Capítulo 10 Estadística Descriptiva Bivariable
10.1 Introducción
En el capítulo anterior (Estadística Descriptiva Univariable) se enfocó en analizar una variable por separado, sin considerar otra(s) variable(s) que pudiera(n) estar relacionada(s). A veces ese puede ser el enfoque de un análisis o estudio, pero en la mayoría de los casos, muy probablemente, se cuenta con más de una variable y esa(s) variable(s) puede(n) ser importante(s), ya sea para efectos de simple correlación o para efectos de predicción. Esta relación entre dos variables es el enfoque de este capítulo.
De manera general se pueden mencionar tres formas de analizar una variable con respecto a otra: Covarianza (lineal), Correlación (lineal), y Regresión (lineal, no lineal).
10.2 Covarianza
El objetivo de la covarianza (Ecuación (10.1)) es determinar si hay o no asociación entre 2 variables continuas, y si la hay cómo se comporta una con respecto a la otra, siempre que la relación entre las variables sea lineal. Es el homologo a la varianza pero para dos variables. Ésta puede ser positiva cuando una aumenta conforme la otra aumenta, o negativa cuando una aumenta conforme la otra disminuye.
\[\begin{equation} s_{xy} = \frac{\sum_{i=1}^{N}(x_i - \bar{x})(y_i - \bar{y})}{N-1} \tag{10.1} \end{equation}\]
donde \(\bar{x}\) es la media de la variable \(x\) y \(\bar{y}\) es la media de la variable \(y\).
Similar a la varianza de una variable, el valor de la covarianza va a depender de la escala de las variables, por lo que NO es ideal para comparar la magnitud de la relación entre las variables. Esta idea se puede demostrar en la Figura 10.1, donde se muestra que aunque los datos tengan tienen una correlación perfecta, la covarianza va a cambiar de acuerdo a la cantidad y escala de los datos.
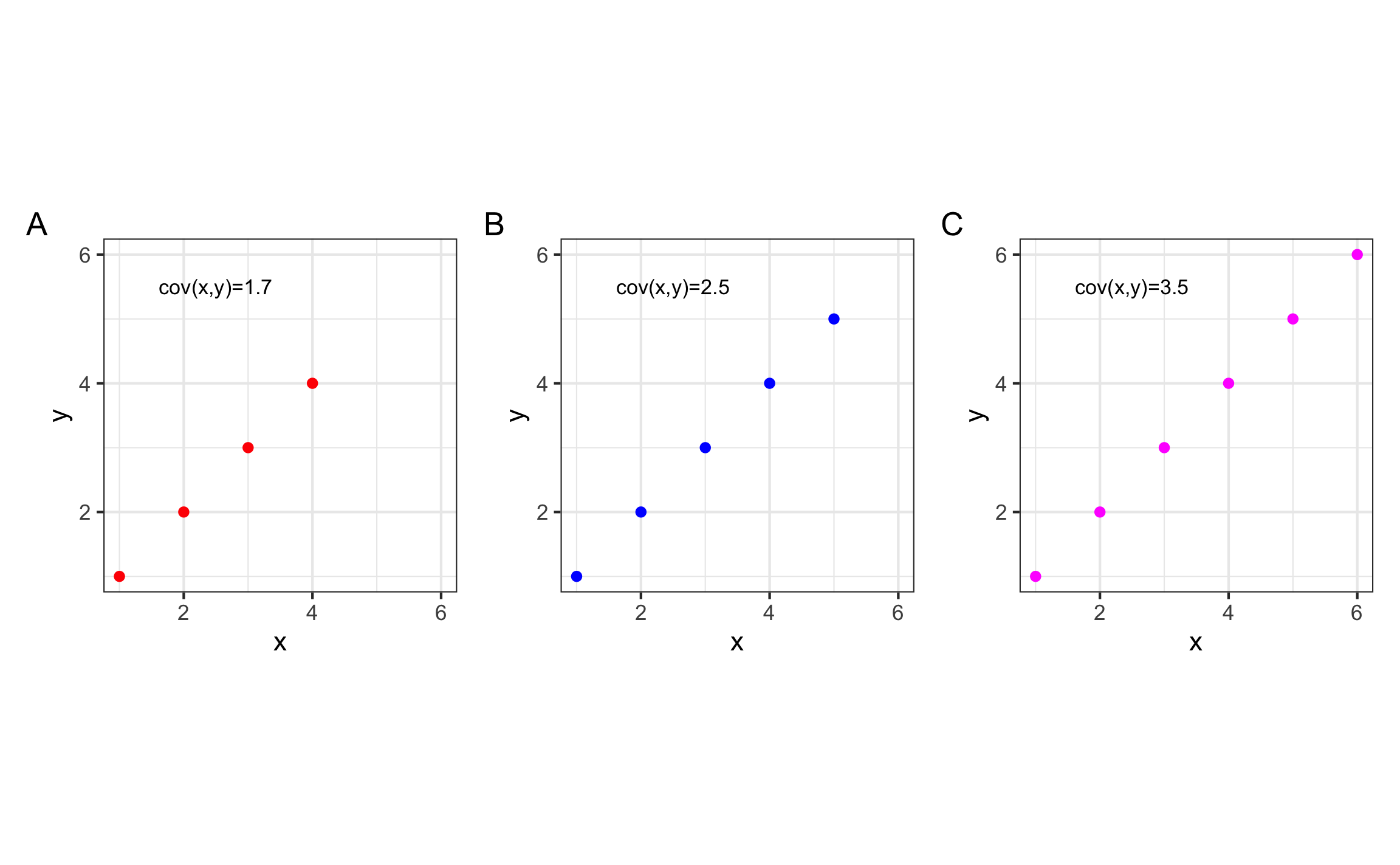
Figura 10.1: Visualización de la covarianza para diferentes datos donde se tiene una correlación perfecta pero la varianza cambia de acuerdo a la escala y cantidad de los datos.
En R la función para la covarianza es cov. Si se le pasan dos vectores el resultado es un único valor, pero si se le pasa una matriz o tabla con diferentes variables numéricas el resultado es una matriz de varianza-covarianza.
set.seed(101)
vec1 = rnorm(n = 30, mean = 40, sd = 5)
vec2 = rnorm(n = 30, mean = 20, sd = 3)
cov(vec1,vec2)## [1] 0.2220198cov(tibble(vec1,vec2))## vec1 vec2
## vec1 17.4519551 0.2220198
## vec2 0.2220198 9.4703668cov(rock)## area peri shape perm
## area 7203044.71232 3160367.49330 -40.820823047 -466063.55213
## peri 3160367.49330 2049653.68934 -51.775231267 -463032.47715
## shape -40.82082 -51.77523 0.006971657 20.35164
## perm -466063.55213 -463032.47715 20.351635275 191684.79915Del resultado de la matriz de covarianza se observa cómo la escala de las variables afecta el valor de la varianza-covarianza. La diagonal de la matriz es la varianza de la variable respectiva, y las entradas fuera de la diagonal son las covarianzas entre las diferentes variables.
10.3 Correlación
El objetivo de la correlación de Pearson (Ecuación (10.2)) es determinar la magnitud de la asociación entre dos variables cuantitativas continuas que tengan una relación lineal. En el caso de que la relación entre las variables no sea lineal se pueden utilizar los coeficientes de correlación de Spearman o Kendall, los cuales son homólogos no-paramétricos que se cubrirán en el capítulo de Estadística No Paramétrica.
\[\begin{equation} r = \frac{s_{xy}}{s_{x}s_{y}} \tag{10.2} \end{equation}\]
donde \(s_{xy}\) es la covarianza entre las variables, \(s_{x}\) es la desviación estándar de la variable \(x\), y \(s_{y}\) es la desviación estándar de la variable \(y\).
El coeficiente de correlación corresponde con una medida estandarizada ya que tiene la propiedad de que va a estar entre -1 y 1, sin importar la escala y rango de las variables originales (Figura 10.2). Como todas las medidas que dependen de la media, el coeficiente de correlación de Pearson se va a ver afectado por valores extremos (atípicos) y en este caso por la linealidad o no de la relación (Figura 10.3).
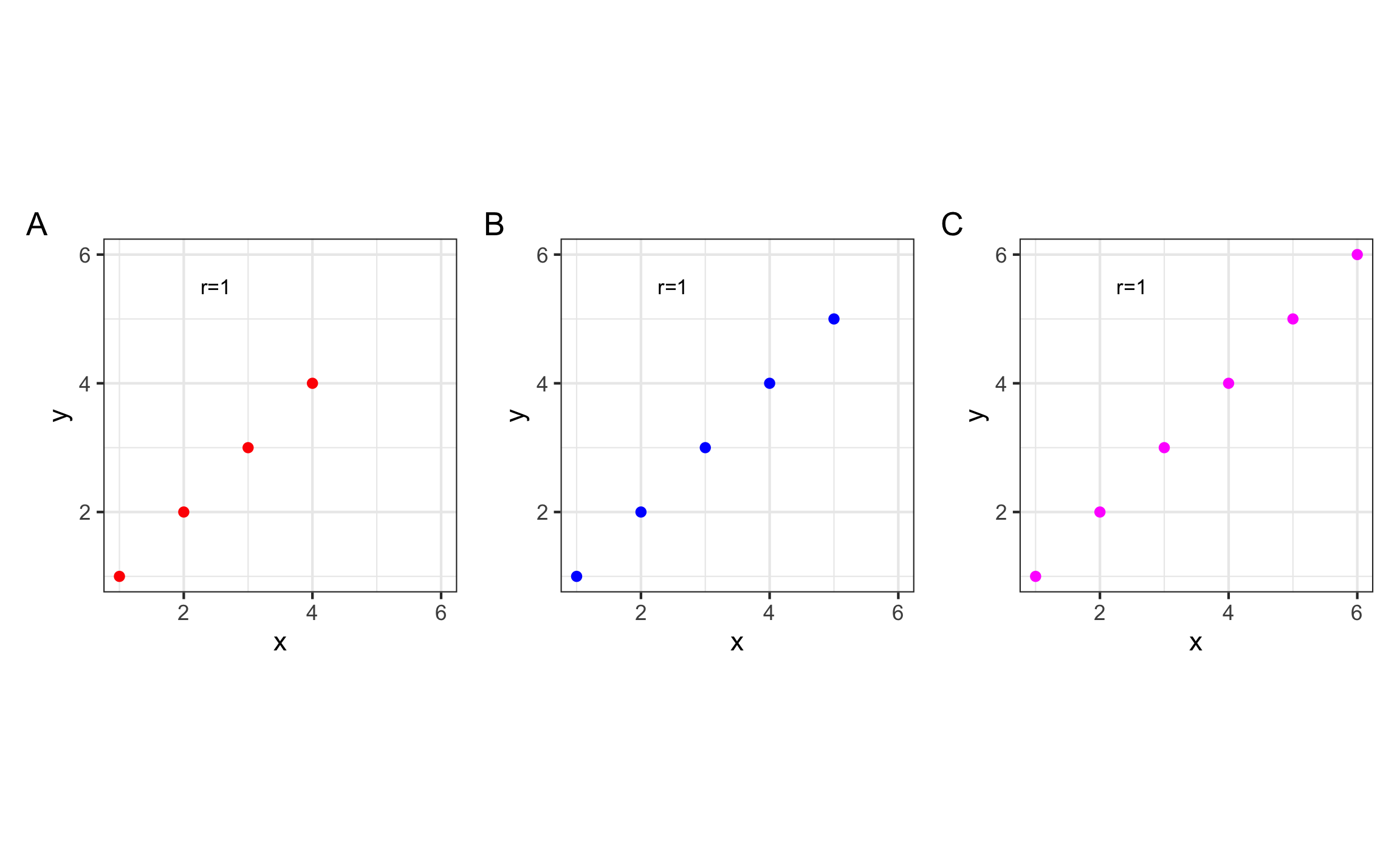
Figura 10.2: Visualización de coeficiente de correlación de Pearson, con los datos de la figura enterior.
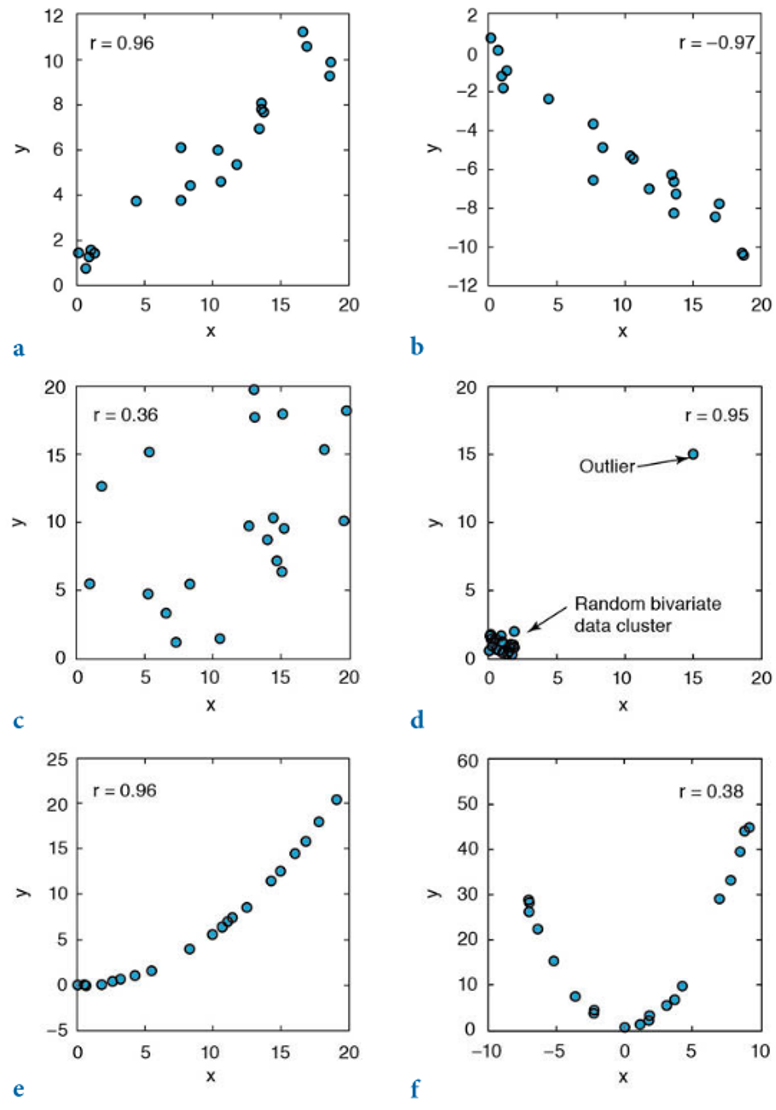
Figura 10.3: Ejemplos de la correlación de Pearson y cómo se ve afectado en casos de presencia de valores atípicos (d) y de no linealidad (e, f), estos últimos 3 siendo casos donde no es válido o apropiado usar este coeficiente de correlación (Trauth, 2015).
En R la función para calcular el coeficiente de correlación es cor, donde por defecto estima la correlación de Pearson. de manera similar a la covarianza, si se le pasan dos vectores el resultado es un único valor, pero si se le pasa una matriz o tabla el resultado es una matriz de correlaciones.
cor(vec1,vec2)## [1] 0.01726976cor(tibble(vec1,vec2))## vec1 vec2
## vec1 1.00000000 0.01726976
## vec2 0.01726976 1.00000000cor(rock)## area peri shape perm
## area 1.0000000 0.8225064 -0.1821611 -0.3966370
## peri 0.8225064 1.0000000 -0.4331255 -0.7387158
## shape -0.1821611 -0.4331255 1.0000000 0.5567208
## perm -0.3966370 -0.7387158 0.5567208 1.0000000En los resultados se puede ahora sí estimar la magnitud de las relaciones, donde valores cercanos a 1 y -1 indican una asociación mayor y valores cercanos a 0 indican poca o nula asociación. Más delante en el capítulo de Pruebas Estadísticas se podrá determinar si la correlación es nula o no.
10.4 Regresión
A diferencia de la correlación donde se busca únicamente establecer la presencia y magnitud de las asociación entre variables, sin importar el orden, la regresión pretende establecer la dependencia de una variable con respecto a otra(s), con el fin de predecir dicha variable y/o entender su relación, ya sea porque es difícil de medir o porque se asume y/o conoce la dependencia de otra variables.
De manera general la regresión es el ajuste de un modelo matemático a los datos observados, Ecuación (10.3).
\[\begin{equation} y = f \left( x; \beta \right) + \epsilon \tag{10.3} \end{equation}\]
donde \(f \left( x; \beta \right)\) es el modelo de ajuste definido por el analista, \(\beta\) son los parámetros desconocidos a estimar, y \(\epsilon\) es el error del ajuste.
10.4.1 Nomenclatura
En el ámbito de modelos de regresión se manejan diferentes nombres para las partes del modelo.
- Variable dependiente o respuesta: Es la variable que se pretende predecir, lo que comúnmente se conoce como \(y\).
- Variable independiente o predictor: El o las variables que se van a utilizar para predecir la variable respuesta, lo que comúnmente se conoce como \(x\).
- Coeficiente: El valor estimado del efecto de la variable independiente sobre la dependiente, \(\beta\) en la ecuación del modelo estimado.
10.4.2 Supuestos
De manera general los modelos de regresión deben cumplir ciertos supuestos para poder considerarlos como válidos. Para eso se pueden usar lo que se denominan gráficos diagnóstico. Entre los supuestos están:
- Linealidad: No se refiere la linealidad de los datos originales sino a la relación entre los valores residuales y los valores ajustados (Figura 10.4), donde lo ideal es que no se observen fuertes desviaciones ni tendencias entre estos valores.
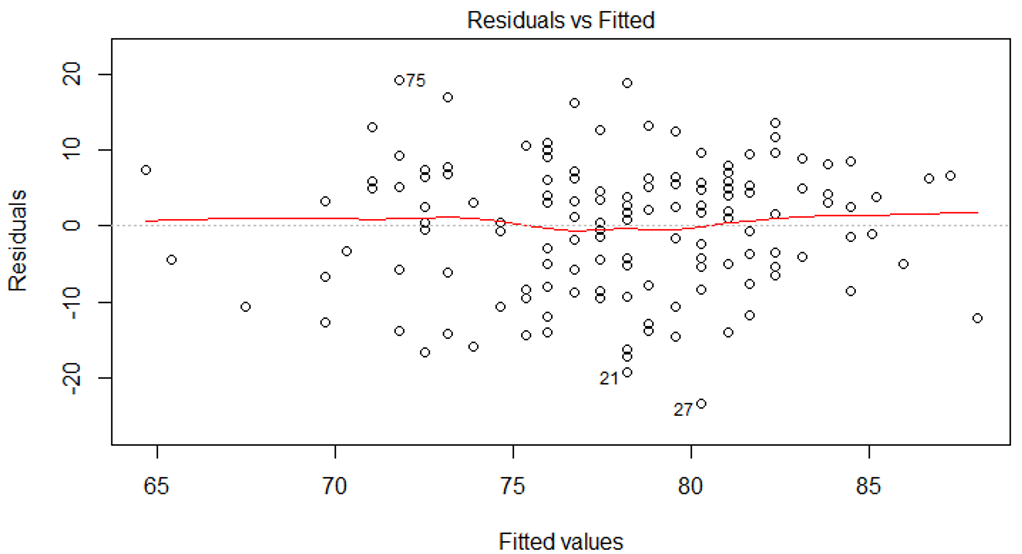
Figura 10.4: Supuesto de linealidad para un modelo de regresión. Lo ideal es que no se observen fuertes desviaciones ni tendencias.
- Normalidad: No se refiere la normalidad de los datos originales sino a la normalidad de los residuales, donde lo ideal es que estos residuales sigan una distribución normal, ésto se puede representar por medio del gráfico QQ (Figura 10.5).
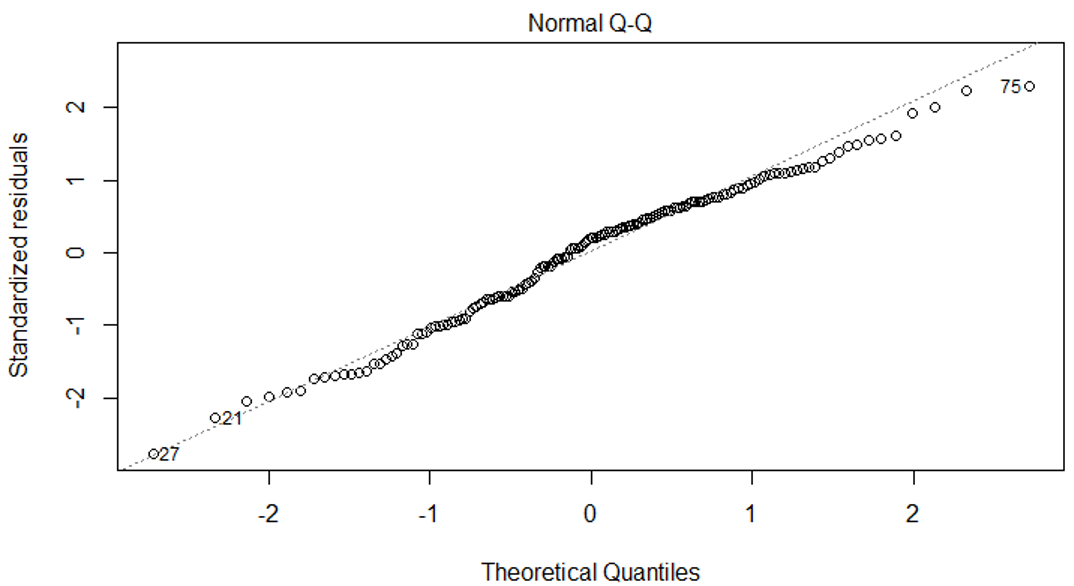
Figura 10.5: Supuesto de normalidad para un modelo de regresión. Lo ideal es que la mayoría de los puntos caigan cerca de la linea 1:1, y no hayan fuertes desviaciones.
- Homosquedasticidad (varianza constante): La idea es que los residuales y por ende el ajuste mantenga una varianza o error constante para todo el rango de valores, donde lo lo ideal es que no hayan tendencias ni formas de abanico (Figura 10.6).
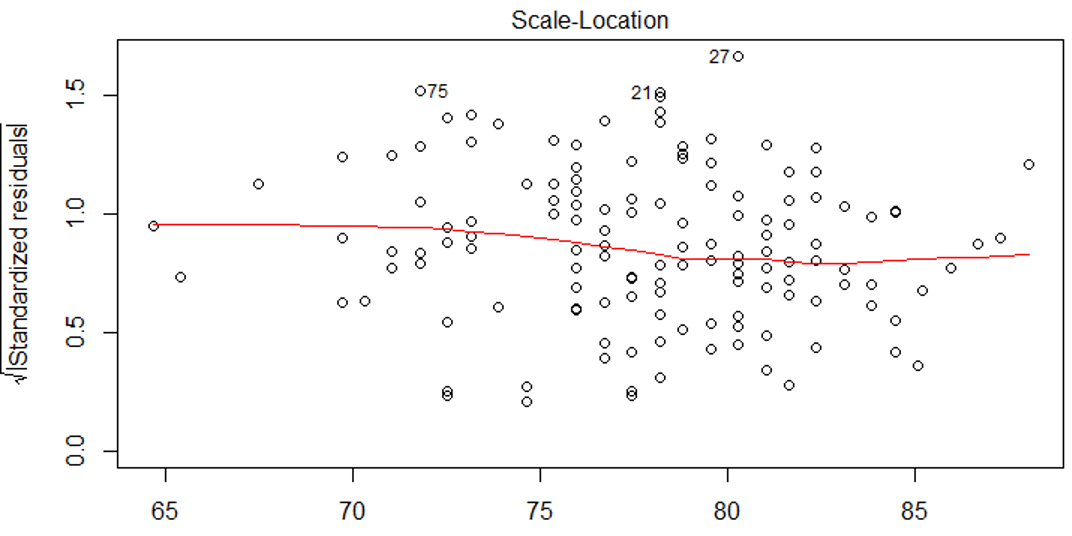
Figura 10.6: Supuesto de varianza constante para un modelo de regresión. Lo ideal es que no hayan fuertes desviaciones ni tendencias.
10.4.3 Tipos
- Lineal simple: Es la más básica, cuando se trabaja únicamente con dos variables cuantitativas continuas (Figura 10.7), y el ajuste es una línea.
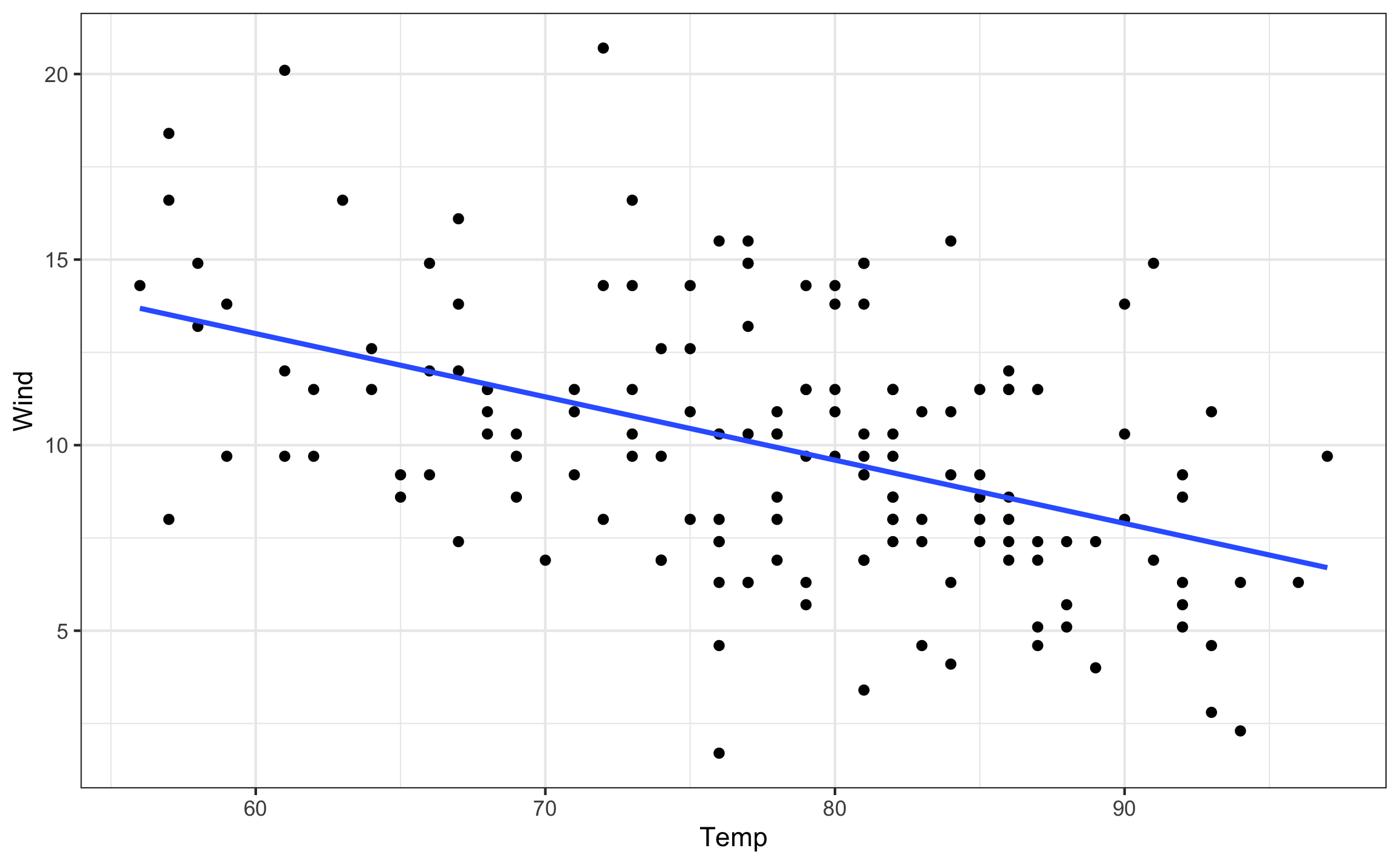
Figura 10.7: Ejemplo de regresión lineal simple.
- Lineal múltiple: Es cuando se trabaja con 3 o más variables, donde pueden ser de diferentes tipos (cualitativa o cuantitativa) (Figura 10.8), y el ajuste es un plano.
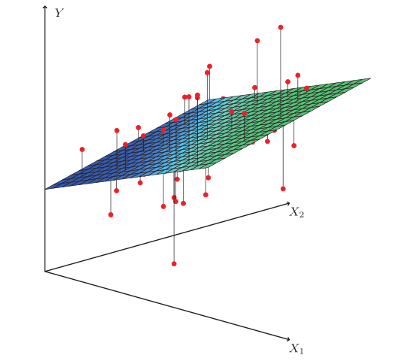
Figura 10.8: Ejemplo de regresión lineal multiple. Tomado de: https://dlegorreta.files.wordpress.com/2015/09/regression_lineal.png.
{kind=link}
- No lineal: Es cuando la relación entre las variables sigue una forma más compleja a la lineal (Figura 10.9), la cual puede ser polinomial, exponencial, potencia, logarítmica, o cualquier otro modelo o ecuación.
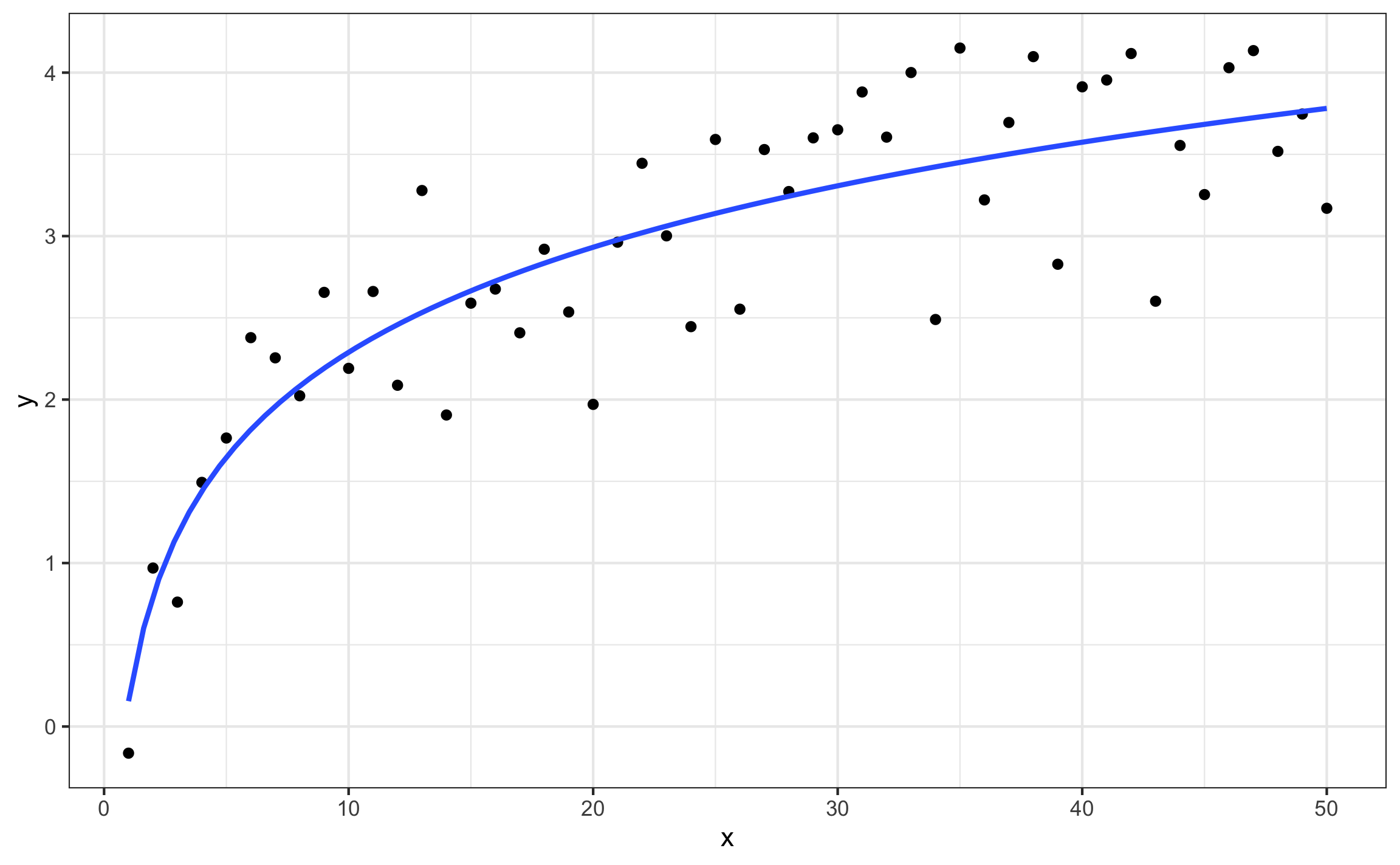
Figura 10.9: Ejemplo de regresión no lineal.
- Logística: Es cuando la variable dependiente (respuesta) es cualitativa y puede tener dos clases o niveles (regresión logística binomial), tres o más clases nominales (regresión logística multinomial), o tres o más clases ordinales (regresión logística ordinal). La regresión logística binomial es la más común (Figura 10.10). En todos estos casos el resultado se puede dar como la clase predecida, o las probabilidades de pertenencia a cada clase, donde generalmente se asigna la clase predecida a la clase con mayor probabilidad de pertenencia. Por esto el eje vertical (y) se representa como probabilidades.
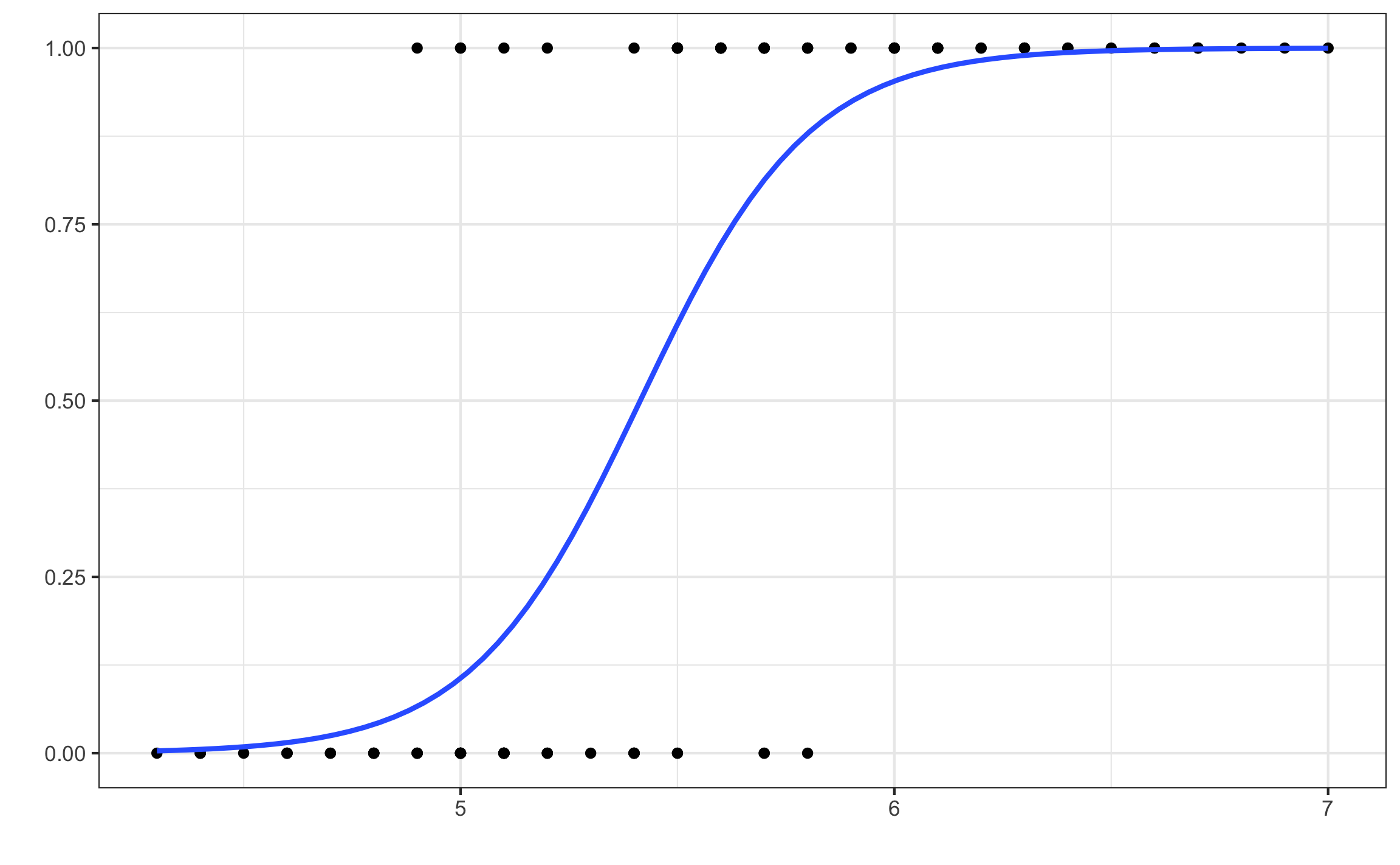
Figura 10.10: Ejemplo de regresión logística binomial.
10.4.3.1 Lineal Simple
Como se mencionó anteriormente es el tipo de regresión más básica y sencilla ya que lidia únicamente con dos variables cuantitativas continuas. Esta regresión presenta el modelo que se muestra en la Ecuación (10.4), y la forma típica de realizar el ajuste del modelo a los datos es por medio del método de mínimos cuadrados (OLS - ordinary least squares, en inglés), donde se busca minimizar el error (los residuos) en la dirección vertical (Figura 10.11).
\[\begin{equation} \hat{y} = \hat{b}_0 + \hat{b}_1 x + \epsilon \tag{10.4} \end{equation}\]
donde \(\hat{y}\) son los valores predecidos, \(\hat{b}_0\) es el intercepto, \(\hat{b}_1\) es la pendiente, \(x\) es la variable predictora, y \(\epsilon\) es el error de ajuste.
En este tipo de regresión lo más importante es la pendiente (\(\hat{b}_1\)) que representa esa relación entre las variables de cómo cambia \(y\) con respecto a \(x\), donde el valor de la pendiente indica cuanto cambia (incrementa, disminuye) \(y\) en promedio por cada unidad de incremento de \(x\). El intercepto (\(\hat{b}_0\)) por lo general no es de importancia ya que es un parámetro de ajuste y en la mayoría de las ocasiones carece de sentido práctico.
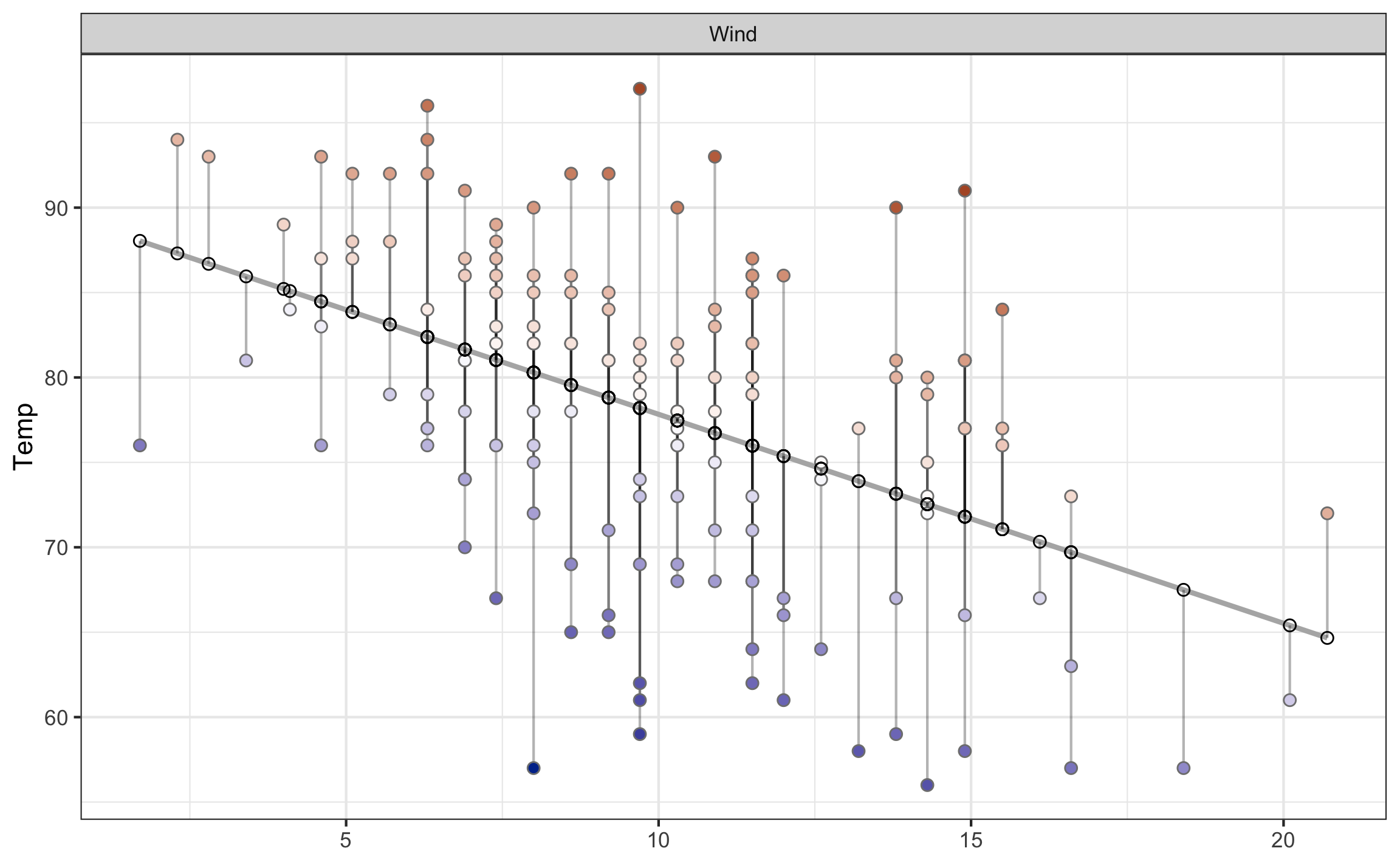
Figura 10.11: Ajuste de modelo lineal simple mostrando los errores como lineas verticales que unen los valores predecidos con los observados. Errores positivos aparecen en color rojo, y errores negativos aparecen en color azul.
Cuando la relación entre las dos variables es lineal y se tiene un modelo lineal simple se puede estimar la correlación a partir de la pendiente y viceversa, como se muestra en la Ecuación (10.5):
\[\begin{equation} r_{xy} = \hat{b}_1 \frac{s_x}{s_y}\\ \hat{b}_1 = r_{xy} \frac{s_y}{s_x} \tag{10.5} \end{equation}\]
Más adelante se va a introducir el concepto de estandarización, que es un tipo de transformación que se puede aplicar a una variable o a un modelo. En la regresión lineal simple el coeficiente de correlación, entre las variables \(x\) y \(y\), es igual a la pendiente (\(\hat{b}_1\)) estandarizada. Si se realiza una regresión lineal simple sobre variables estandarizadas la pendiente va a ser igual al coeficiente de correlación entre la variables.
En R para ajustar modelos lineales se usa a función lm, donde los argumentos son primero una formula del tipo y~x (\(y\) en función de \(x\)), y data la tabla donde se encuentran los datos. Se muestra como ejemplo al ajuste del modelo que se presenta en la Figura 10.7, que es base a un set de datos que trae R por defecto.
fit_lin = lm(Temp ~ Wind, airquality)
fit_lin %>%
tidy()## # A tibble: 2 x 5
## term estimate std.error statistic p.value
## <chr> <dbl> <dbl> <dbl> <dbl>
## 1 (Intercept) 90.1 2.05 43.9 6.69e-88
## 2 Wind -1.23 0.194 -6.33 2.64e- 9Se muestra el ajuste de la temperatura en función de la velocidad del viento, donde el modelo resultante tiene la forma \(\hat{Temp} = 90.13 - 1.23 Wind\). Este resultado se puede interpretar de la siguiente manera: por cada unidad que incrementa la velocidad del viento en millas por hora (mph), la temperatura decrece en 1.23 grados Fahrenheit. Otra interpretación podría ser que por cada 10 mph que incrementa la velocidad del viento, la temperatura decrece 12.3 grados Fahrenheit. Al multiplicar las unidades de \(x\) por un factor la pendiente se va a ver afectada por ese mismo factor, en el ejemplo anterior siendo el factor 10.
Por el momento en la tabla de resultados que se muestra únicamente es de interés el coeficiente (term) y su valor (estimate), más adelante se explicará el resto de las columnas. La función tidy del paquete broom (Robinson & Hayes, 2020) y del metapaquete tidymodels (Kuhn & Wickham, 2020) es una función que ordena el resultado del ajuste en una tabla para mayor facilidad de interpretación y manipulación.
La función parameters del paquete parameters (Lüdecke, Makowski, Ben-Shachar, et al., 2020) extrae un resumen similar al de la función tidy.
fit_lin %>%
parameters()## # A tibble: 2 x 8
## Parameter Coefficient SE CI_low CI_high t df_error p
## <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <int> <dbl>
## 1 (Intercept) 90.1 2.05 86.1 94.2 43.9 151 6.69e-88
## 2 Wind -1.23 0.194 -1.61 -0.846 -6.33 151 2.64e- 910.4.4 Medidas de ajuste y error
Una vez ajustado un modelo es importante saber la calidad del ajuste, ya que se pueden generar varios modelos y se quisiera saber cuál modelo se ajusta mejor o representa mejor los datos. Para este fin se pueden usar varias métricas.
10.4.4.1 RMSE
El Root Mean Square Error (RMSE en inglés) o error cuadrático medio (Ecuación (10.6)) mide qué tan diferentes (alejados) son los residuos de la línea de mejor ajuste. Tiene la propiedad de que se encuentra en la misma escala de la variable respuesta, por lo que va a depender de la misma. En general a menor RMSE mejor ajuste, pero esta métrica es más útil para comparar modelos.
\[\begin{equation} RMSE = \sqrt{\frac{1}{N} \sum_{i=1}^{N} \left(y_i - \hat{y}\right)^2} \tag{10.6} \end{equation}\]
10.4.4.2 Coeficiente de determinación (\(R^2\))
El coeficiente de determinación (\(R^2\)) es una métrica de ajuste estandarizada, ya que varia entre 0 y 1, donde mientras más cercano a 1 mejor el ajuste. Esta métrica se puede interpretar como el porcentaje de variación en la variable respuesta que puede ser explicado por la variable predictora. Para el caso de la regresión lineal simple (únicamente) se puede relacionar el coeficiente de determinación con el coeficiente de correlación de la siguiente manera: \(R^2 = r^2\), o lo que es lo mismo \(r = \sqrt{R^2}\).
En R hay diferentes funciones para obtener diferentes métricas de ajuste. La función glance del paquete broom extrae del modelo varias medidas de ajuste, entre ellas el \(R^2\). La función RMSE del paquete DescTools extrae el valor de esta métrica. La función performance del paquete performance (Lüdecke, Makowski, & Waggoner, 2020) extrae el \(R^2\) y \(RMSE\), entre otras medidas de ajuste.
fit_lin %>%
glance()## # A tibble: 1 x 11
## r.squared adj.r.squared sigma statistic p.value df logLik AIC BIC
## <dbl> <dbl> <dbl> <dbl> <dbl> <int> <dbl> <dbl> <dbl>
## 1 0.210 0.205 8.44 40.1 2.64e-9 2 -542. 1091. 1100.
## # … with 2 more variables: deviance <dbl>, df.residual <int>RMSE(fit_lin)## [1] 8.386689fit_lin %>%
performance()## # A tibble: 1 x 5
## AIC BIC R2 R2_adjusted RMSE
## <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 1091. 1100. 0.210 0.205 8.39Con este valor de \(R^2\) se puede estimar y corroborar el coeficiente de correlación. Tener en cuenta el signo de la pendiente, en este caso negativo, ya que el \(R^2\) siempre es positivo y la raíz siempre va a ser positiva, por lo que hay que asignarle el signo de la pendiente.
sqrt(fit_lin %>% glance() %>% pull(r.squared)) * -1## [1] -0.4579879with(airquality, cor(Temp,Wind))## [1] -0.4579879De manera similar, se puede estimar la correlación a partir de la Ecuación (10.5).
airquality %>%
select_at(vars(Temp,Wind)) %>%
map_df(sd) %>%
mutate(b1 = coef(fit_lin)[2],
r = b1 * Wind/Temp)## # A tibble: 1 x 4
## Temp Wind b1 r
## <dbl> <dbl> <dbl> <dbl>
## 1 9.47 3.52 -1.23 -0.458Referencias
Kuhn, M., & Wickham, H. (2020). tidymodels: Easily Install and Load the ’Tidymodels’ Packages. https://CRAN.R-project.org/package=tidymodels
Lüdecke, D., Makowski, D., Ben-Shachar, M. S., Patil, I., & Højsgaard, S. (2020). parameters: Processing of Model Parameters. https://CRAN.R-project.org/package=parameters
Lüdecke, D., Makowski, D., & Waggoner, P. (2020). performance: Assessment of Regression Models Performance. https://CRAN.R-project.org/package=performance
Robinson, D., & Hayes, A. (2020). broom: Convert Statistical Analysis Objects into Tidy Tibbles. https://CRAN.R-project.org/package=broom
Trauth, M. (2015). MATLAB® Recipes for Earth Sciences (4.ª ed.). Springer-Verlag Berlin Heidelberg.