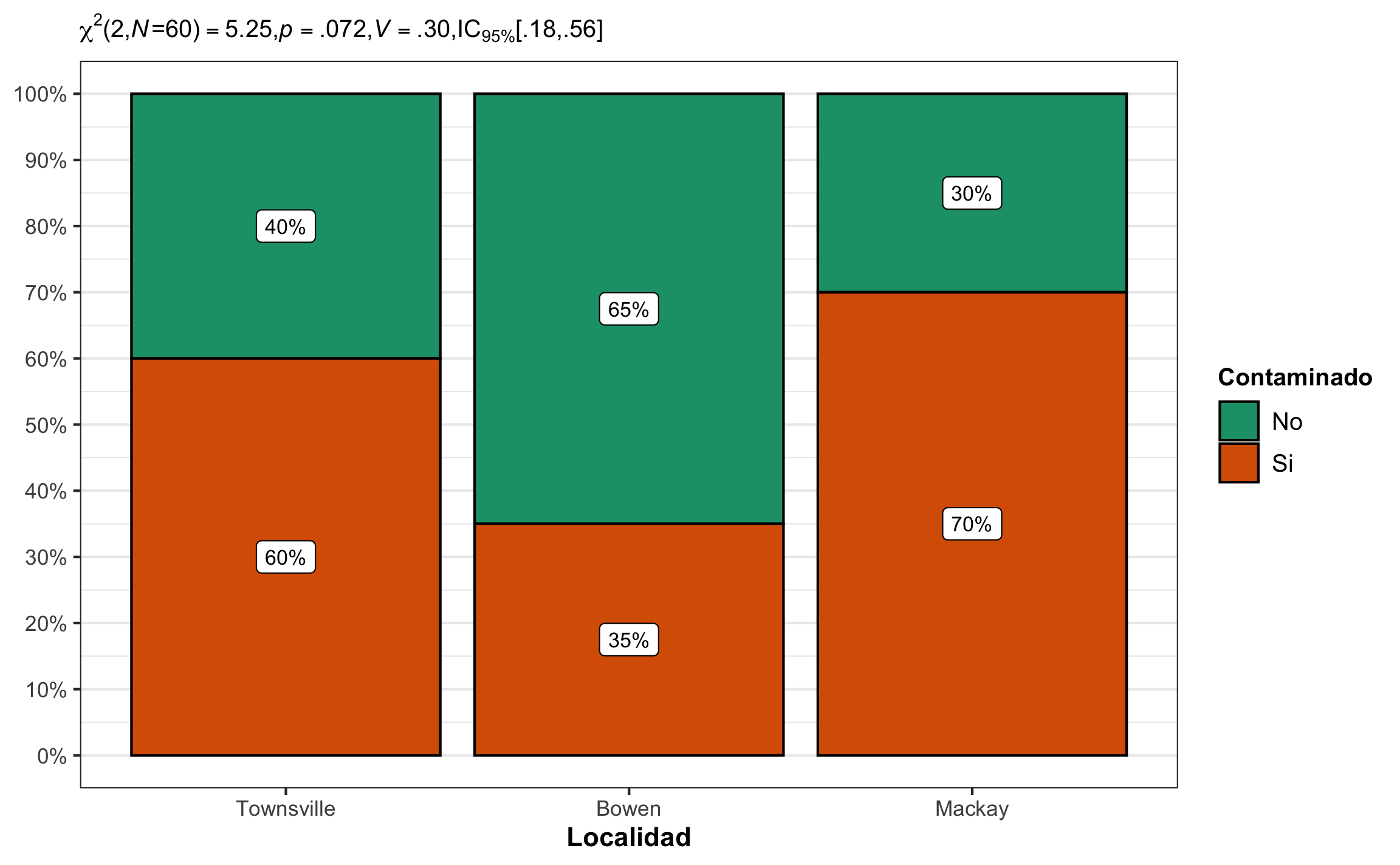
Figura 16.6: Gráfico mostrando la relación entre nivel de contaminación y localidad, el porcentaje de cada celda, así como el resumen estadístico respectivo.
16.4.2.2 Independencia/asociación
Para ejemplificar la prueba de homogeneidad se usa el ejemplo de Borradaile (2003) (Tabla 16.4), donde se tienen 246 mediciones de clastos, los cuales se clasificaron de acuerdo a la redondez y la distancia de la fuente. Asuma \(\alpha=.05\).
| 0-5 | 5-10 | 10-20 | 20-30 | 30-40 | Total | |
|---|---|---|---|---|---|---|
| Angular | 28 | 21 | 11 | 1 | 0 | 61 |
| Sub-angular | 23 | 23 | 14 | 8 | 9 | 77 |
| Sub-redondeado | 5 | 8 | 12 | 14 | 18 | 57 |
| Redondeado | 0 | 2 | 8 | 12 | 29 | 51 |
| Total | 56 | 54 | 45 | 35 | 56 | 246 |
- Identificar la población, distribución, y la prueba apropiada:
- Población: redondez de clasto de acuerdo a distancia de la fuente
- Distribución: \(\chi^2\)
- Prueba: \(\chi^2\) de asociación, ya que se tienen dos variables nominales (se podrían tratar como ordinales), y se controló la cantidad total de observaciones
- Establecer las hipótesis nula y alterna:
- \(H_0:\) No hay relación entre la redondez de los clastos y la distancia de la fuente, o la redondez de los clastos es independiente de la distancia de la fuente
- \(H_1:\) La redondez de los clastos depende (está en relacionado) de (con) la distancia de la fuente
- Determinar parámetros de la distribución a comparar (\(H_0\)):
- \(v = (r-1)(c-1) = (4-1)(5-1) = 3 \cdot 4 = 12\)
- Determinar valores críticos
- \(\alpha = .05\)
- \(\chi^2_{\alpha,v} = \chi_{.05,12}^2=21.03\)
- Calcular el estadístico de prueba
- Usando la Ecuación (16.8) se tiene que los valores esperados son los que se muestran a continuación
## Distancia
## Redondez 0-5 5-10 10-20 20-30 30-40
## Angular 13.9 13.4 11.2 8.7 13.9
## Sub-angular 17.5 16.9 14.1 11.0 17.5
## Sub-redondeado 13.0 12.5 10.4 8.1 13.0
## Redondeado 11.6 11.2 9.3 7.3 11.6- \(\chi^2 = \frac{(28-13.9)^2}{13.9} + \frac{(23-17.5)^2}{17.5} + \frac{(13-5)^2}{5} + \frac{(0-11.6)^2}{11.6} + \dots = 109.7\)
- Tomar una decisión
- El estadístico de prueba es mayor al crítico, \(\chi^2 > \chi_{\alpha,v}^2\)
- El valor-p es menor a \(\alpha = .05\), \(p < .001\)
- Decisión: Se rechaza \(H_0\)
El gráfico de mosaico para el caso del ejemplo se muestra en la Figura 16.7, donde se tiene la proporción de redondez por distancia.
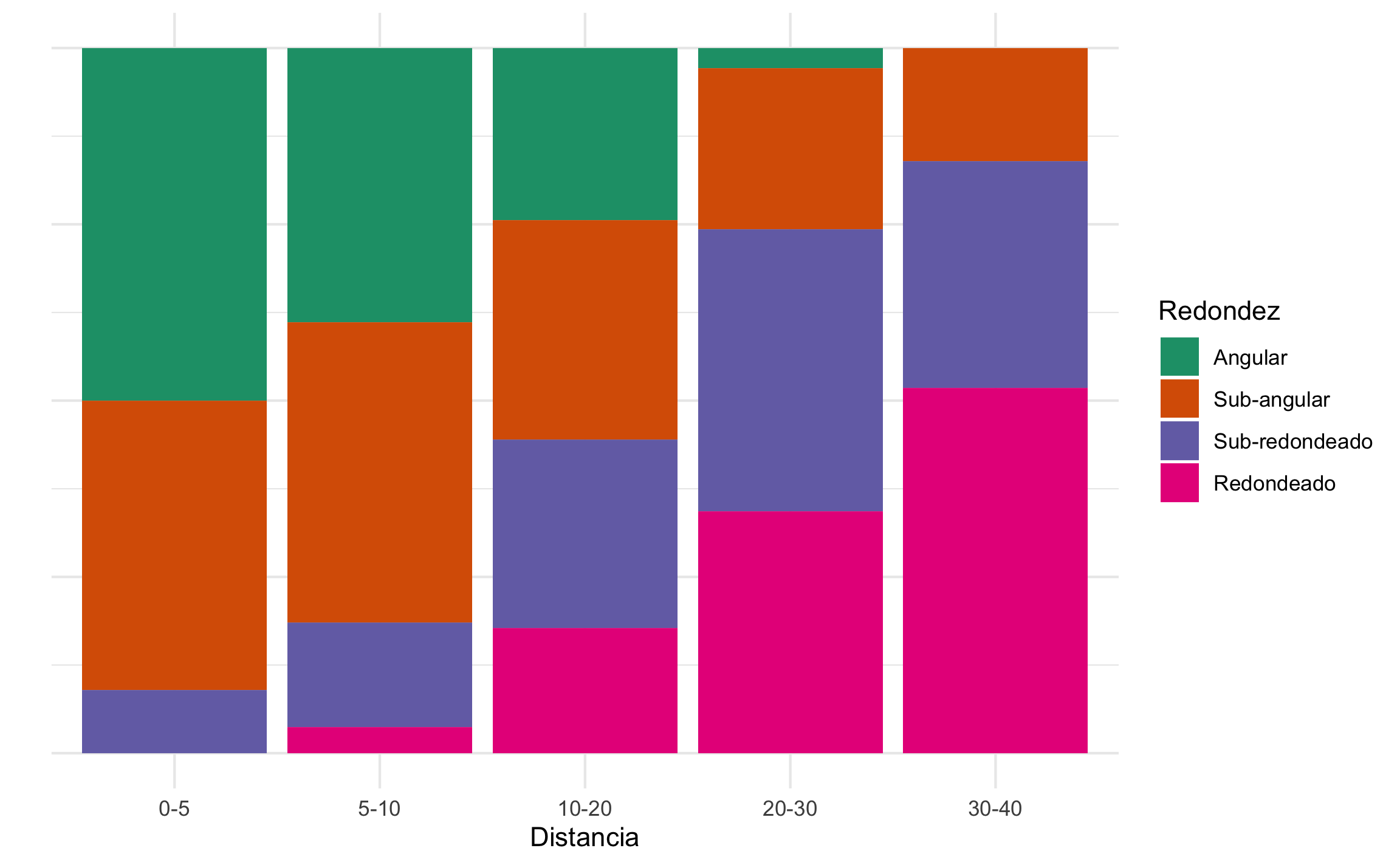
Figura 16.7: Gráfico de mosaico para el ejemplo de redondez contra distancia para diferentes clastos.
En R se usa la función chisq.test para realizar estas pruebas, a como se mostró en la prueba de homogeneidad.
a = 0.05
chi.ind = chisq.test(dist_red_tab)
chi.ind##
## Pearson's Chi-squared test
##
## data: dist_red_tab
## X-squared = 109.7, df = 12, p-value < 2.2e-16El gráfico de mosaico de la prueba se muestra en la Figura 16.8, donde se muestra que hay predominancia de clastos angulares a distancias cortas y de clastos redondeados a distancias largas, y hay pocos clastos angulares a distancias largas y redondeados a distancias cortas, que es de esperar. Los colores azules indican valores observados por encima de los valores esperados, mientras que los colores rojos indican valores observados por debajo de los valores esperados. Esta relación se puede ver de igual manera observando los residuales ajustados.
vcd::mosaic(t(dist_red_tab),
direction = 'v',
shade = T,
gp=shading_hcl,
spacing=spacing_equal(sp = unit(.5, "lines")),
labeling=labeling_border(gp_labels = gpar(fontsize = 10)))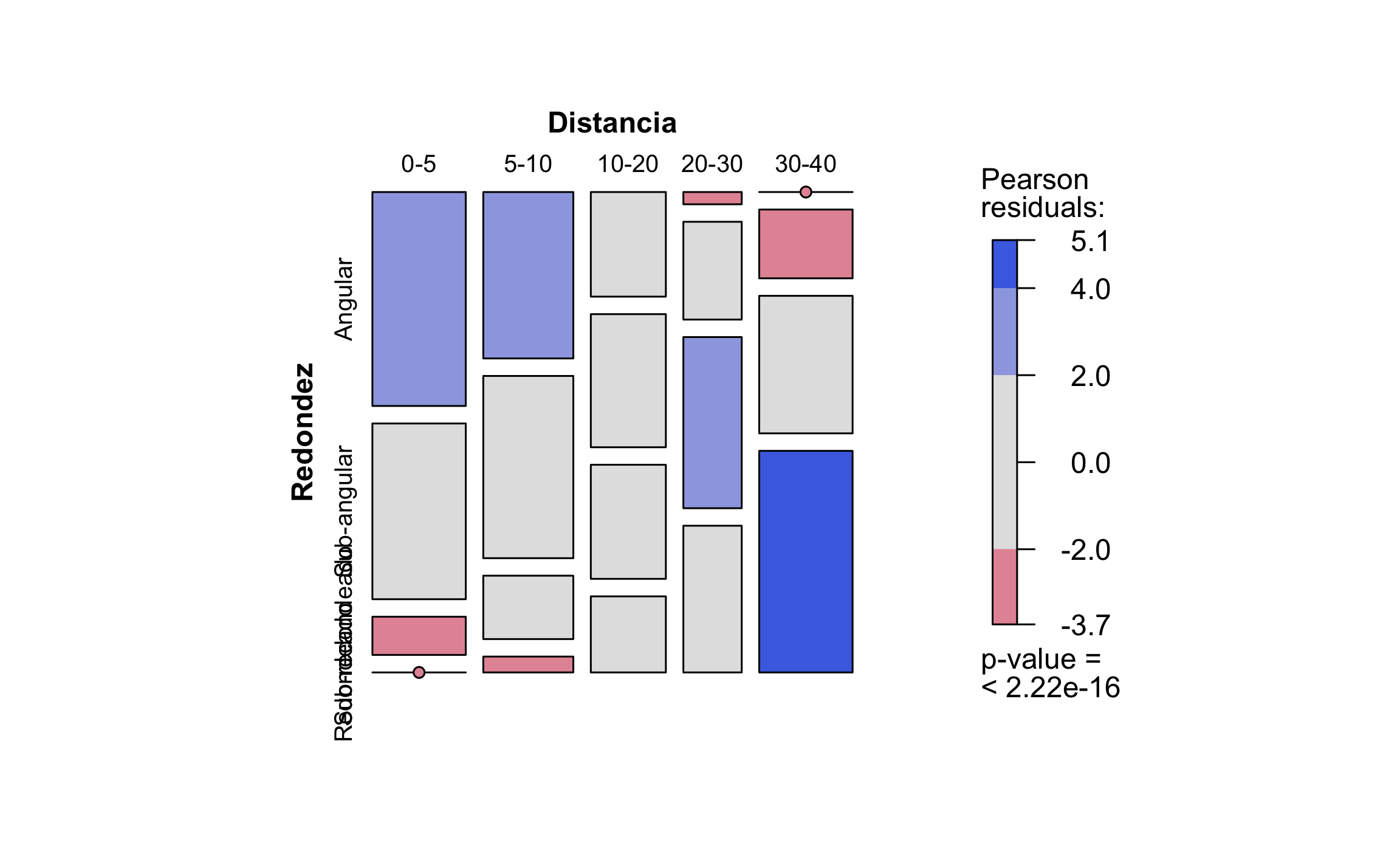
Figura 16.8: Gráfico de mosaico para el ejemplo de redondez contra distancia para diferentes clastos, mostrando el valor-p y los residuales.
chi.ind$stdres## Distancia
## Redondez 0-5 5-10 10-20 20-30 30-40
## Angular 4.96964852 2.71440797 -0.06054483 -3.24543922 -4.88949290
## Sub-angular 1.79412660 2.02545502 -0.03035945 -1.16315609 -2.79649153
## Sub-redondeado -2.87426901 -1.64730762 0.61490200 2.54795855 1.81070158
## Redondeado -4.35464292 -3.49389835 -0.54076506 2.13580090 6.52281597Estos valores se pueden visualizar mejor coloreados de acuerdo a si están por encima (azul) o debajo (rojo) del valor crítico de acuerdo al nivel de significancia \(\alpha\).
| Redondez | 0-5 | 5-10 | 10-20 | 20-30 | 30-40 |
|---|---|---|---|---|---|
| Angular | 4.97 | 2.714 | -0.061 | -3.245 | -4.889 |
| Sub-angular | 1.794 | 2.025 | -0.03 | -1.163 | -2.796 |
| Sub-redondeado | -2.874 | -1.647 | 0.615 | 2.548 | 1.811 |
| Redondeado | -4.355 | -3.494 | -0.541 | 2.136 | 6.523 |
El tamaño del efecto se puede calcular de acuerdo a la Ecuación (16.6) de la siguiente manera:
\[\begin{equation} V = \sqrt{\frac{\chi^2}{N \cdot v_{min}}}\\ V = \sqrt{\frac{109.7}{264 \cdot 3}} = .38 \end{equation}\]
En R se puede calcular por medio de las funciones CramerV del paquete DescTools, y v.chi.sq del paquete MOTE.
CramerV(dist_red_tab,
conf.level = 1-a,
method = 'ncchisqadj')## Cramer V lwr.ci upr.ci
## 0.3855446 0.3179013 0.4576978chi.ind.v = v.chi.sq(x2 = chi.ind$statistic, n = sum(dist_red_tab),
r = nrow(dist_red_tab), c = ncol(dist_red_tab),
a = a)
chi.ind.v[1:3] %>% unlist()## v.X-squared vlow vhigh
## 0.3855446 0.3179001 0.4576964Conclusión: Hay una asociación entre la redondez del clasto y su distancia de la fuente, \(\chi^2(12, N = 246) = 109.70\), \(p < .001\), \(V\) = .39, 95% IC [.32, .46]. El efecto se puede considerar grande.
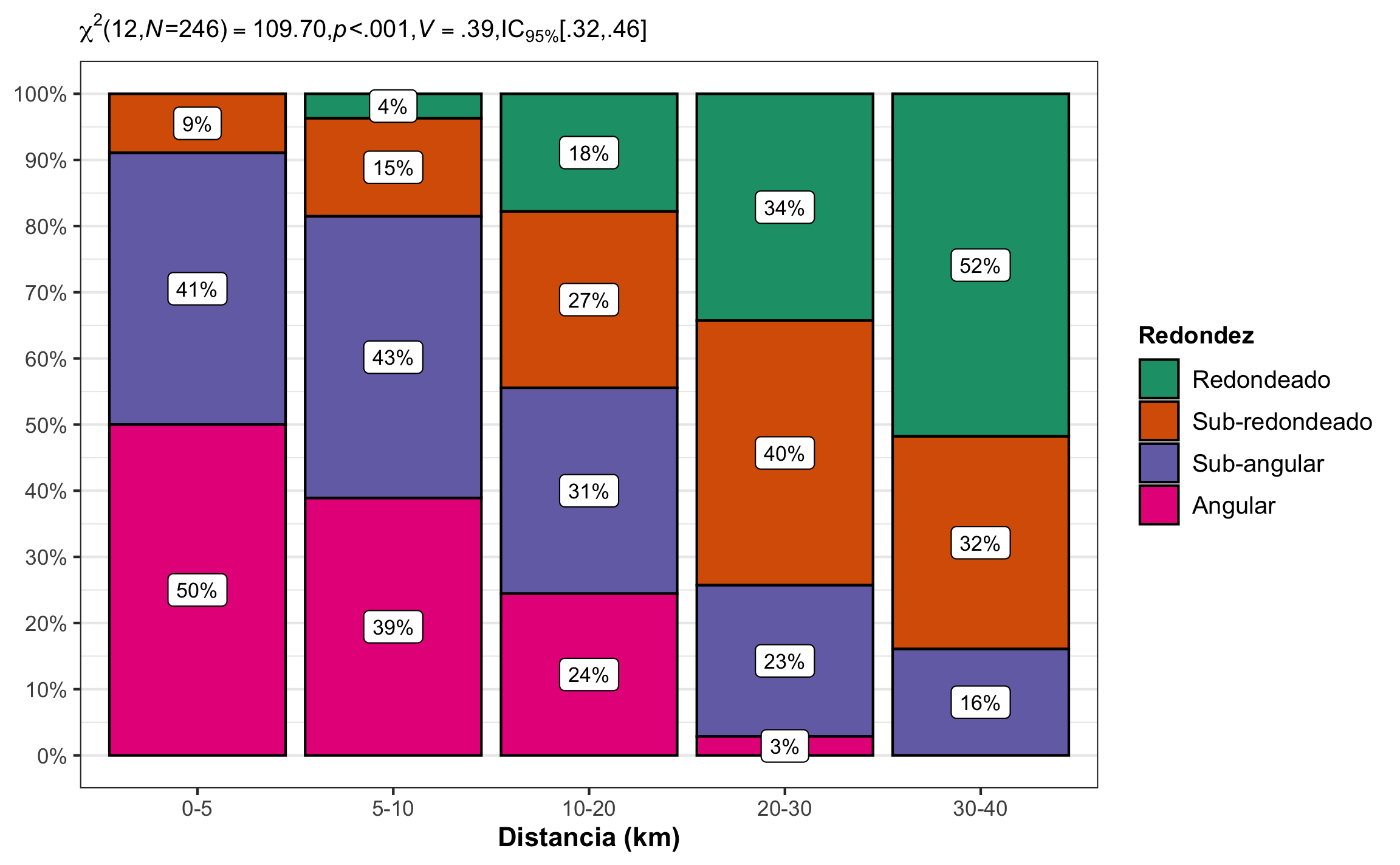
Figura 16.9: Gráfico mostrando la relación entre distancia de la fuente y redondez, el porcentaje de cada celda, así como el resumen estadístico respectivo.
16.5 Pruebas sobre rangos (ordinales)
Cuando se tienen datos ordinales o cuantitativos continuos que no se distribuyen normalmente, éstos se convierten a rangos (valor más bajo es 1 y así sucesivamente, donde valores empatados se promedian), y los análisis se realizan sobre los datos ranqueados. Las pruebas sobre rangos son homólogas a las pruebas paramétricas que hacen inferencias sobre la medida de tendencia central (1 y 2 muestras) y de asociación/relación (entre 2 variables). En el caso de las pruebas no paramétricas la mediana es más utilizada y reportada como medida de tendencia central.
16.5.1 Rango con signo de Wilcoxon
Esta prueba se puede utilizar con 1 muestra o 2 muestras dependientes, ya que con esta última se trabaja con el vector de las diferencias. Las hipótesis serían las siguientes:
- \(H_0: Mdn = Mdn_0\) La mediana es igual a un valor dado, o \(R+ = R-\),
- \(H_1: Mdn \neq Mdn_0\) La mediana es diferente al valor dado, o \(R+ \neq R-\)
El procedimiento para la prueba sería el siguiente:
- Para el caso de 1 muestra se le resta a los valores el valor hipotético o con el cual se quiere comparar. Para el caso de 2 muestras dependientes se saca la diferencia entre las muestras.
- De haber alguna diferencia igual a cero (0) se descarta.
- Se ranquean las diferencia en valor absoluto.
- Se suman los rangos para las diferencias positivas (\(R+\)) y para las diferencias negativas (\(R-\)).
- Se escoge el menor \(R\) como \(T\).
- Se rechaza \(H_0\) si el \(T < T_{crit}\) o si \(p < \alpha\).
Para el tamaño del efecto (Ecuación (16.2)) se necesita el estadístico \(Z\), el cual se puede obtener a partir del valor-p que arroja la prueba (encontrando el cuantil de la distribución normal - qnorm(p/2)), o por medio de la aproximación a la distribución normal conforme las Ecuaciones (16.9), (16.10), y (16.11).
\[\begin{equation} \mu_T = \frac{N(N+1)}{4} \tag{16.9} \end{equation}\]
\[\begin{equation} \sigma_T = \sqrt{\frac{N(N+1)(2N+1)}{24}} \tag{16.10} \end{equation}\]
\[\begin{equation} Z = \frac{T - \mu_T}{\sigma_T} \tag{16.11} \end{equation}\]
El uso de la prueba se demuestra con el ejemplo Swan & Sandilands (1995), donde se tenía el contenido de cuarzo en secciones delgadas de una roca ígnea. Es posible que esta muestra provenga de una población con valor central de 20%? Asuma \(\alpha = .05\).
El resultado de realizar el ranqueo y la suma de los respectivos rangos de acuerdo a los signos se muestra en las Tablas 16.5 y 16.6. De acuerdo con los resultados el estadístico sería \(T=8.5\), y el valor crítico sería 4.
loc0 = 20
a = 0.05
cuarzo = c(23.5, 16.6, 25.4, 19.1, 19.3, 22.4, 20.9, 24.9)
Q = tibble(Q = cuarzo) %>%
mutate(dif = Q-loc0,
signo = factor(sign(dif),
levels = c(-1,1),
labels = c('Negativo','Positivo')),
ranking = rank(abs(dif)))
N = nrow(Q)| Q (%) | Diferencia | Signo | Ranqueo |
|---|---|---|---|
| 16.6 | -3.4 | Negativo | 5 |
| 19.1 | -0.9 | Negativo | 2.5 |
| 19.3 | -0.7 | Negativo | 1 |
| 20.9 | 0.9 | Positivo | 2.5 |
| 22.4 | 2.4 | Positivo | 4 |
| 23.5 | 3.5 | Positivo | 6 |
| 24.9 | 4.9 | Positivo | 7 |
| 25.4 | 5.4 | Positivo | 8 |
| Signo | T |
|---|---|
| Negativo | 8.5 |
| Positivo | 27.5 |
En R se tiene la función wilcox.test que realiza la prueba, y se puede usar para el caso de una muestra o dos muestras dependientes (paired = T), donde hay que especificar el o los vectores, la medida de posición a comparar (mu), si se quiere un intervalo de confianza, y el nivel de confianza. Nota: Esta función NO necesariamente reporta el W más bajo (creo que siempre presenta el positivo), pero ésto no afecta la interpretación del valor-p o el intervalo de confianza.
wilcox.res = wilcox.test(cuarzo, mu = loc0,
paired = F,
conf.int = T, conf.level = 1-a)
wilcox.res##
## Wilcoxon signed rank test with continuity correction
##
## data: cuarzo
## V = 27.5, p-value = 0.207
## alternative hypothesis: true location is not equal to 20
## 95 percent confidence interval:
## 18.75005 24.44997
## sample estimates:
## (pseudo)median
## 21.56763Decisión: No se rechaza \(H_0\)
Para el tamaño del efecto se pueden usar las Ecuaciones (16.9), (16.10), (16.11), y (16.2).
\[\begin{equation} \mu_T = \frac{N(N+1)}{4} = \frac{8(8+1)}{4} = 18 \end{equation}\]
\[\begin{equation} \sigma_T = \sqrt{\frac{N(N+1)(2N+1)}{24}} = \sqrt{\frac{8(8+1)(2 \cdot 8+1)}{24}} = 7.14 \end{equation}\]
\[\begin{equation} Z = \frac{T - \mu_T}{\sigma_T} = \frac{8.5 - 18}{7.14} = -1.33 \end{equation}\]
\[\begin{equation} r = \frac{Z}{\sqrt{N}} = \frac{-1.33}{\sqrt{8}} = -.47 \end{equation}\]
En R la función wilcox_effsize del paquete rstatix (Kassambara, 2020) puede calcular este valor directamente, pero ocupa que los datos se encuentren en un dataframe en formato largo, definir la fórmula (variable~1 para el caso de 1 muestra, o variable~grupos para el caso de 2 muestras), indicar si las muestras son dependientes (paired = T), y en el caso de 1 muestra el valor a comparar (mu).
wilcox.r = wilcox_effsize(Q, Q~1, mu = loc0,
paired = F)
wilcox.r## # A tibble: 1 x 6
## .y. group1 group2 effsize n magnitude
## <chr> <chr> <chr> <dbl> <int> <ord>
## 1 Q 1 null model 0.471 8 moderatePara este tamaño de efecto no está tan establecido el cómo obtener el intervalo de confianza, pero se puede aproximar por medio del intervalo de confianza para el coeficiente de correlación \(r\), por medio de la función CorCI del paquete DescTools.
wilcox.r.ci = CorCI(rho = wilcox.r$effsize[[1]], n = N, conf.level = 1-a)
wilcox.r.ci## cor lwr.ci upr.ci
## 0.4708975 -0.3498735 0.8826739Conclusión: El contenido de cuarzo de la roca ígnea no es significativamente diferente a la mediana de 20% , \(Mdn^* = 21.57\), 95% IC \([18.75\), \(24.45]\), \(T = 27.50\), \(p = .207\), \(r = .47\), 95% IC \([-.35, .88]\). El efecto se puede considerar mediano, pero con un rango amplio de mediano, en dirección opuesta, hasta muy grande.
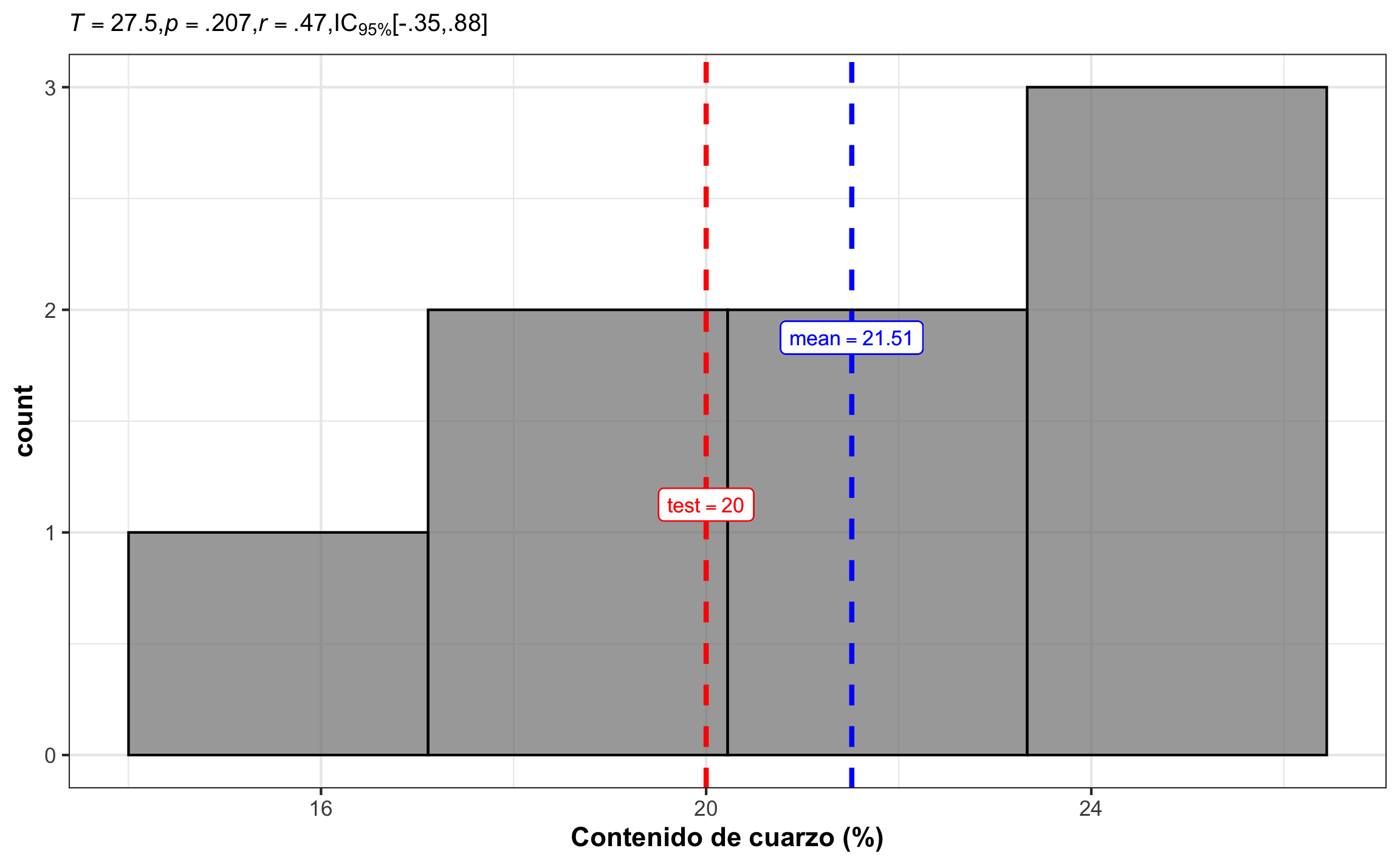
Figura 16.10: Histograma del contenido de cuarzo, mostrando la media muestral (azul) y el valor a comparar (rojo), así como el resumen estadístico respectivo.
16.5.2 Suma de rangos de Wilcoxon / U de Mann-Whitney
Esta prueba se utiliza con 2 muestras independientes. Las hipótesis serían las siguientes:
- \(H_0: Mdn_1 = Mdn_2\) La mediana es la misma para las dos muestras, o \(\bar{R}_1 = \bar{R}_2\),
- \(H_1: Mdn_1 \neq Mdn_2\) La mediana es diferente para las dos muestras, o \(\bar{R}_1 \neq \bar{R}_2\)
El procedimiento para la prueba sería el siguiente:
- Se agrupan las dos muestras en una sola y se ranquea.
- Se suman los rangos para cada muestra (\(R_{1}\), \(R_{2}\)).
- Se calcula el estadístico \(U\) para cada muestra (Ecuación (16.12)) y se escoge el menor.
- Se rechaza \(H_0\) si el \(U < U_{crit}\) o si \(p < \alpha\).
\[\begin{equation} U_i = R_i - \frac{n_i(n_i+1)}{2} \tag{16.12} \end{equation}\]
Además se tienen las siguientes propiedades:
\[\begin{equation} R_1 + R_2 = \frac{(n_1+n_2)(n_1+n_2+1)}{2} \tag{16.13} \end{equation}\]
\[\begin{equation} U_1 + U_2 = n_1 n_2 \tag{16.14} \end{equation}\]
Para el tamaño del efecto (Ecuación (16.2)) se necesita el estadístico \(Z\), el cual se puede obtener a partir del valor-p que arroja la prueba (encontrando el cuantil de la distribución normal - qnorm(p/2)), o por medio de la aproximación a la distribución normal conforme las Ecuaciones (16.15), (16.16), y (16.17).
\[\begin{equation} \mu_u = \frac{n_1 n_2}{2} \tag{16.15} \end{equation}\]
\[\begin{equation} \sigma_u = \sqrt{\frac{(n_1 n_2)(n_1 + n_2 + 1)}{12}} \tag{16.16} \end{equation}\]
\[\begin{equation} Z = \frac{U - \mu_u}{\sigma_u} \tag{16.17} \end{equation}\]
El uso de la prueba se demuestra con el ejemplo Swan & Sandilands (1995), donde se tenían braquiópodos en dos capas (A, B) y se les midió la longitud (cm). Es posible que estas muestras provenga de una misma población? Asuma \(\alpha = .05\).
El resultado de realizar el ranqueo y la suma de los respectivos rangos de acuerdo a las muestras se detalla en las Tablas 16.7 y 16.8. De acuerdo con los resultados el estadístico sería \(U=23.5\), y el valor crítico sería 17.
a = 0.05
A = c(3.2, 3.1, 3.1, 3.3, 2.9, 2.9, 3.5, 3.0)
B = c(3.1, 3.1, 2.8, 3.1, 3.0, 2.6, 3.0, 3.0, 3.1, 2.8)
braq = stack(list(A=A,
B=B)) %>%
mutate(ranking = rank(values))
N = nrow(braq)| Longitud (cm) | Capa | Ranqueo |
|---|---|---|
| 2.6 | B | 1 |
| 2.8 | B | 2.5 |
| 2.8 | B | 2.5 |
| 2.9 | A | 4.5 |
| 2.9 | A | 4.5 |
| 3.0 | A | 7.5 |
| 3.0 | B | 7.5 |
| 3.0 | B | 7.5 |
| 3.0 | B | 7.5 |
| 3.1 | A | 12.5 |
| 3.1 | A | 12.5 |
| 3.1 | B | 12.5 |
| 3.1 | B | 12.5 |
| 3.1 | B | 12.5 |
| 3.1 | B | 12.5 |
| 3.2 | A | 16 |
| 3.3 | A | 17 |
| 3.5 | A | 18 |
| Capa | n | Rango medio | R | U |
|---|---|---|---|---|
| A | 8 | 11.56 | 92.5 | 56.5 |
| B | 10 | 7.85 | 78.5 | 23.5 |
\[\begin{equation} U_1 = R_1 - \frac{n_1(n_1+1)}{2} = 92.5 - \frac{8(8+1)}{2} = 56.5\\ U_2 = R_2 - \frac{n_2(n_2+1)}{2} = 78.5 - \frac{10(10+1)}{2} = 23.5 \end{equation}\]
En R se tiene la función wilcox.test que realiza la prueba, donde hay que especificar los vectores o la fórmula, si se quiere un intervalo de confianza, y el nivel de confianza. Nota: El orden de los grupos altera el estadístico reportado y el signo de la diferencia e intervalo de confianza pero no la significancia de la prueba.
Con \(A\) primero.
wilcox.test(A,B,conf.int = T, conf.level = 1-a)##
## Wilcoxon rank sum test with continuity correction
##
## data: A and B
## W = 56.5, p-value = 0.145
## alternative hypothesis: true location shift is not equal to 0
## 95 percent confidence interval:
## -0.09995953 0.39995658
## sample estimates:
## difference in location
## 0.1000317Con \(B\) primero.
mwu.res = wilcox.test(B,A,
conf.int = T, conf.level = 1-a)
mwu.res##
## Wilcoxon rank sum test with continuity correction
##
## data: B and A
## W = 23.5, p-value = 0.145
## alternative hypothesis: true location shift is not equal to 0
## 95 percent confidence interval:
## -0.39995658 0.09995953
## sample estimates:
## difference in location
## -0.1000317Con fórmula, que va a depender del orden de las categorías de la variable agrupadora.
wilcox.test(values~ind,data = braq,conf.int = T, conf.level = 1-a)##
## Wilcoxon rank sum test with continuity correction
##
## data: values by ind
## W = 56.5, p-value = 0.145
## alternative hypothesis: true location shift is not equal to 0
## 95 percent confidence interval:
## -0.09995953 0.39995658
## sample estimates:
## difference in location
## 0.1000317Decisión: No se rechaza \(H_0\)
Para el tamaño del efecto se pueden usar las Ecuaciones (16.15), (16.16), (16.17), y (16.2).
\[\begin{equation} \mu_u = \frac{n_1 n_2}{2} = \frac{8 \cdot 10}{2} = 40 \end{equation}\]
\[\begin{equation} \sigma_u = \sqrt{\frac{(n_1 n_2)(n_1 + n_2 + 1)}{12}} = \sqrt{\frac{(8 \cdot 10)(8 + 10 + 1)}{12}} = 11.25 \end{equation}\]
\[\begin{equation} Z = \frac{U - \mu_u}{\sigma_u} = \frac{23.5 - 40}{11.25} = -1.47 \end{equation}\]
\[\begin{equation} r = \frac{Z}{\sqrt{N}} = \frac{-1.46}{\sqrt{18}} = -.35 \end{equation}\]
En R la función wilcox_effsize del paquete rstatix puede calcular este valor directamente, pero ocupa que los datos se encuentren en un dataframe en formato largo, y definir la fórmula (variable~grupos).
mwu.r = wilcox_effsize(braq, values~ind)
mwu.r## # A tibble: 1 x 7
## .y. group1 group2 effsize n1 n2 magnitude
## <chr> <chr> <chr> <dbl> <int> <int> <ord>
## 1 values A B 0.354 8 10 moderatePara este tamaño de efecto no está tan establecido el cómo obtener el intervalo de confianza, pero se puede aproximar por medio del intervalo de confianza para el coeficiente de correlación \(r\), por medio de la función CorCI del paquete DescTools.
mwu.r.ci = CorCI(rho = mwu.r$effsize[[1]], n = N, conf.level = 1-a)
mwu.r.ci## cor lwr.ci upr.ci
## 0.3542525 -0.1349343 0.7045904Conclusión: La longitud de los braquiópodos no difiere significativamente entre las capas A y B, \(Mdn_d = -0.10\), 95% IC \([-0.40\), \(0.10]\), \(U = 23.50\), \(p = .145\), \(r = .35\), 95% IC \([-.13, .70]\). El efecto se puede considerar mediano, pero con un rango amplio de pequeño, en dirección opuesta, hasta muy grande.
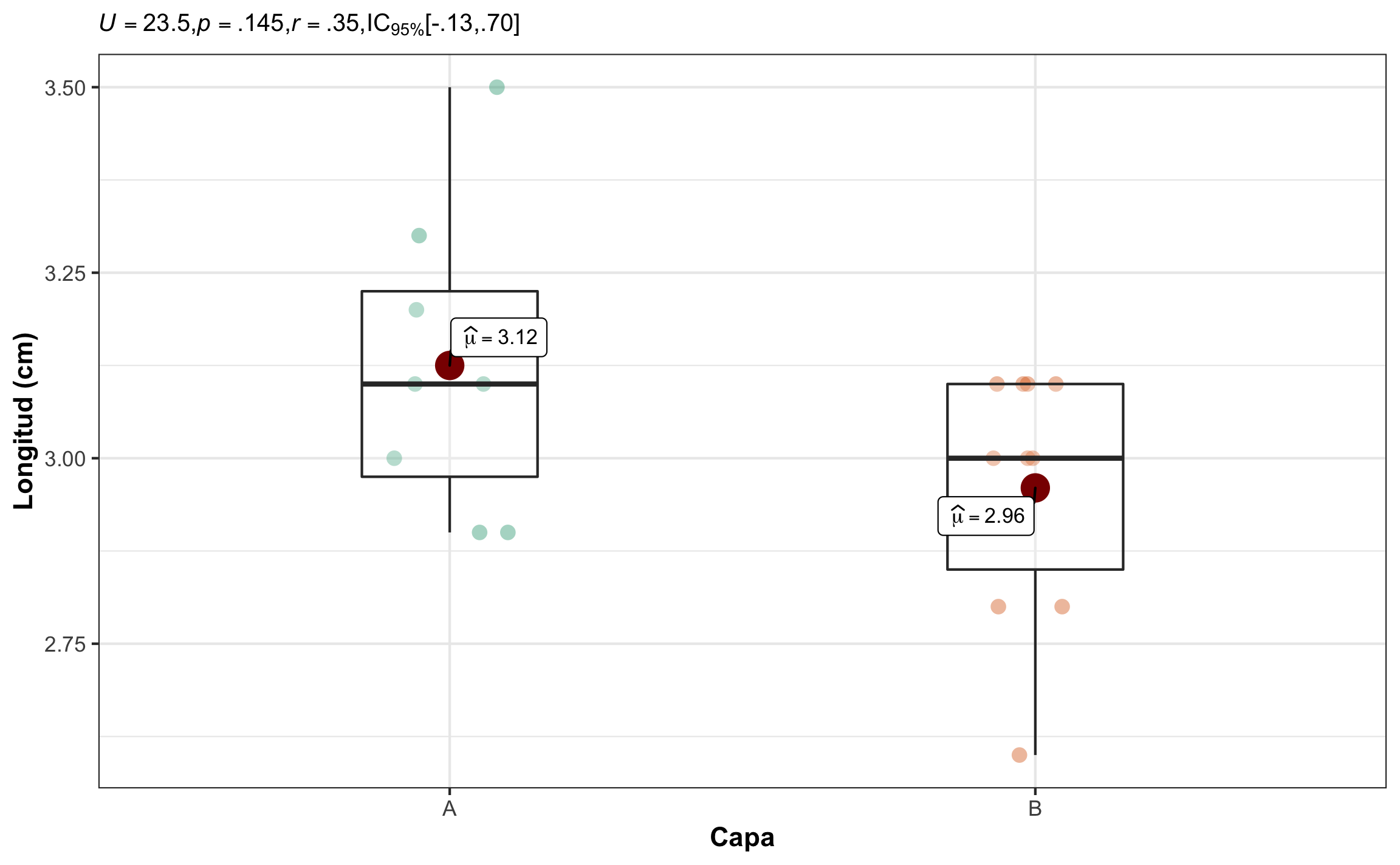
Figura 16.11: Gráfico de caja mostrando el efecto de la capa sobre la longitud de los braquiópodos, así como el resumen estadístico respectivo.
16.5.3 Kruskal-Wallis
Esta prueba se utiliza con \(2+\) muestras independientes (homólogo de ANOVA). Las hipótesis serían las siguientes:
- \(H_0: Mdn_1 = Mdn_2 = Mdn_3 = \cdots = Mdn_k\) La mediana es la misma para todas las muestras, o \(\bar{R}_1 = \bar{R}_2 = \bar{R}_3 = \cdots = \bar{R}_k\),
- \(H_1:\) Al menos 1 de las medianas es diferente.
El procedimiento para la prueba sería el siguiente:
- Se agrupan las muestras en una sola y se ranquea.
- Se suman los rangos para cada muestra (\(r_{k}\)).
- Se calcula el estadístico \(H\) (Ecuación (16.18)), el cual sigue una distribución \(\chi^2\), con grados de libertad \(v=k-1\).
- Se rechaza \(H_0\) si el \(H > \chi^2_{crit}\) o si \(p < \alpha\).
\[\begin{equation} H = \frac{12}{N(N+1)}\sum_{k=1}^k\frac{R_{k}^2}{n_k}-3(N+1) \tag{16.18} \end{equation}\]
De manera similar al ANOVA, si se encuentra un resultado significativo es necesario explorar más por medio de análisis posteriores (post-hoc), donde los análisis más utilizados son las pruebas de Dunn y Nemenyi, que realizan comparaciones múltiples sobre los rangos, y ajusta el valor-p (de acuerdo a diferentes métodos) para una correcta interpretación.
El uso de la prueba se demuestra con el ejemplo de McKillup & Darby Dyar (2010), donde se tiene el contenido de \(MgO\) presente en cuatro turmalinas en tres sitios diferentes (\(k=3\)): Mount Mica, Sebago Batholith, Black Mountain. Asuma \(\alpha = .05\).
El resultado de realizar el ranqueo y la suma de los respectivos rangos de acuerdo a las muestras se detalla en las Tablas 16.9 y 16.10. El estadístico crítico sería \(\chi^2_{\alpha,v} = \chi^2_{.05,2} = 5.99\).
a = 0.05
dat.kw = import('data/anova MgO.csv', setclass = 'tibble') %>%
mutate(Location = as.factor(Location) %>%
fct_reorder(MgO))
N = nrow(dat.kw)| Localidad | MgO (%) | Ranqueo |
|---|---|---|
| Black Mountain | 1 | 1 |
| Black Mountain | 2 | 2 |
| Sebago Batholith | 4 | 3.5 |
| Black Mountain | 4 | 3.5 |
| Sebago Batholith | 5 | 5.5 |
| Black Mountain | 5 | 5.5 |
| Mount Mica | 7 | 7.5 |
| Sebago Batholith | 7 | 7.5 |
| Mount Mica | 8 | 9.5 |
| Sebago Batholith | 8 | 9.5 |
| Mount Mica | 10 | 11 |
| Mount Mica | 11 | 12 |
| Localidad | n | Rango medio | R |
|---|---|---|---|
| Black Mountain | 4 | 3.0 | 12 |
| Sebago Batholith | 4 | 6.5 | 26 |
| Mount Mica | 4 | 10.0 | 40 |
\[\begin{equation} H = \frac{12}{N(N+1)}\sum_{k=1}^k\frac{R_{k}^2}{n_k}-3(N+1)\\ H = \frac{12}{12(12+1)}\left(\frac{12^2}{4}+\frac{26^2}{4}+\frac{40^2}{4}\right)-3(12+1) = 7.54 \end{equation}\]
En R se tiene la función kruskal.test que realiza la prueba.
kw.res = kruskal.test(MgO ~ Location, dat.kw)
kw.res##
## Kruskal-Wallis rank sum test
##
## data: MgO by Location
## Kruskal-Wallis chi-squared = 7.6454, df = 2, p-value = 0.02187Decisión: Se rechaza \(H_0\)
Para el tamaño del efecto se pueden usar las Ecuaciones (16.3) o (16.4).
\[\begin{equation} \eta_H^2 = \frac{H-k+1}{N-k} = \frac{7.54-3+1}{12-3} = .62 \end{equation}\]
\[\begin{equation} \epsilon^2 = \frac{H}{(N^2-1)/(N+1)} = \frac{7.54}{(12^2-1)/(12+1)} = .69 \end{equation}\]
En R la función kruskal_effsize del paquete rstatix puede calcular \(\eta_H^2\), y la función epsilonSquared del paquete rcompanion (Mangiafico, 2020) puede calcular \(\epsilon^2\). Para estos tamaño de efecto no está establecido el cómo obtener el intervalo de confianza, pero se puede utilizar la técnica de bootstrap (16.6). Las funciones mencionadas utiliza este método, definiendo que se quiere el intervalo de confianza con ci = T. Como este método varía cada vez que se corre es recomendable definir el punto de partida para siempre obtener el mismo resultado, ésto se logra definiendo set.seed y escogiendo un número entero cualquiera.
set.seed(101)
kw.eta = kruskal_effsize(dat.kw, MgO ~ Location, ci = T, conf.level = 1-a)
kw.eta## # A tibble: 1 x 7
## .y. n effsize conf.low conf.high method magnitude
## <chr> <int> <dbl> <dbl> <dbl> <chr> <ord>
## 1 MgO 12 0.627 0.26 0.85 eta2[H] largewith(dat.kw,epsilonSquared(x = MgO,g = Location,ci = T,conf = 1-a))## # A tibble: 1 x 3
## epsilon.squared lower.ci upper.ci
## <dbl> <dbl> <dbl>
## 1 0.695 0.356 0.881Como se encontró un resultado significativo, es necesario indicar dónde se encuentran esas diferencias. Se va a usar la prueba de Dunn para ajustar el error tipo-I para todas las comparaciones. Se pueden usar usas las funciones dunn_test del paquete rstatix o DunnTest del paquete DescTools, donde los argumentos necesarios los datos y la fórmula que describe la variable con respecto a los grupos. Aquí se puede interpretar el valor-p ajustado con respecto al nivel de significancia escogido. En los resultados se observa que la única diferencia significativa es la de Mount Mica-Black Mountain, ya que el valor-p está por debajo del \(\alpha\).
dunn = dunn_test(dat.kw, MgO ~ Location) # rstatix
dunn## # A tibble: 3 x 9
## .y. group1 group2 n1 n2 statistic p p.adj p.adj.signif
## <chr> <chr> <chr> <int> <int> <dbl> <dbl> <dbl> <chr>
## 1 MgO Black Moun… Sebago Ba… 4 4 1.38 0.167 0.334 ns
## 2 MgO Black Moun… Mount Mica 4 4 2.77 0.00569 0.0171 *
## 3 MgO Sebago Bat… Mount Mica 4 4 1.38 0.167 0.334 nsDunnTest(MgO ~ Location,dat.kw) # DescTools##
## Dunn's test of multiple comparisons using rank sums : holm
##
## mean.rank.diff pval
## Sebago Batholith-Black Mountain 3.5 0.3336
## Mount Mica-Black Mountain 7.0 0.0171 *
## Mount Mica-Sebago Batholith 3.5 0.3336
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1Conclusión: El contenido de \(MgO\) difiere significativamente entre las localidades, \(Kruskal-Wallis \chi^2(2) = 7.65\), \(p = .022\), \(\eta^2_H = .63\), 95% IC \([.26, .85]\). El efecto se puede considerar grande, pero con un rango amplio. Análisis posteriores con Dunn indican que hay una diferencia entre Mount Mica - Black Mountain (\(p=.017\)), pero no así entre Mount Mica - Sebago Batholith (\(p=.334\)), ni Sebago Batholith - Black Mountain (\(p=.334\)).
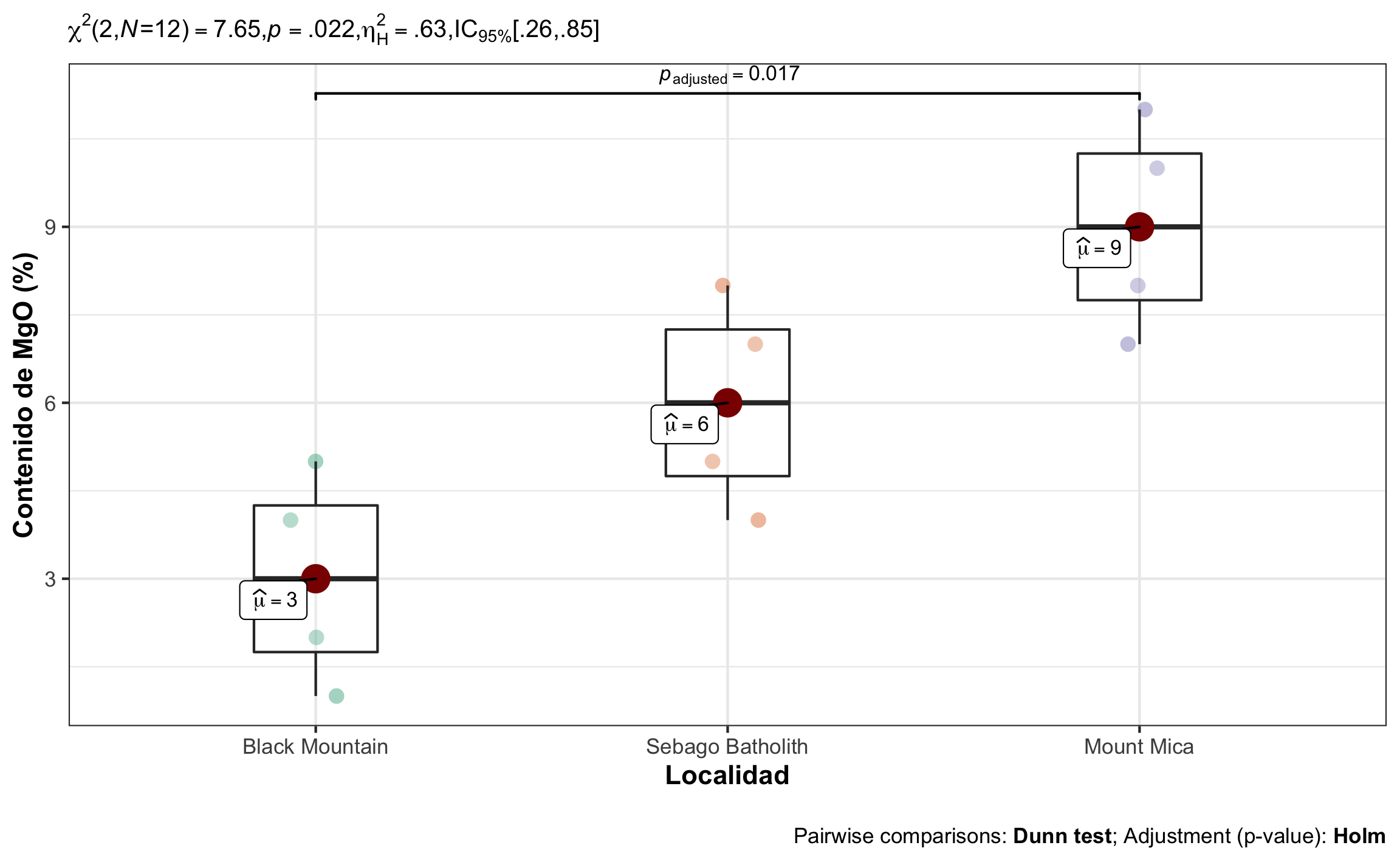
Figura 16.12: Gráfico de caja mostrando el efecto de localidad sobre el contenido de MgO, la comparación significativa, así como el resumen estadístico respectivo.
16.5.4 Correlación de Spearman
La correlación de Spearman es una modificación de la correlación de Pearson, donde el interés es la relación entre variables numéricas continuas. La correlación de Spearman tiene las ventajas sobre Pearson que se puede utilizar cuando la relación es no lineal, y no se ve tan afectada por valores extremos o atípicos. las hipótesis serían las siguientes:
- \(H_0: \rho_s = 0 \to\) No hay relación entre las variables,
- \(H_1: \rho_s \neq 0 \to\) Hay relación entre las variables.
El procedimiento de la prueba sería el siguiente:
- Ranquear cada variable por separado.
- Sacar las diferencias al cuadrado entre las observaciones ranqueadas.
- Calcular el coeficiente por medio de la Ecuación (16.1), o calcular el coeficiente de Pearson con los datos ranqueados.
- Se rechaza \(H_0\) si el \(r_s > \text{valor crítico}\) o si \(p < \alpha\).
El uso de la prueba de correlación de Spearman se realiza con un ejemplo de Swan & Sandilands (1995), donde se el tamaño de ostrácodos con respecto a la profundidad (Tabla 16.11). Hay una relación entre el paso del tiempo (mayor profundidad) y el tamaño de los ostrácodos? Asuma \(\alpha = .05\).
a = 0.05
ostracodos = tibble(prof = c(242,253,271,292,305,332,335,337,338,350,
357,364,365,371,372,385,401,402,410,412,
418,423,427,429,432,446,451,454,460,470,
474,481,497),
size = c(1.3,.9,.7,.8,.8,1.2,.9,1.1,1.6,1.6,1,
1.2,1.3,1.4,1.1,.9,1.3,1.5,1.8,1.6,1.2,
1.5,1.5,1.7,1.9,1.5,1.6,1.2,1.6,1.7,
1.8,1.8,1.3),
Rprof = rank(prof),
Rsize = rank(size),
Dif = (Rprof-Rsize)^2)| Profundidad (x) | Tamaño (y) | \(R_{x}\) | \(R_{y}\) | \((R_{x}-R_{y})^2\) |
|---|---|---|---|---|
| 242 | 1.3 | 1 | 15.5 | 210.25 |
| 253 | 0.9 | 2 | 5.0 | 9.00 |
| 271 | 0.7 | 3 | 1.0 | 4.00 |
| 292 | 0.8 | 4 | 2.5 | 2.25 |
| 305 | 0.8 | 5 | 2.5 | 6.25 |
| 332 | 1.2 | 6 | 11.5 | 30.25 |
| 335 | 0.9 | 7 | 5.0 | 4.00 |
| 337 | 1.1 | 8 | 8.5 | 0.25 |
| 338 | 1.6 | 9 | 25.0 | 256.00 |
| 350 | 1.6 | 10 | 25.0 | 225.00 |
| 357 | 1.0 | 11 | 7.0 | 16.00 |
| 364 | 1.2 | 12 | 11.5 | 0.25 |
| 365 | 1.3 | 13 | 15.5 | 6.25 |
| 371 | 1.4 | 14 | 18.0 | 16.00 |
| 372 | 1.1 | 15 | 8.5 | 42.25 |
| 385 | 0.9 | 16 | 5.0 | 121.00 |
| 401 | 1.3 | 17 | 15.5 | 2.25 |
| 402 | 1.5 | 18 | 20.5 | 6.25 |
| 410 | 1.8 | 19 | 31.0 | 144.00 |
| 412 | 1.6 | 20 | 25.0 | 25.00 |
| 418 | 1.2 | 21 | 11.5 | 90.25 |
| 423 | 1.5 | 22 | 20.5 | 2.25 |
| 427 | 1.5 | 23 | 20.5 | 6.25 |
| 429 | 1.7 | 24 | 28.5 | 20.25 |
| 432 | 1.9 | 25 | 33.0 | 64.00 |
| 446 | 1.5 | 26 | 20.5 | 30.25 |
| 451 | 1.6 | 27 | 25.0 | 4.00 |
| 454 | 1.2 | 28 | 11.5 | 272.25 |
| 460 | 1.6 | 29 | 25.0 | 16.00 |
| 470 | 1.7 | 30 | 28.5 | 2.25 |
| 474 | 1.8 | 31 | 31.0 | 0.00 |
| 481 | 1.8 | 32 | 31.0 | 1.00 |
| 497 | 1.3 | 33 | 15.5 | 306.25 |
La suma de las diferencias al cuadrado resulta en:
ostracodos %>%
summarise(Suma = sum(Dif))## # A tibble: 1 x 1
## Suma
## <dbl>
## 1 1942.\[\begin{equation} r_{s} = 1 - \frac{6\sum_i^N[R(x_i)-R(y_i)]^2}{N(N^2-1)}\\ r_{s} = 1 - \frac{6 \cdot 1941.5}{33(33^2-1)} = .675 \end{equation}\]
En R se tiene la función cor.test que puede calcular diferentes coeficientes de correlación. El argumento method define cuál correlación calcular. Se puede calcular spearman sobre los datos originales, pero éste no arroja un intervalo de confianza, o se puede calcular spearman sobre los datos ranqueados; la inferencia no cambia.
spearman.res = cor.test(~prof+size,ostracodos,method='spearman')
spearman.res##
## Spearman's rank correlation rho
##
## data: prof and size
## S = 1951.4, p-value = 1.715e-05
## alternative hypothesis: true rho is not equal to 0
## sample estimates:
## rho
## 0.6738982cor.test(~Rprof+Rsize,ostracodos,method='pearson')##
## Pearson's product-moment correlation
##
## data: Rprof and Rsize
## t = 5.0785, df = 31, p-value = 1.715e-05
## alternative hypothesis: true correlation is not equal to 0
## 95 percent confidence interval:
## 0.4300936 0.8260874
## sample estimates:
## cor
## 0.6738982Decisión: Se rechaza \(H_0\)
La significancia de la correlación también puede aproximarse por medio de las Ecuaciones (16.19) y (16.20), donde la primera es similar a la utilizada para la correlación de Pearson (el valor de \(t\) en la prueba de Pearson sobre los datos ranqueados, \(v=N-2\)), y la segunda es una aproximación a la distribución normal, especialmente cuando el tamaño de la muestra es grande.
\[\begin{equation} t = \frac{r_s \sqrt{v}}{\sqrt{1-r_s^2}} \tag{16.19} \end{equation}\]
\[\begin{equation} t = \frac{r_s \sqrt{v}}{\sqrt{1-r_s^2}} = \frac{0.675 \sqrt{31}}{\sqrt{1-0.675^2}} = 5.09 \end{equation}\]
\[\begin{equation} z = r_s\sqrt{N-1} \tag{16.20} \end{equation}\]
\[\begin{equation} z = r_s\sqrt{N-1} = 0.675\sqrt{33-1} = 3.82 \end{equation}\]
Al ser \(t\) mayor al valor crítico, \(t_{.05/2,31}=|2.04|\), y al ser \(z\) mayor al valor crítico, \(1.96\) para \(\alpha=.05\), se obtiene la misma decisión que con la prueba respectiva.
El intervalo de confianza puede calcularse por medio de la prueba de Pearson sobre datos ranqueados (mostrada arriba), o por medio de las funciones SpearmanRho del paquete DescTools, o spearmanRho del paquete rcompanion (por medio de bootstrap).
spearman.ci = with(ostracodos,SpearmanRho(prof,size,conf.level = 1-a))
spearman.ci## rho lwr.ci upr.ci
## 0.6738982 0.4300936 0.8260874set.seed(101)
spearmanRho(~prof+size,ostracodos,ci = T,conf = 1-a)## # A tibble: 1 x 3
## rho lower.ci upper.ci
## <dbl> <dbl> <dbl>
## 1 0.674 0.391 0.832Conclusión: La profundidad y el tamaño de los ostrácodos están significativa correlacionados, \(r_{\mathrm{s}} = .67\), 95% IC \([.43, .83]\), \(p < .001\). El tamaño del efecto es grande con un rango de medio hasta muy grande.
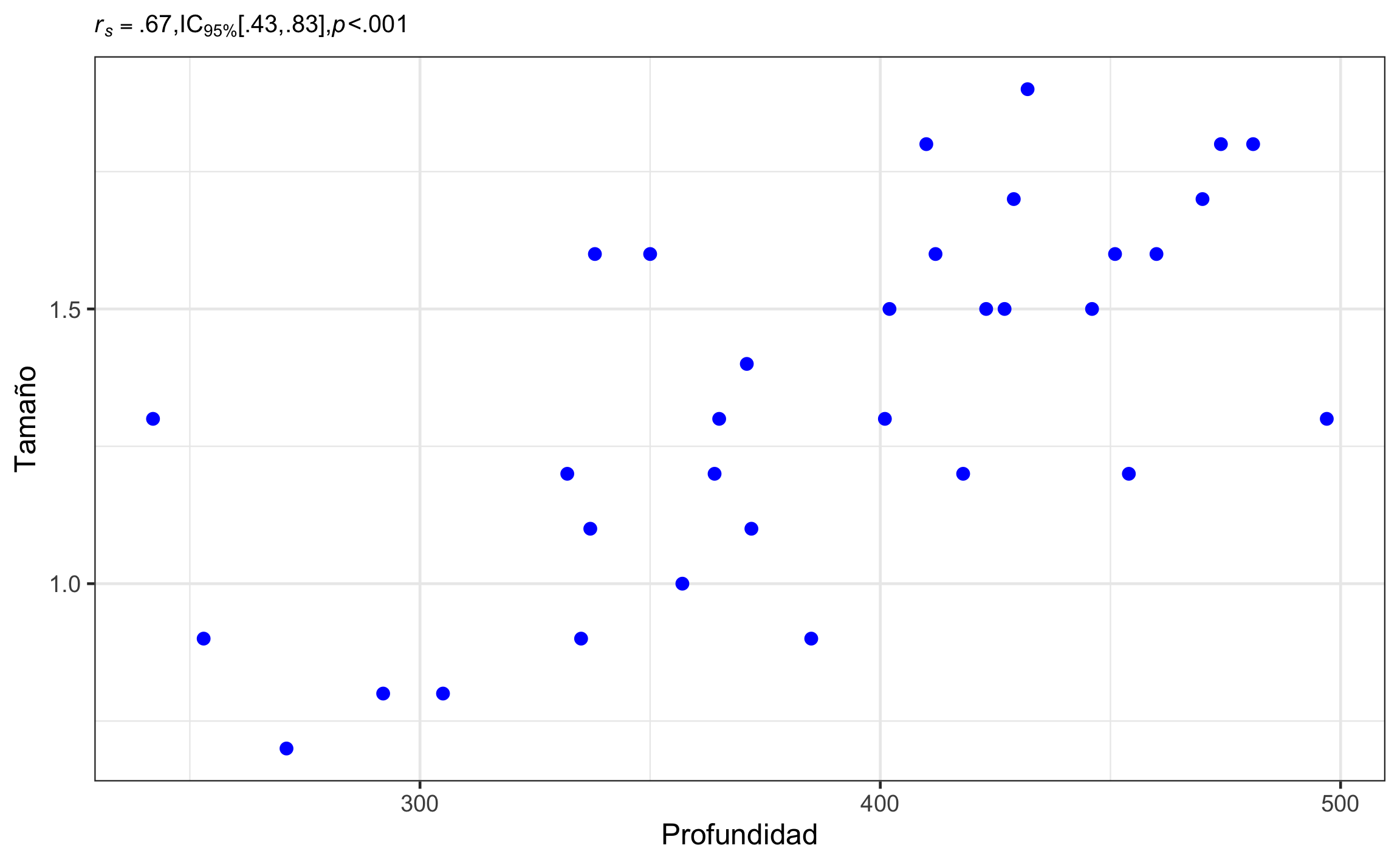
Figura 16.13: Gráfico de dispersión mostrando la relación entre tamaño y profundidad para los ostrácodos, así como el resumen estadístico respectivo.
La correlación de Spearman:
- No indica relación lineal.
- Simplemente indica que hay una relación (monotónica) entre las variables estudiadas.
- Es inusual que el resultado de un test estadístico para Pearson sea superior al de Spearman.
- En general se considera más robusto el coeficiente Spearman que el de Pearson, especialmente cuando hay valores atípicos.
16.6 Bootstrap (remuestreo)
Es una técnica de remuestreo (con reemplazamiento) de datos que permite resolver problemas relacionados con la estimación de intervalos de confianza o pruebas de significación estadística. El muestreo con reemplazamiento consiste en tomar una muestra del mismo tamaño de la muestra original, pero permitiendo que las observaciones puedan escogerse más de una vez; un ejemplo se muestra en la Tabla 16.12. Como esta técnica genera muestras aleatorias cada vez que se corre el análisis, es recomendado partir del mismo punto para cuestiones de reproducibilidad, por lo que se recomienda usar la función set.seed antes de cualquier remuestreo.
| Muestra original | Muestra 1 | Muestra 2 | Muestra 3 | Muestra 4 | Muestra 5 |
|---|---|---|---|---|---|
| 1 | 1 | 4 | 3 | 3 | 6 |
| 2 | 1 | 3 | 3 | 1 | 2 |
| 3 | 6 | 6 | 2 | 6 | 5 |
| 4 | 1 | 3 | 4 | 4 | 2 |
| 5 | 2 | 3 | 4 | 1 | 2 |
| 6 | 5 | 1 | 5 | 5 | 3 |
Si se tiene una muestra representativa de una población en interés, se puede esperar que muestrear la muestra sería homólogo a muestrear la población. Al repetir este proceso un montón de veces (muestrear con reemplazamiento) se pueden construir distribuciones del estadístico de interés (estimación por medio de intervalos de confianza) o distribuciones asumiendo que \(H_0\) es verdadera (pruebas de significación estadística). Esta técnica se muestra en la Figura 16.14 para el caso de estimación por medio de intervalos de confianza.
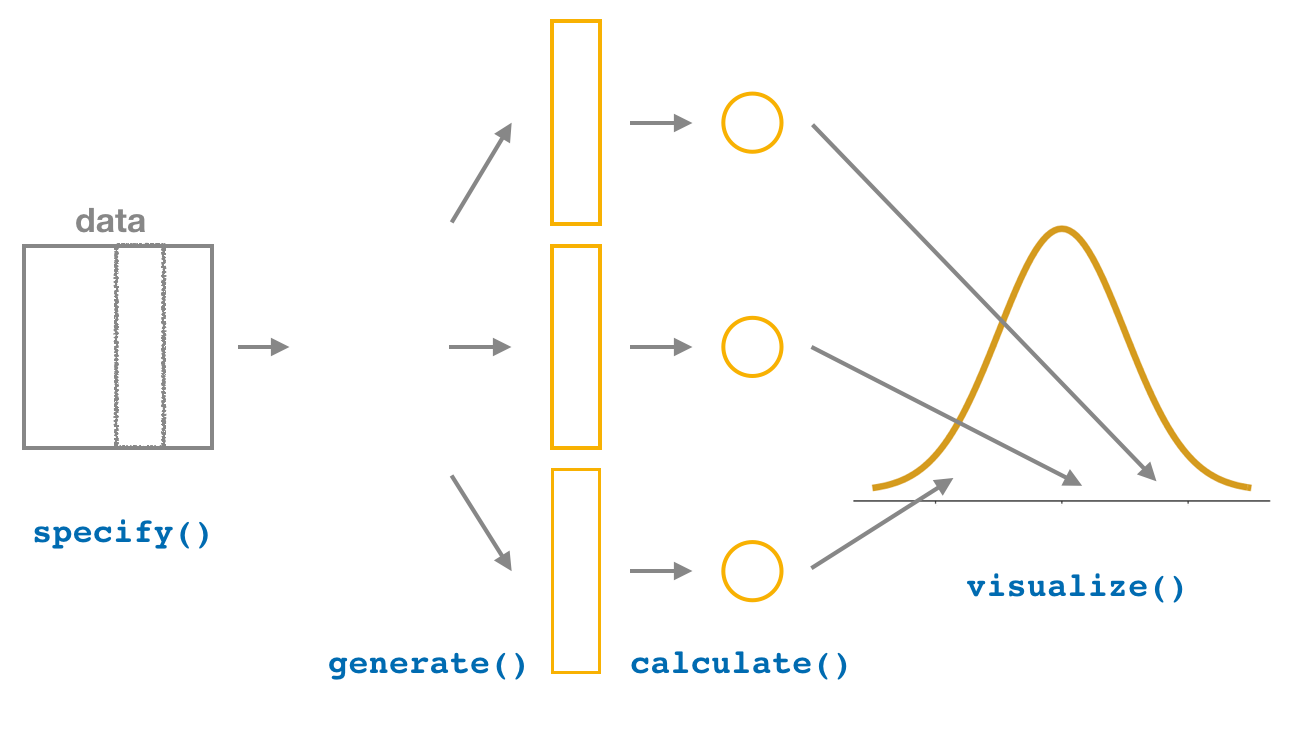
Figura 16.14: Proceso de bootstrap para estimar intervalos de confianza. Los nombres representan funciones del paquete infer, pero hacen referencia a los diferentes pasos en el proceso.
Existen diferentes funciones y paquetes que permiten permiten utilizar esta técnica, dentro de ellos están: boot (Canty & Ripley, 2019), infer (Bray et al., 2019), y rsample (Kuhn et al., 2019). Los paquetes y funcionalidad de boot y rsample son más generales ya que permiten al usuario definir qué se quiere calcular (lo que permite mayor flexibilidad y control), mientras que infer ya viene con opciones predefinidas de las cuales escoger y simplemente aplicar (mayor facilidad para aplicar pero poco flexible). Los paquetes infer y rsample siguen la metodología del tidyverse, por lo que son más congruentes con la manera en que se han venido mostrando y aplicando los conceptos y análisis en este libro; de hecho ambos paquetes son parte del meta-paquete tidymodels (Kuhn & Wickham, 2020) que permite aplicar técnicas de aprendizaje automático (machine learning) para diferentes problemas y con diferentes técnicas, de una manera uniforme y congruente.
16.6.1 infer
En esta sección se introduce de manera general el funcionamiento del paquete infer; para un mejor entendimiento se recomienda revisar las viñetas del paquete, que cubren todos los posibles análisis que puede correr. Como se mencionó anteriormente este paquete viene con funciones y una metodología predeterminada, lo que lo hace amigable de aprender pero a la hora de querer tener más control no es posible.
El flujo general se presentó en la Figura 16.14 y se resume a continuación:
specifiy: Se tiene que definir qué se quiere analizar, y dependiendo de ésto se especifica de diferentes formas.hypothesize: Se define cuando se quiere simular la distribución que representa a \(H_0\), depende del tipo de prueba.generate: Se generan la cantidad de replicas deseadas.calculate: Se escoge el estadístico a calcular, donde las opciones sonc("mean", "median", "sum", "sd", "prop", "count", "diff in means", "diff in medians", "diff in props", "Chisq", "F", "slope", "correlation", "t", "z")visualise: Grafica el resultado, ya sea la distribución del estadístico para estimación o para prueba estadística.
Existen otra serie de funciones que permiten obtener el intervalos de confianza, el valor-p, y agregar estos valores al gráfico resultante. En las siguientes secciones se presentan un par de casos reproduciendo ejemplos tratados en estimación y pruebas estadísticas, para poder comparar los resultados.
16.6.1.1 Estimación
Para el caso de estimación se presenta el ejemplo de la longitud de los braquiópodos en las capas A y B, donde se quiere estimar si las medias se pueden considerar iguales.
Los pasos son los siguientes:
specifiy: Se puede especificar de dos formas: por medio de fórmula (response ~ explanatory) como se ha trabajado en las diferentes pruebas presentadas, o definir las variables por separado. En este caso la variable respuesta (dependiente) es la longitud (values en el dataframe) y la variable explanatoria (independiente) es la variable agrupadora (ind en el dataframe).hypothesize: No se usa por ser un problema de estimación.generate: Se generan 1000 replicas.calculate: Lo que se quiere estimar es la diferencia de medias ('diff in means'), y por ser éste el caso es necesario definir el orden (order) de la diferencia, donde se realizaprimero - segundo.
Este proceso genera el remuestreo con el estadístico (stat) deseado. A partir de estos datos se puede: obtener el intervalo de confianza (get_ci), visualizar la distribución del estadístico (diferencia de medias) y sobreponerle el intervalo de confianza (Figura 16.15).
set.seed(101)
a = .05
boots = braq %>%
specify(response = values, explanatory = ind) %>%
generate(reps = 1000) %>%
calculate(stat = 'diff in means', order = c('A','B'))
boots## # A tibble: 1,000 x 2
## replicate stat
## <int> <dbl>
## 1 1 0.122
## 2 2 0.0556
## 3 3 0.0892
## 4 4 0.195
## 5 5 0.217
## 6 6 0.233
## 7 7 0.0167
## 8 8 0.245
## 9 9 0.0500
## 10 10 0.0889
## # … with 990 more rowsboots %>%
summarise(mean_dif = mean(stat))## # A tibble: 1 x 1
## mean_dif
## <dbl>
## 1 0.163boots_ci = boots %>%
get_ci(level = 1-a)
boots_ci## # A tibble: 1 x 2
## `2.5%` `97.5%`
## <dbl> <dbl>
## 1 -0.00312 0.348boots %>%
visualise() +
shade_ci(endpoints = boots_ci)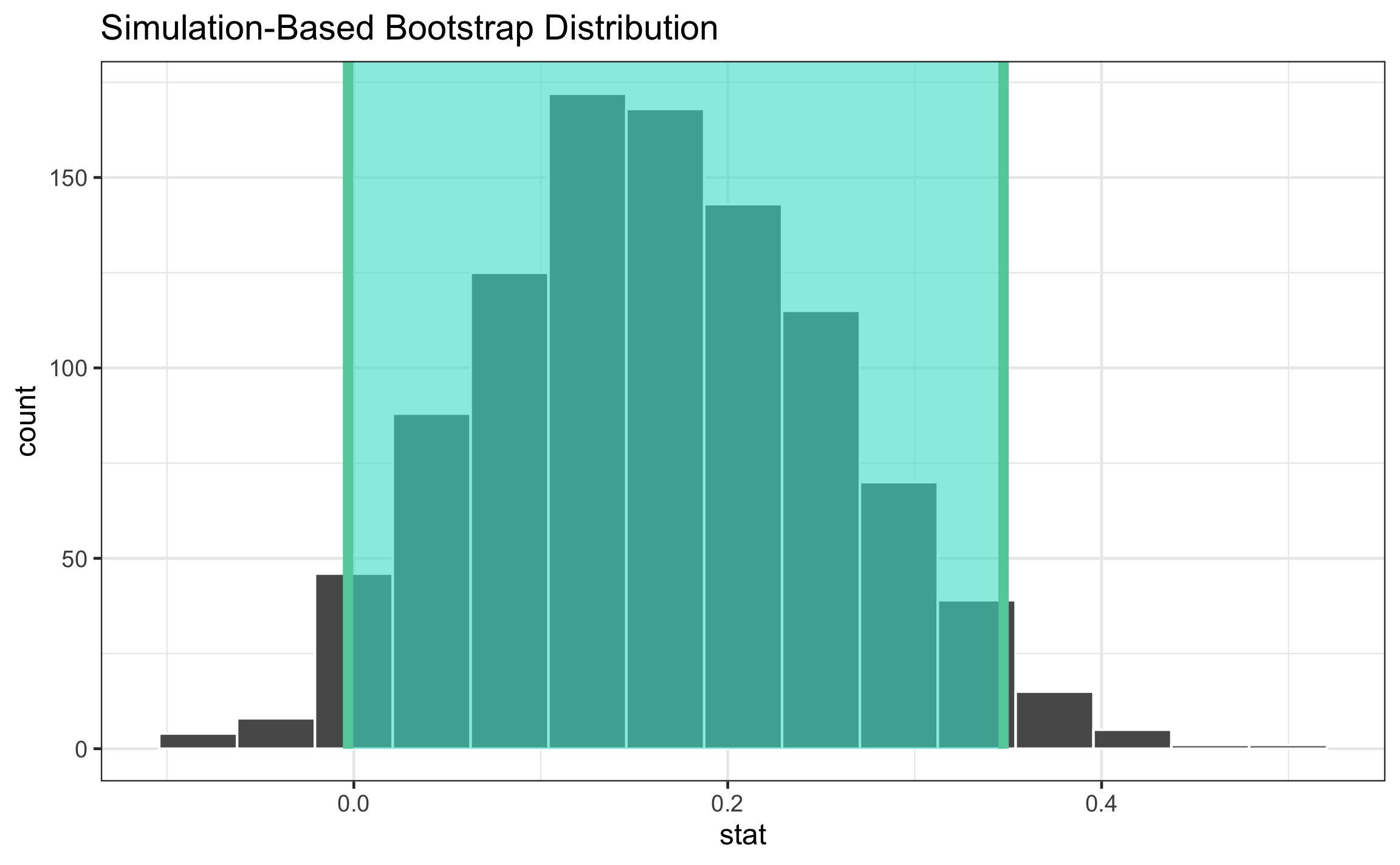
Figura 16.15: Distibución de diferencia de medias para la longitud de braquiópodos en dos capas diferentes.
El resultado muestra que el intervalo de confianza incluye a 0 (por muy poco), por lo que es un valor probable para la diferencia de la longitud de los braquiópodos en las dos capas, pudiendo considerar semejantes. Este resultado no difiere mucho del obtenido por medio de la respectiva prueba estadística.
16.6.1.2 Prueba estadística
El poder realizar simulaciones para problemas donde no hay posibilidad de estimar intervalos de confianza es muy útil, ya que permite validar o suplantar el proceso de una prueba estadística y obtener resultados representativos.
Para el caso de la prueba estadística se presenta el ejemplo del nivel de contaminación para pozos en diferentes localidades, donde se quiere estimar si el nivel de contaminación es similar (homogéneo) en la diferentes localidades.
Los pasos son los siguientes:
specifiy: Se puede especificar de dos formas: por medio de fórmula (response ~ explanatory) como se ha trabajado en las diferentes pruebas presentadas, o definir las variables por separado. En este caso se usa la fórmula y la variable respuesta (dependiente) es el nivel e contaminación y la variable explanatoria (independiente) es la localidad.hypothesize: Por ser una prueba de dos variables la hipótesis es que no hay efecto de la variable explanatoria sobre la respuesta, o que son independientes. Si se tratara de una variable, se tienen que definir otros argumentos dependiendo del tipo de prueba.generate: Se generan 1000 replicas.calculate: Lo que se quiere estimar es la distribución de \(\chi^2\) ('Chisq').
Este proceso genera el remuestreo con el estadístico (stat) deseado. A partir de estos datos se puede: obtener el valor-p (get_p_value), visualizar la distribución del estadístico (\(\chi^2\)) y sobreponerle el área de rechazo a partir del valor-p (Figura 16.16).
obs_chisq <- pozos %>%
specify(Contaminado ~ Localidad) %>%
calculate(stat = "Chisq")
obs_chisq## # A tibble: 1 x 1
## stat
## <dbl>
## 1 5.25set.seed(101)
chisq_null <- pozos %>%
specify(Contaminado ~ Localidad) %>%
hypothesize(null = "independence") %>%
generate(reps = 1000) %>%
calculate(stat = "Chisq")
chisq_null %>%
get_p_value(obs_stat = obs_chisq, direction = "greater")## # A tibble: 1 x 1
## p_value
## <dbl>
## 1 0.098chisq_null %>%
visualize() +
shade_p_value(obs_stat = obs_chisq, direction = "greater")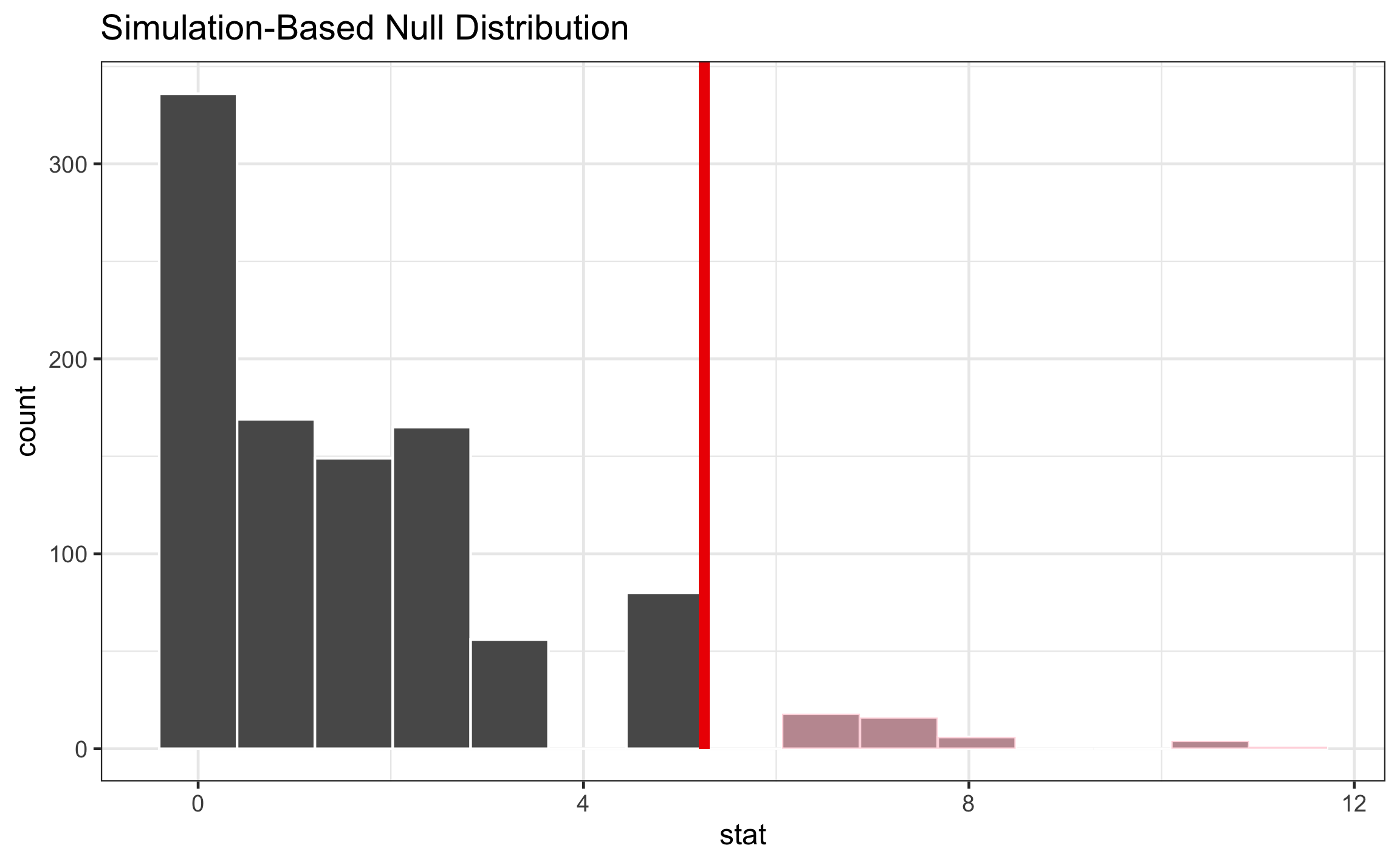
Figura 16.16: Distibución de \(\chi^2\) para el nivel de contaminación por localidad.
El resultado muestra que el valor-p está por encima del nivel de significancia, por lo que no se rechaza que el nivel de contaminación sea similar en las diferentes localidades. Este resultado no difiere mucho del obtenido por medio de la respectiva prueba estadística.
De nuevo, aquí se presentaron un par de ejemplo para introducir el uso de este paquete y las opciones que permite, para otras pruebas o estimaciones se recomienda revisar la documentación del paquete.
16.6.2 rsample
En esta sección se introduce de manera general el funcionamiento del paquete rsample. La funcionalidad de este paquete es más general ya que el usuario tiene que definir el estadístico o valor a muestrear, lo que implica cierta complejidad pero a su vez mayor flexibilidad. Otra ventaja, sobre infer, es que permite realizar un muestreo estratificado, lo que mantiene la cantidad de observaciones presentes en los diferentes grupos, respetando las condiciones de muestreo original y controlando que no se generen muestreos desbalanceados.
Los pasos generales son los siguientes:
- Generar el remuestreo con
bootstraps, donde se ocupa un dataframe, el número de replicas, y aquí se puede definir la variable estratificadora (strata) de ser necesario. Esto genera un tibble con las variablessplitsyid, dondesplitscontiene el dataframe remuestreado (datos paraanalysis), que es sobre el cual se quiere realizar el análisis, y además guarda las observaciones que no se muestrearon (datos paraassessment). - Definir una o varias funciones a aplicar sobre los
splits. Aquí es donde el usuario tiene toda la flexibilidad y control sobre el análisis, y es lo que a su vez implica mayor complejidad por el hecho de tener que definir/crear funciones propias. - Agregar variables (
mutate) al tibble generado en el primer paso por medio de la iteración (usando funcionesmapdel paquete purrr (Henry & Wickham, 2020)) sobre lossplitscon la(s) función(es) definida(s) en el segundo paso. El tipo de variable puede ser cualquier tipo de objeto dada la flexibilidad de los tibbles. - Con el tibble actualizado se puede(n) analizar la(s) variable(s) agregadas en el paso tres, ya sea por medio de estimación de intervalos de confianza, visualización de las distribuciones, o tareas más complejas dependiendo de la(s) variable(s) generada(s).
16.6.2.1 Estimación
Como ejemplo para estimación se usa el ejemplo del contenido de cuarzo de una roca ígnea.
- Se convierte el vector en un tibble y se especifican 1000 remuestreos.
- Se generan las funciones
avgydpara calcular la media y el tamaño del efecto para cada remuestreo. - Se agregan las variables
avgydal tibble original por medio de la funciónmap_dbl, ya que el resultado de ambas funciones es un número con decimales.
mu = 20
a = .05
n = length(cuarzo)
set.seed(101)
m = bootstraps(data = tibble(cuarzo), times = 1000)
avg = function(split) {
split %>%
analysis() %>%
pull(1) %>%
mean()
}
d = function(split) {
vec = split %>%
analysis() %>%
pull(1)
d = (mean(vec) - mu) / sd(vec)
return(d)
}
# avg2 = as_mapper(~ .x %>% analysis %>% pull(1) %>% mean)
# avg3 = compose(mean, partial(pull, var=1), analysis)
m = m %>%
mutate(avg = map_dbl(splits, ~avg(.)),
d = map_dbl(splits, ~d(.)),
)
m## # A tibble: 1,000 x 4
## splits id avg d
## <list> <chr> <dbl> <dbl>
## 1 <split [8/4]> Bootstrap0001 21.5 0.655
## 2 <split [8/3]> Bootstrap0002 23.3 1.22
## 3 <split [8/2]> Bootstrap0003 21.9 0.548
## 4 <split [8/2]> Bootstrap0004 21.7 0.704
## 5 <split [8/3]> Bootstrap0005 21.3 0.369
## 6 <split [8/4]> Bootstrap0006 19.4 -0.234
## 7 <split [8/4]> Bootstrap0007 22.5 1.16
## 8 <split [8/4]> Bootstrap0008 20.6 0.154
## 9 <split [8/2]> Bootstrap0009 20.8 0.237
## 10 <split [8/2]> Bootstrap0010 20.5 0.189
## # … with 990 more rowsUna vez generado y actualizado el tibble se calculan estadísticas para las variables generadas (q1 y q3 representan los límites inferior y superior del intervalo de confianza), y se visualizan las mismas por medio de histogramas mostrando el intervalo de confianza (Figuras 16.17 y 16.18).
m.s = m %>%
summarise_if(is.numeric,
.funs = list(~mean(.),
~sd(.),
q1=~quantile(.,a/2),
q2=~quantile(.,.5),
q3=~quantile(.,1-a/2)))
m.s %>%
pivot_longer(cols = everything(),
names_to = c('param','stat'),
names_sep = '_',
values_to = 'value') %>%
arrange(param)## # A tibble: 10 x 3
## param stat value
## <chr> <chr> <dbl>
## 1 avg mean 21.5
## 2 avg sd 0.993
## 3 avg q1 19.4
## 4 avg q2 21.4
## 5 avg q3 23.3
## 6 d mean 0.553
## 7 d sd 0.447
## 8 d q1 -0.209
## 9 d q2 0.498
## 10 d q3 1.53myvar = 'avg' # variable a graficar: avg, d
ggplot(m, aes(get(myvar))) +
geom_histogram(bins = 20, col = 'black', fill = 'grey80') +
geom_vline(xintercept = unlist(m.s %>% select(starts_with(str_glue('{myvar}_q')))),
col = c('blue','red','blue')) +
labs(x = 'Contenido de cuarzo (%)',
y = '')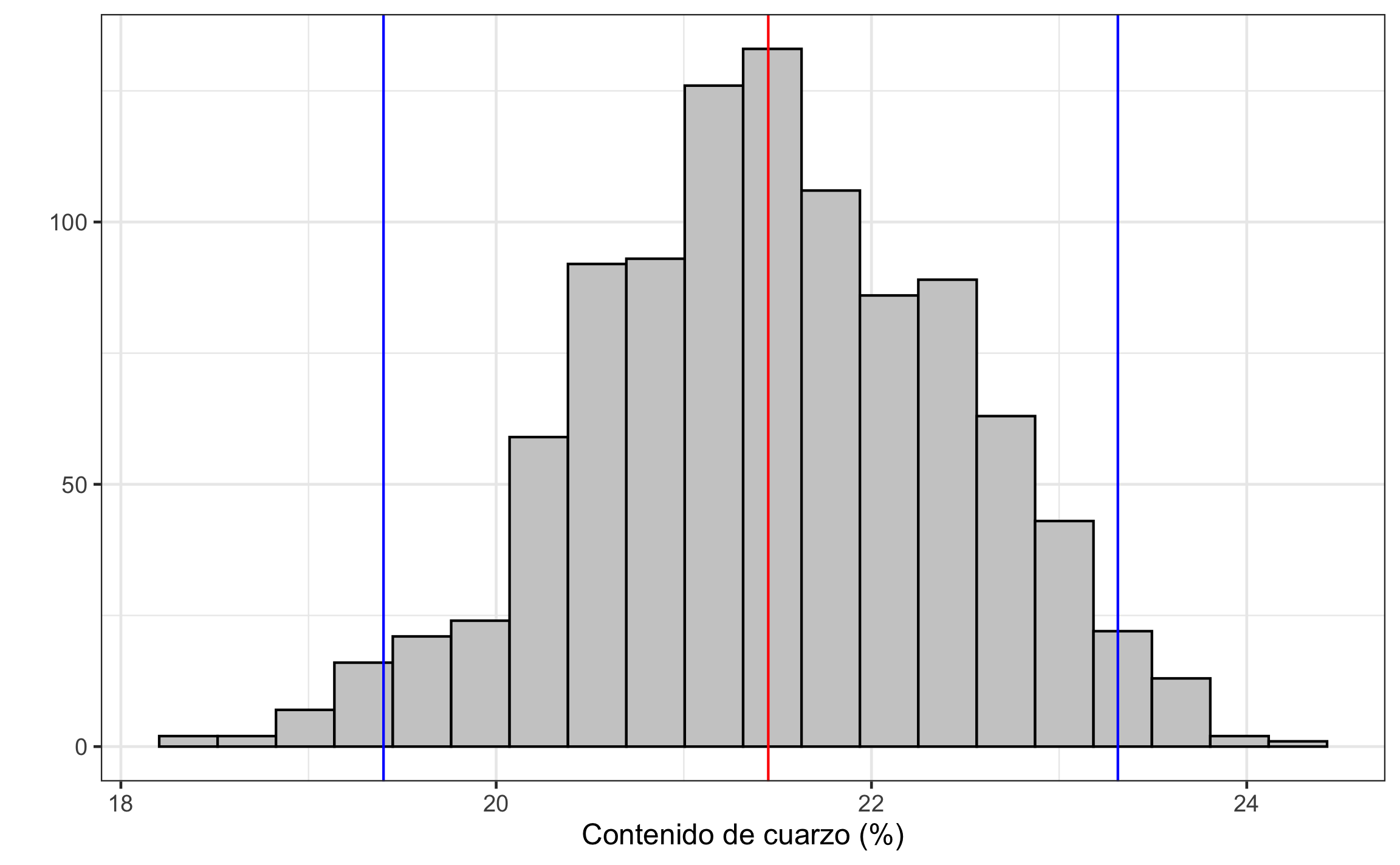
Figura 16.17: Distibución de medias para el contenido de cuarzo de una roca ígnea, mostrando la media y el intervalo de confianza.
myvar = 'd' # variable a graficar: avg, d
ggplot(m, aes(get(myvar))) +
geom_histogram(bins = 20, col = 'black', fill = 'grey80') +
geom_vline(xintercept = unlist(m.s %>% select(starts_with(str_glue('{myvar}_q')))),
col = c('blue','red','blue')) +
labs(x = TeX('Tamaño del efecto (\\mathit{Cohen d})
para el contenido de cuarzo'),
y = '')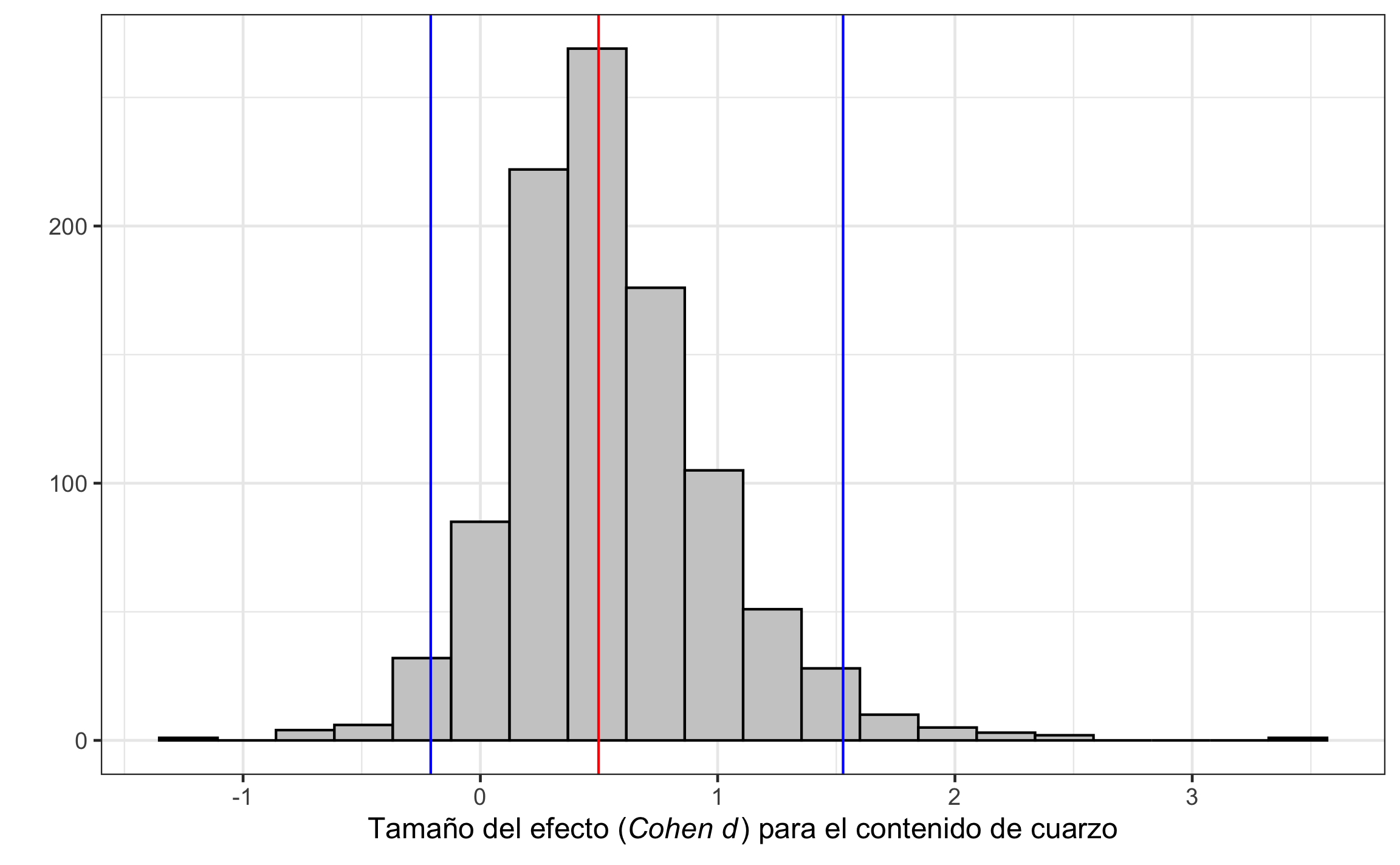
Figura 16.18: Distibución de tamaño del efecto (\(d\)) para el contenido de cuarzo de una roca ígnea, mostrando la media y el intervalo de confianza.
Con los resultados se puede concluir que el contenido de cuarzo no difiere significativamente del valor propuesto, ya que se encuentra dentro del intervalo de confianza. El tamaño del efecto es mediano, pero con un rango muy amplio desde pequeño en la dirección opuesta hasta muy grande. Este resultado no difiere mucho del obtenido por medio de la respectiva prueba estadística.
Aquí se introdujo muy brevemente la aplicabilidad del paquete rsample para usar la técnica de bootstrap. Este paquete, en conjunto con otros del tidyverse, son una herramienta muy potente para poder realizar diversidad de análisis desde simples hasta complejos.
Referencias
Agresti, A. (2007). An Introduction to Categorical Data Analysis (2.ª ed.). John Wiley & Sons.
Borradaile, G. J. (2003). Statistics of Earth Science Data: Their Distribution in Time, Space and Orientation. Springer-Verlag Berlin Heidelberg.
Bray, A., Ismay, C., Chasnovski, E., Baumer, B., & Cetinkaya-Rundel, M. (2019). infer: Tidy Statistical Inference. https://CRAN.R-project.org/package=infer
Buchanan, E. M., Gillenwaters, A. M., Scofield, J. E., & Valentine, K. D. (2019). MOTE: Effect Size and Confidence Interval Calculator. https://CRAN.R-project.org/package=MOTE
Canty, A., & Ripley, B. (2019). boot: Bootstrap Functions (Originally by Angelo Canty for S). https://CRAN.R-project.org/package=boot
Cohen, J. (1988). Statistical Power Analysis for the Behavioral Sciences (2.ª ed.). Erlbaum.
Field, A., Miles, J., & Field, Z. (2012). Discovering Statistics Using R. SAGE Publications Ltd.
Fritz, C. O., Morris, P. E., & Richler, J. J. (2012). Effect size estimates: Current use, calculations, and interpretation. Journal of Experimental Psychology: General, 141(1), 2-18. https://doi.org/10.1037/a0024338
Henry, L., & Wickham, H. (2020). purrr: Functional Programming Tools. https://CRAN.R-project.org/package=purrr
Kassambara, A. (2020). rstatix: Pipe-Friendly Framework for Basic Statistical Tests. https://CRAN.R-project.org/package=rstatix
Kuhn, M., Chow, F., & Wickham, H. (2019). rsample: General Resampling Infrastructure. https://CRAN.R-project.org/package=rsample
Kuhn, M., & Wickham, H. (2020). tidymodels: Easily Install and Load the ’Tidymodels’ Packages. https://CRAN.R-project.org/package=tidymodels
Mangiafico, S. (2020). rcompanion: Functions to Support Extension Education Program Evaluation. https://CRAN.R-project.org/package=rcompanion
McKillup, S., & Darby Dyar, M. (2010). Geostatistics Explained: An Introductory Guide for Earth Scientists. Cambridge University Press. www.cambridge.org/9780521763226
Meyer, D., Zeileis, A., & Hornik, K. (2017). vcd: Visualizing Categorical Data. https://CRAN.R-project.org/package=vcd
Nolan, S. A., & Heinzen, T. E. (2014). Statistics for the Behavioral Sciences (3.ª ed.). Worth Publishers.
Sheskin, D. J. (2011). Handbook of Parametric and Nonparametric Statistical Procedures (5.ª ed.). CRC Press.
Signorell, A. (2020). DescTools: Tools for Descriptive Statistics. https://CRAN.R-project.org/package=DescTools
Swan, A., & Sandilands, M. (1995). Introduction to Geological Data Analysis. Blackwell Science.
Tomczak, M., & Tomczak, E. (2014). The need to report effect size estimates revisited. An overview of some recommended measures of effect size. Trends in Sport Sciences, 1(21), 19-25.
Walpole, R. E., Myers, R. H., & Myers, S. L. (2012). Probabilidad y Estadística Para Ingeniería y Ciencias. Pearson.